ElasticSearch

1 ElasticSearch 简介
1.1 Lucene
Lucene 是一个开源、免费、高性能、纯 Java 编写的全文检索引擎,它算是开源领域最好的全文检索工具包。
在实际开发中,Lucene 几乎适用于任何需要全文检索的场景,所以 Lucene 先后发展出好多其他的语言版本,如 C++、C#、Python 等。
早在 2005 年,Lucene 就升级为 Apache 顶级开源项目。它的作者是 Doug Cutting,代表作 Hadoop。
不过需要注意的是,Lucene 只是一个全文检索工具包,并非一个完整的搜索引擎,开发者可以基于 Lucene 来开发完整的搜索引擎。比较著名的有 Solr、ElasticSearch,不过在分布式和大数据的环境下,ElasticSearch 更胜一筹。
Lucene 主要有如下特点:
- 简单
- 跨语言
- 强大的搜索引擎
- 索引速度快
- 索引文件兼容不同平台
1.2 ElasticSearch
ElasticSearch 是一个分布式、可扩展、近实时性的高性能搜索与数据分析引擎。ElasticSearch 基于 Java 编写,通过进一步封装 Lucene,将搜索的复杂性屏蔽起来,开发者只需要一套简单的 RESTful API 就可以操作全文检索。
ElasticSearch 在分布式环境下表现优异,这也是它比较受欢迎的原因之一。它支持 PB 级别的结构化或非结构化海量数据处理。
整体上来说,
ElasticSearch 的三大功能:
- 数据搜集
- 数据分析
- 数据存储
ElasticSearch 的主要特点:
- 分布式实时文件存储。
- 实时分析的分布式搜索引擎。
- 高可拓展性。
- 可插拔的插件支持。
2 ElasticSearch 各种安装
2.1 单节点安装
ElasticSearch 官网下载,ElasticSearch 支持矩阵,选择合适的版本下载:
注:ES7 需要 JDK11 及以上才能够支持,而对于 ES6 来说,JDK8 就能够支持;ES6 以下不提供内置的JDK。
将下载的文件解压,解压后的目录含义如下:
| 目录 | 含义 |
|---|---|
| modules | 依赖模块目录 |
| lib | 第三方依赖库 |
| logs | 输出日志目录 |
| plugins | 插件目录 |
| bin | 可执行文件目录 |
| config | 配置文件目录 |
| data | 数据存储目录 |
启动方式:
进入到 bin 目录下,直接执行 ./elasticsearch 启动即可。
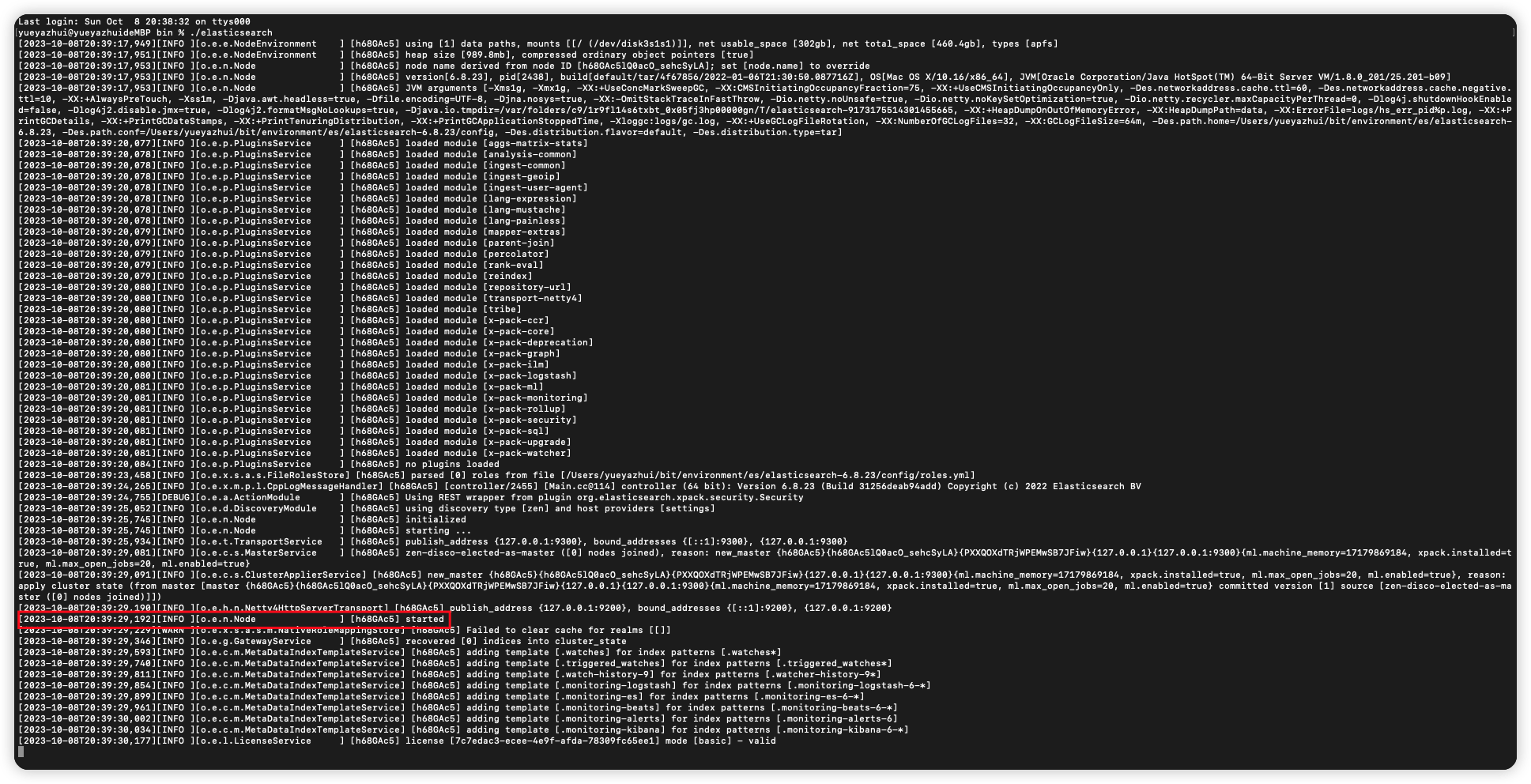
看到 started 表示启动成功。
默认端口是 9200,浏览器输入 http://localhost:9200 可以查看节点信息。
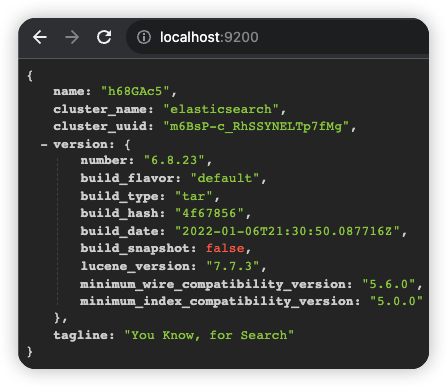
节点的名字以及集群(默认是 elasticsearch)的名字,都是可以自定义配置的。
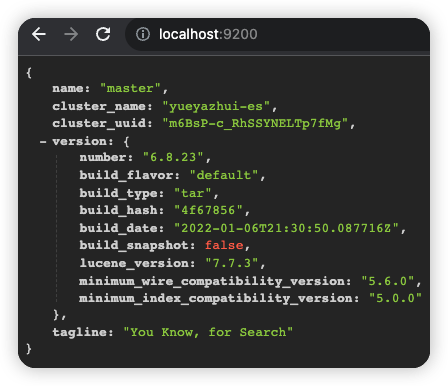
打开 config/elasticsearch.yml 文件,可以配置集群名称以及节点名称。配置方式如下:
1
2
cluster.name: yueyazhui-es
node.name: master
配置完成后,保存配置文件,并重启 es。重启成功后,刷新浏览器 http://localhost:9200 页面,就可以看到最新信息。
2.2 HEAD 插件安装
Elasticsearch Head 插件,可以通过可视化的方式查看集群信息。
2.2.1 浏览器插件安装
在 Chrome 应用商店 搜索 Elasticsearch Head,点击安装即可。


2.2.2 下载安装
git clone https://github.com/mobz/elasticsearch-head.gitcd elasticsearch-headnpm installnpm run startopenhttp://localhost:9100/
启动成功,页面如下:

注意,此时是看不到集群数据的。因为这里是通过跨域来请求集群数据的;默认情况下,集群是不支持跨域的。
解决方法:修改 es 的 config/elasticsearch.yml 配置文件,添加如下内容,使之支持跨域:
1
2
http.cors.enabled: true
http.cors.allow-origin: "*"
配置完成后,重启 es,此时 head 上就有数据了。

2.2.3 Docker 安装
1
2
sudo docker pull mobz/elasticsearch-head:5
sudo docker run -d --name elasticsearch-head -p 9100:9100 mobz/elasticsearch-head:5
2.3 分布式安装
假设:
- 一主二从
- master 的端口是 9200,slave 端口分别是 9201 和 9202
首先修改 master 的 config/elasticsearch.yml 配置文件:
1
2
node.master: true
network.host: 127.0.0.1
配置完成后,重启 master。
将 es 的压缩包解压两份,分别命名为 slave01 和 slave02,代表两个从机。
分别对其进行配置。
slave01/config/elasticsearch.yml:
1
2
3
4
5
6
# 集群名称必须保持一致
cluster.name: yueyazhui-es
node.name: slave01
network.host: 127.0.0.1
http.port: 9201
discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
slave02/config/elasticsearch.yml:
1
2
3
4
5
6
# 集群名称必须保持一致
cluster.name: yueyazhui-es
node.name: slave02
network.host: 127.0.0.1
http.port: 9202
discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
然后分别启动 slave01 和 slave02。启动成功后,可以在 head 插件上查看集群信息。
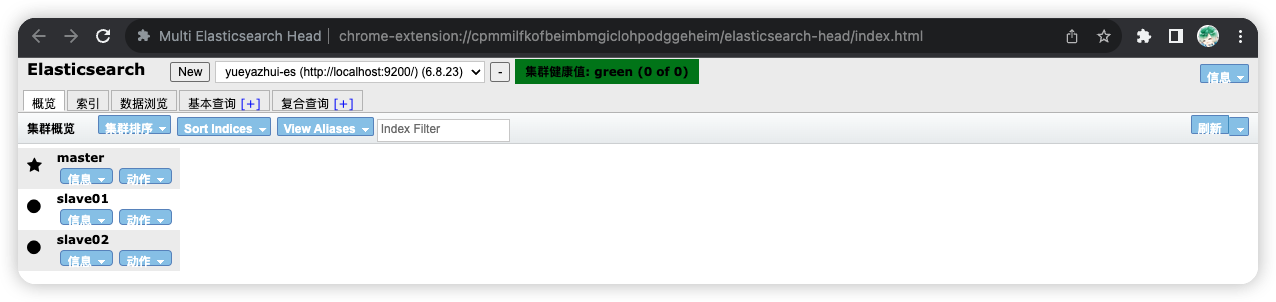
2.4 Kibana 安装
Kibana 是 Elastic 公司推出的一个针对 ES 分析以及数据可视化平台,可以搜索、查看存放在 ES 中的数据。
安装步骤如下:
- Kibana 官网下载
- 解压
- 配置 ES 的地址信息(可选,如果 ES 是默认地址以及默认端口,则不用配置;配置文件 ./config/kibana.yml)
- 执行 ./bin/kibana 文件启动
- http://localhost:5601
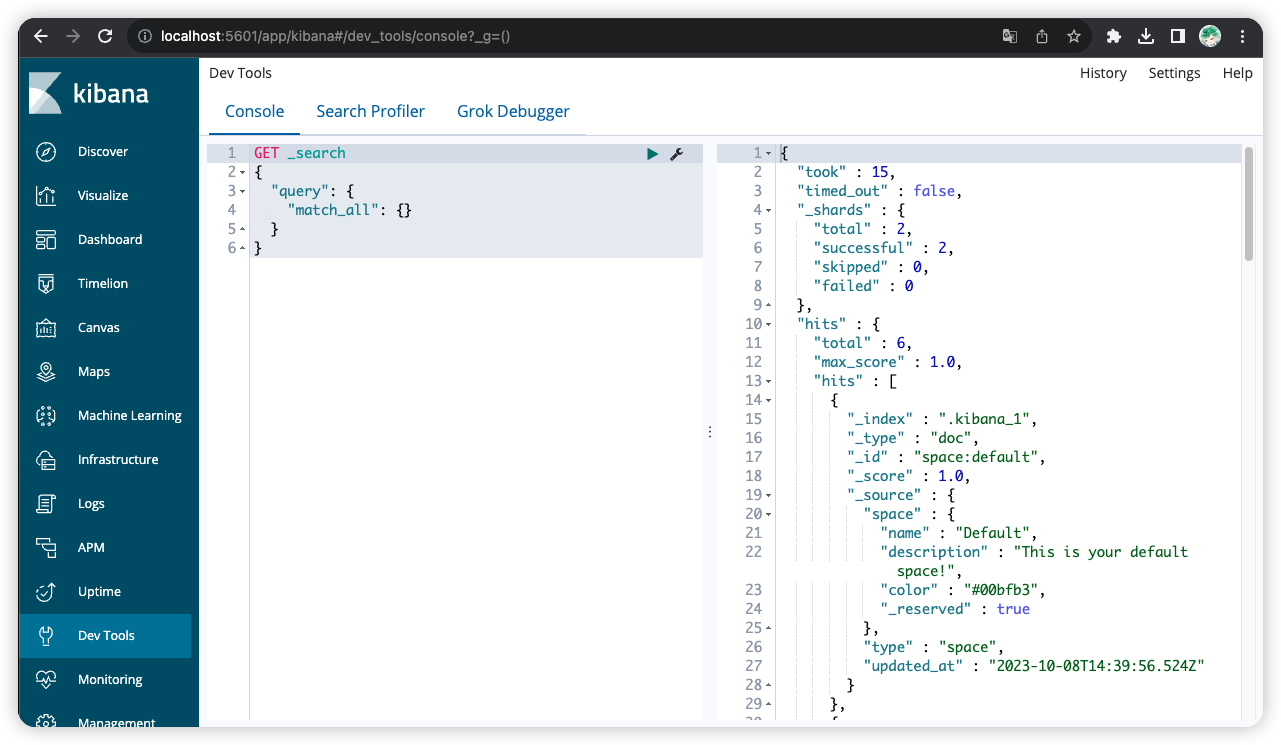
3 ElasticSearch 核心概念
3.1 ElasticSearch 十大核心概念
3.1.1 集群(Cluster)
一个或者多个安装了 ES 节点的服务器组织在一起,就是集群,这些节点共同持有数据,共同提供搜索服务。
一个集群有一个名字,这个名字是集群的唯一标识,该名字成为 cluster name,默认的集群名称是 elasticsearch,具有相同名称的节点才会组成一个集群。
可以在 config/elasticsearch.yml 文件中配置集群名称:
1
cluster.name: yueyazhui-es
在集群中,节点的状态有三种:绿色、黄色、红色:
- 绿色:节点运行状态为健康状态;所有的主分片、副本分片都可以正常工作。
- 黄色:节点运行状态为警告状态;所有的主分片目前都可以正常工作,但是至少有一个副本分片是不能正常工作的。
- 红色:集群无法正常工作。
3.1.2 节点(Node)
集群中的一个服务器就是一个节点,节点中会存储数据,同时参与集群的索引以及搜索功能。一个节点想要加入一个集群,只需要配置一下集群名称即可。默认情况下,如果启动了多个节点,多个节点还能够互相发现彼此,那么它们会自动组成一个集群,这是 ES 默认提供的,但是这种方式并不可靠,有可能会发生脑裂现象。所以在实际使用中,建议一定要手动配置一下集群信息。
3.1.3 索引(Index)
索引可以从两方面来理解:
名词
具有相似特征文档的集合。
动词
索引数据以及对数据进行索引操作。
3.1.4 类型(Type)
类型是索引上的逻辑分类或者分区。在 ES6 之前,一个索引中可以有多个类型,从 ES7 开始,一个索引中,只能有一个类型。在 ES6.x 中,依然保持了兼容,依然支持单 Index 多个 Type 结构,但是已经不建议这么使用。
3.1.5 文档(Document)
一个可以被索引的数据单元。例如一个用户的文档、一个产品的文档等等。文档都是 JSON 格式的。
3.1.6 分片(Shards)
索引都是存储在节点上的,但是受限于节点的空间大小以及数据处理能力,单个节点的处理效果可能不理想,此时可以对索引进行分片。当创建一个索引时,就需要指定分片的数量。每个分片本身也是一个功能完善并且独立的索引。
默认情况下,一个索引会自动创建 5 个分片,并且为每一个分片创建一个副本。
3.1.7 副本(Replicas)
副本也就是备份,是对主分片的一个备份。
3.1.8 Settings
集群中对索引的定义信息,例如索引的分片数、副本数等等。
3.1.9 映射(Mapping)
Mapping 保存了定义索引字段的存储类型、分词方式、是否存储等信息。
3.1.10 分词器(Analyzer)
字段分词方式的定义。
3.2 ElasticSearch Vs 关系型数据库
| 关系型数据库 | ElasticSearch |
|---|---|
| 数据库 | 索引 |
| 表 | 类型 |
| 行 | 文档 |
| 列 | 字段 |
| 表结构 | 映射 |
| SQL | DSL(Domain Specific Language) |
| select * from xxx | GET http:// |
| update xxx set xxx=xxx | PUT http:// |
| delete xxx | DELETE http:// |
| 索引 | 全文索引 |
4 ElasticSearch 分词器
4.1 内置分词器
ElasticSearch 核心功能就是数据检索,首先通过索引将文档写入 ES。查询分析则主要分为两个步骤:
- 词条化:分词器将输入的文本转为一个一个的词条流。
- 过滤:比如停用词过滤器会从词条中去除不相干的词条(的,嗯,啊,呢);另外还有同义词过滤器、小写过滤器等。
ElasticSearch 中内置了多种分词器可以供使用。
内置分词器:
| 分词器 | 作用 |
|---|---|
| Standard Analyzer | 标准分词器,适用于英语等。 |
| Simple Analyzer | 简单分词器,基于非字母字符进行分词,单词会被转为小写字母。 |
| Whitespace Analyzer | 空格分词器。按照空格进行切分。 |
| Stop Analyzer | 类似于简单分词器,但增加了停用词的功能。 |
| Keyword Analyzer | 关键词分词器,输入文本等于输出文本。 |
| Pattern Analyzer | 利用正则表达式对文本进行切分,支持停用词。 |
| Language Analyzer | 针对特定语言的分词器。 |
| Fingerprint Analyzer | 指纹分析仪分词器,通过创建标记进行重复检测。 |
4.2 中文分词器
在 ES 中,使用较多的中文分词器是 elasticsearch-analysis-ik,这个是 ES 的一个第三方插件,代码托管在 GitHub 上:
- https://github.com/medcl/elasticsearch-analysis-ik
4.2.1 安装
两种使用方式:
第一种:
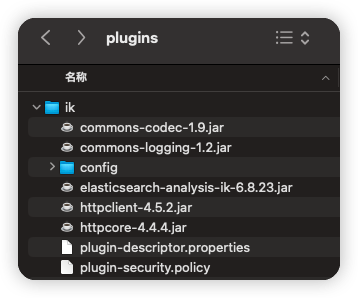
- 在 https://github.com/medcl/elasticsearch-analysis-ik/releases 页面找到与 ES 版本相对应的分词器版本,下载解压。例如:https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.8.23/elasticsearch-analysis-ik-6.8.23.zip。
- 在 es/plugins 目录下,新建 ik 目录,并将解压后的所有文件拷贝到 ik 目录下。
- 重启 ES 服务。
第二种:
1
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.8.23/elasticsearch-analysis-ik-6.8.23.zip
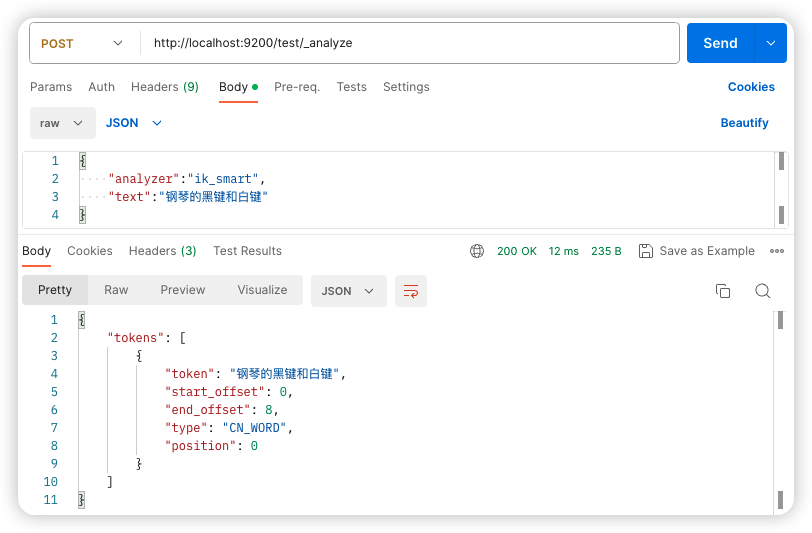
4.2.2 测试
ES 重启成功后,首先创建一个名为 test 的索引:
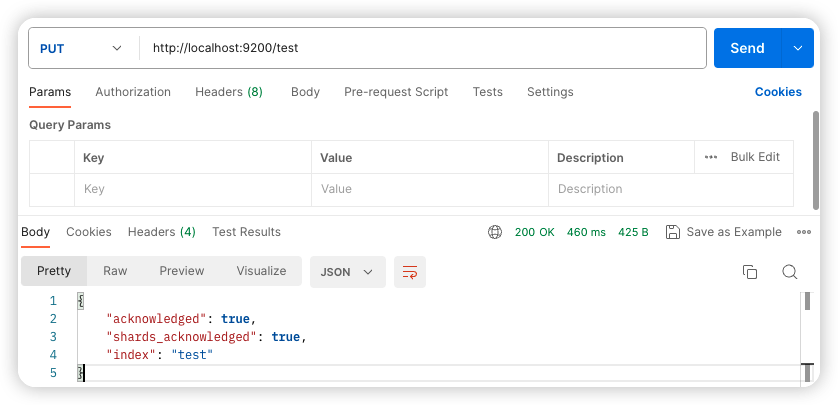
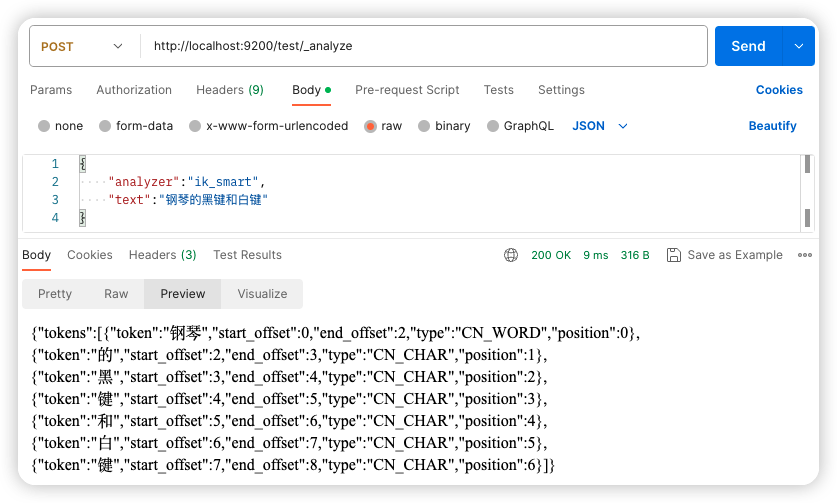
接下来,在该索引中进行分词测试:
4.2.3 自定义扩展词库
4.2.3.1 本地自定义
在 es/plugins/ik/config 目录下,新建 yueyazhui.dic 文件(文件名任意),在该文件中可以配置自定义的词库。

如果有多个词,换行写入即可。
然后在 es/plugins/ik/config/IKAnalyzer.cfg.xml 中配置扩展字典的位置:
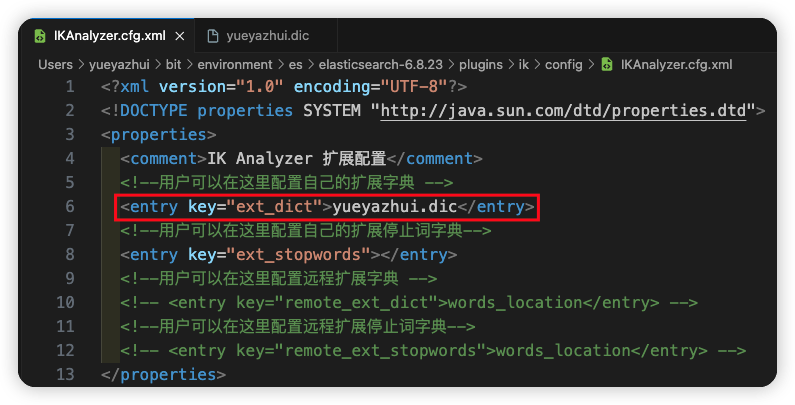
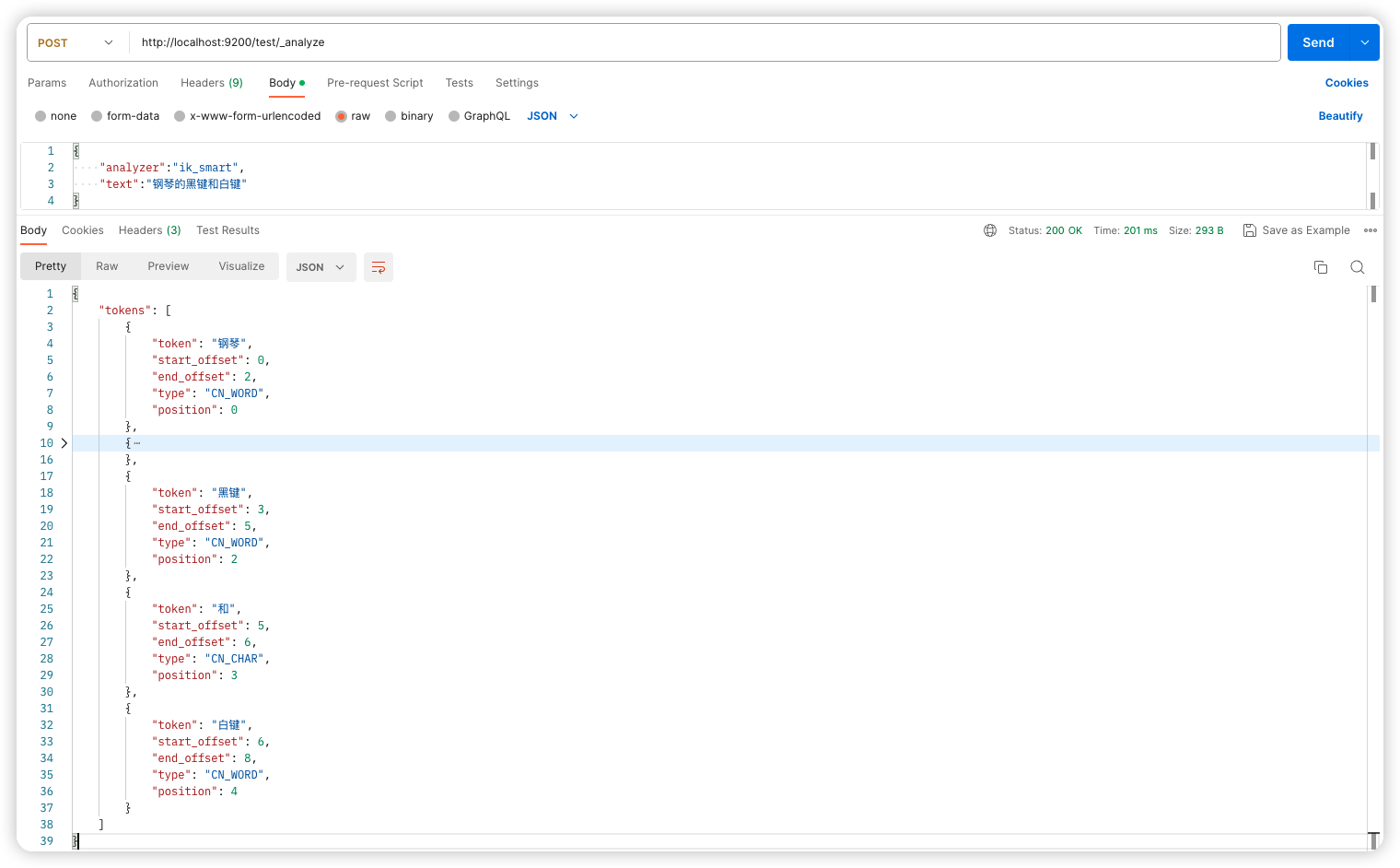
重启 ES,进行测试
4.2.3.2 远程词库
也可以配置远程词库,远程词库支持热更新(不用重启 ES 就可以生效)。
热更新只需要提供一个接口,接口返回扩展词即可。
具体使用方式如下,新建一个 Spring Boot 项目,引入 Web 依赖即可。然后在 resources/stastic 目录下新建 yueyazhui.dic 文件,写入扩展词:
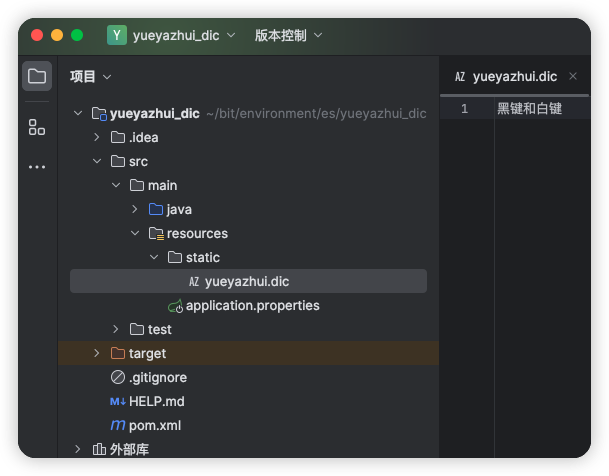
接下来,在 es/plugins/ik/config/IKAnalyzer.cfg.xml 文件中配置远程扩展字典接口:
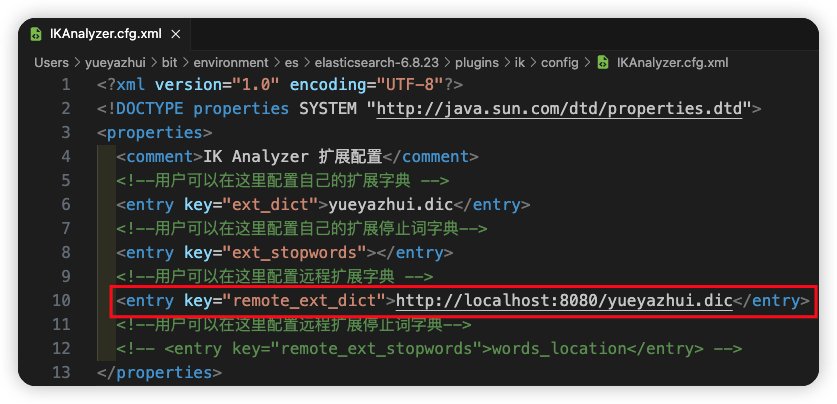
配置完成后,重启 ES ,即可生效。
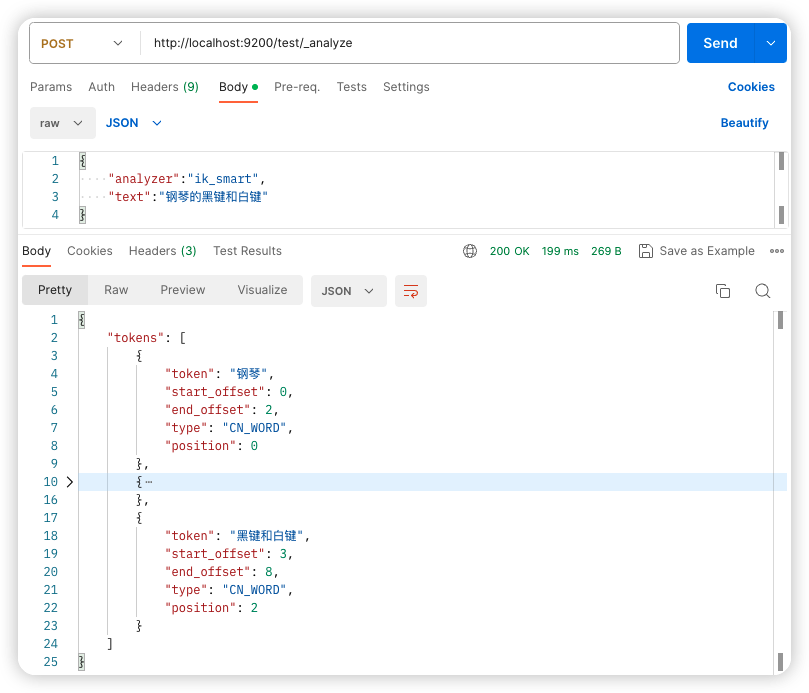
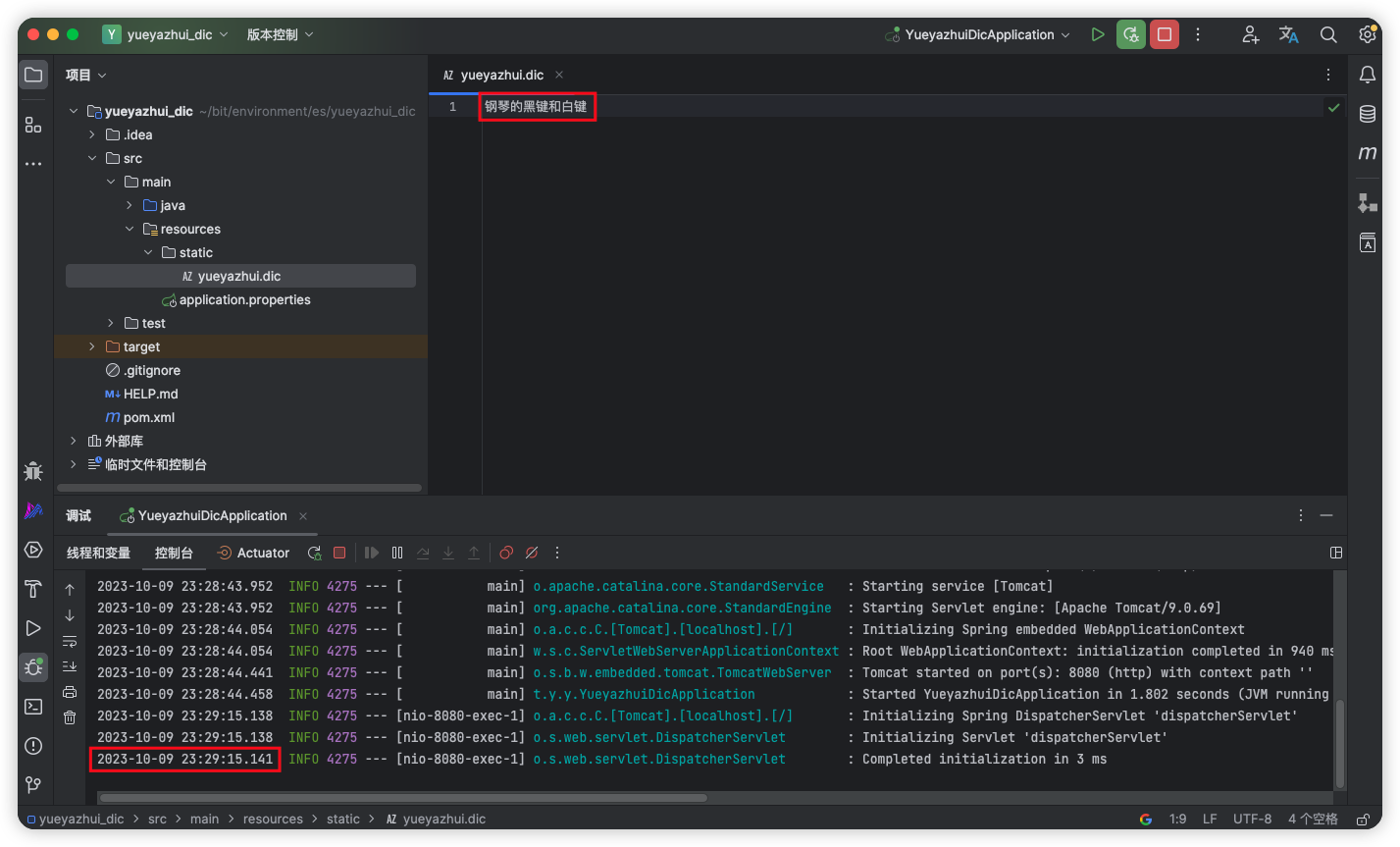
热更新,主要是响应头的 Last-Modified 或者 ETag 字段发生变化,ik 就会自动重新加载远程扩展字典。
热更新的延迟大概有 30 秒左右。

5 ElasticSearch 索引基本操作
5.1 新建索引
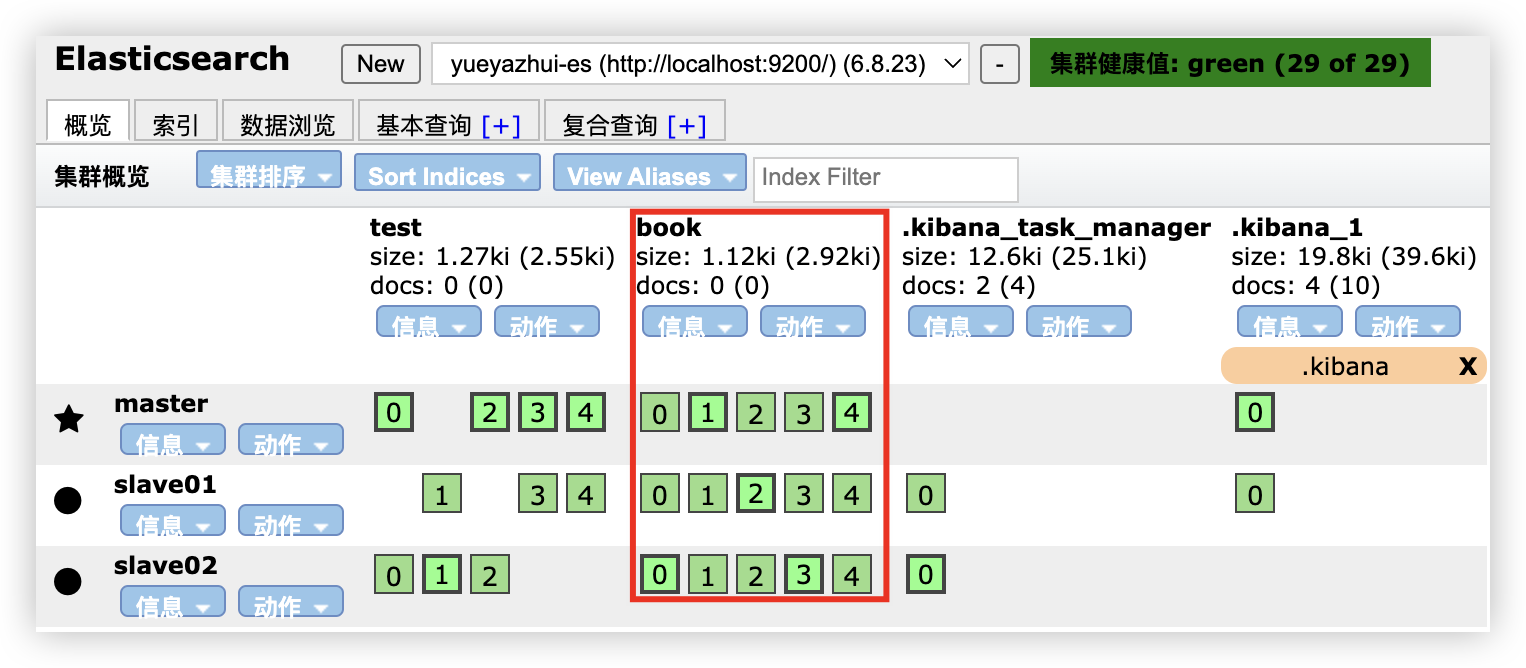
5.1.1 通过 head 插件新建索引
在 head 插件中,选择 索引 选项卡,然后点击新建索引。新建索引时,需要填入索引名称、分片数以及副本数。
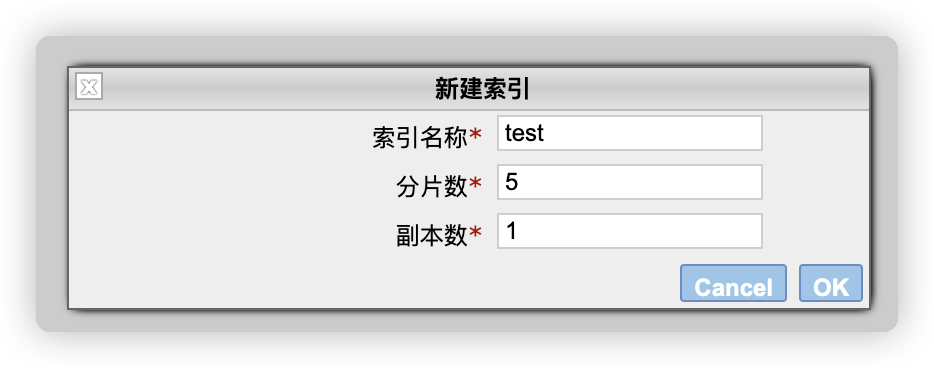
索引创建成功后,如下图:
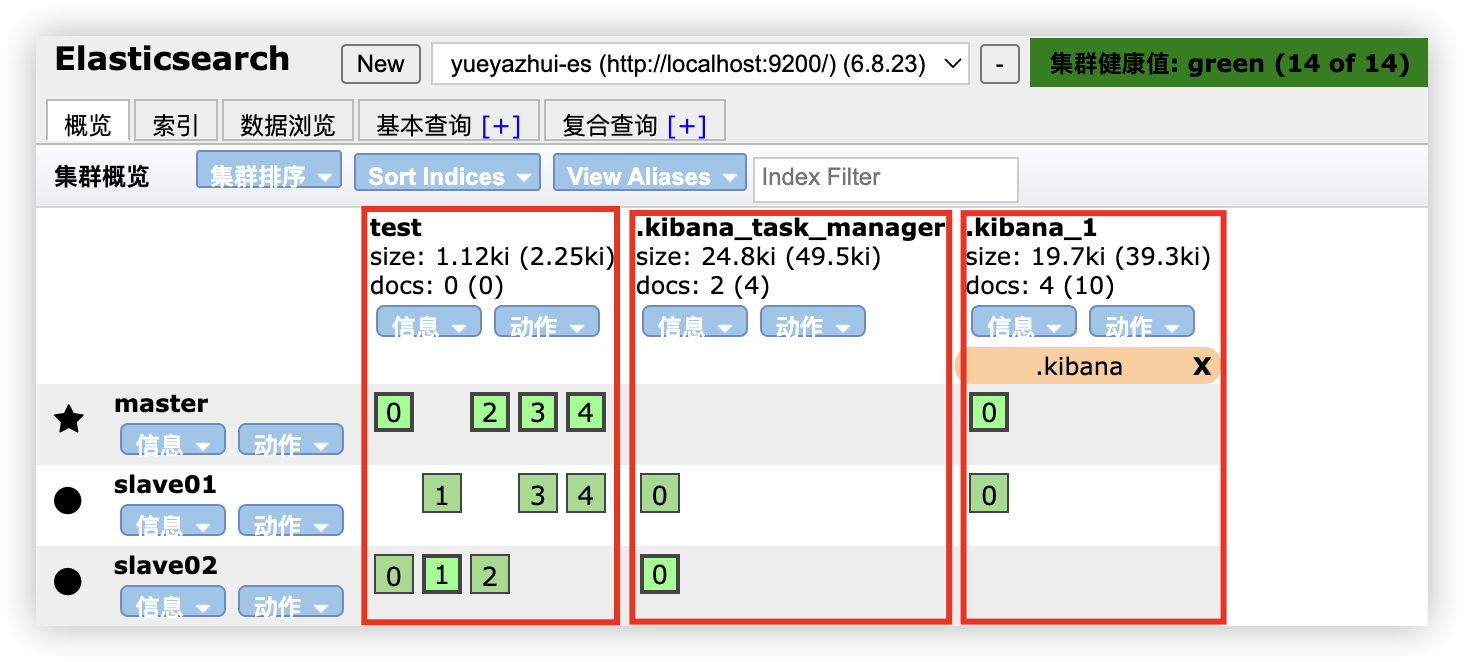
0、1、2、3、4 分别表示索引的分片,粗框表示主分片,细框表示副本(点击框,展示详情,通过 primary 属性可以查看是主分片还是副本)。.kibana 索引只有一个分片和一个副本,所以只有 0。
5.1.2 通过请求创建
可以通过 postman 发送请求,也可以通过 kibana 发送请求,由于 kibana 有提示,所以这里采用 kibana。
创建索引请求:
- 直接创建;在 ES6 之前(包括ES6),默认创建的索引有 5 个分片,但从 ES7 开始,默认创建的索引只有 1 个分片
1
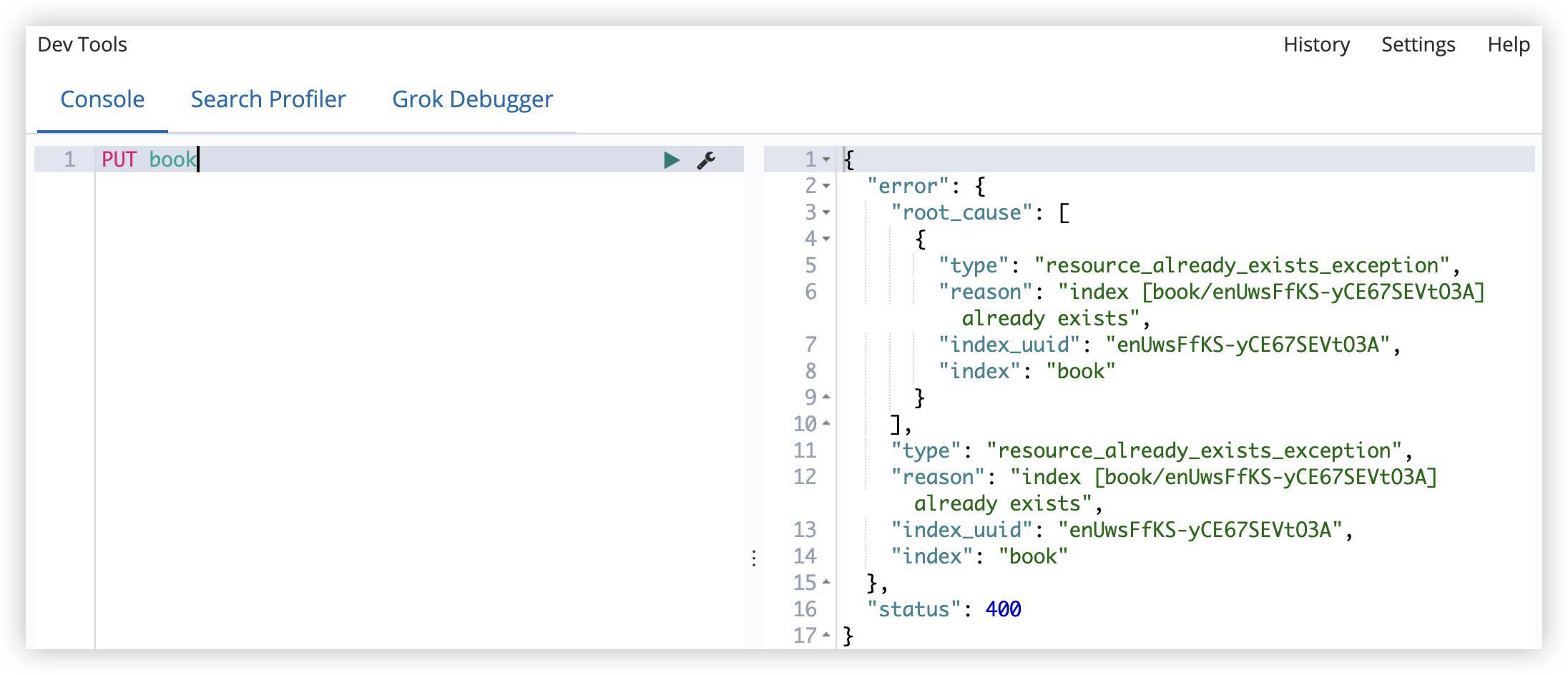
PUT book
- 设置分片数和副本数创建(建议)
1
2
3
4
5
6
7
8
PUT book
{
"settings":
{
"number_of_shards": 5,
"number_of_replicas": 1
}
}
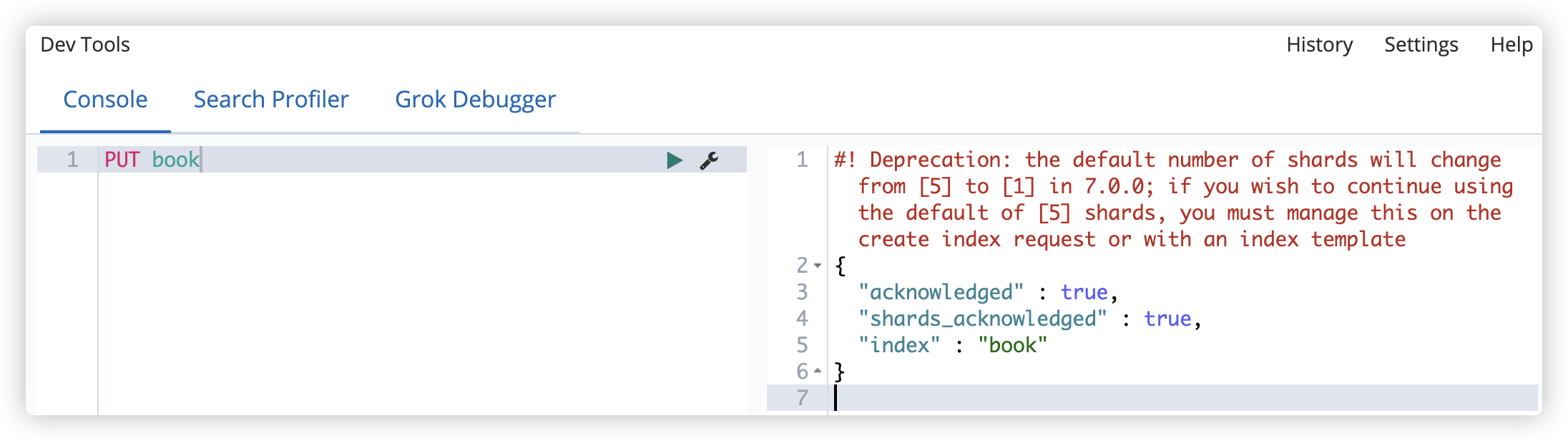
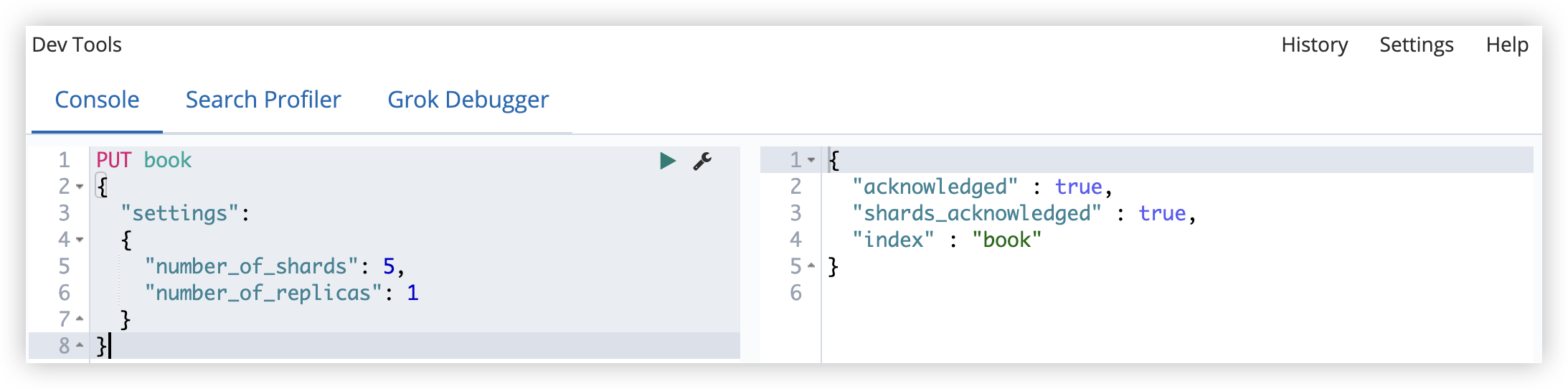
创建成功后,可以查看索引信息:
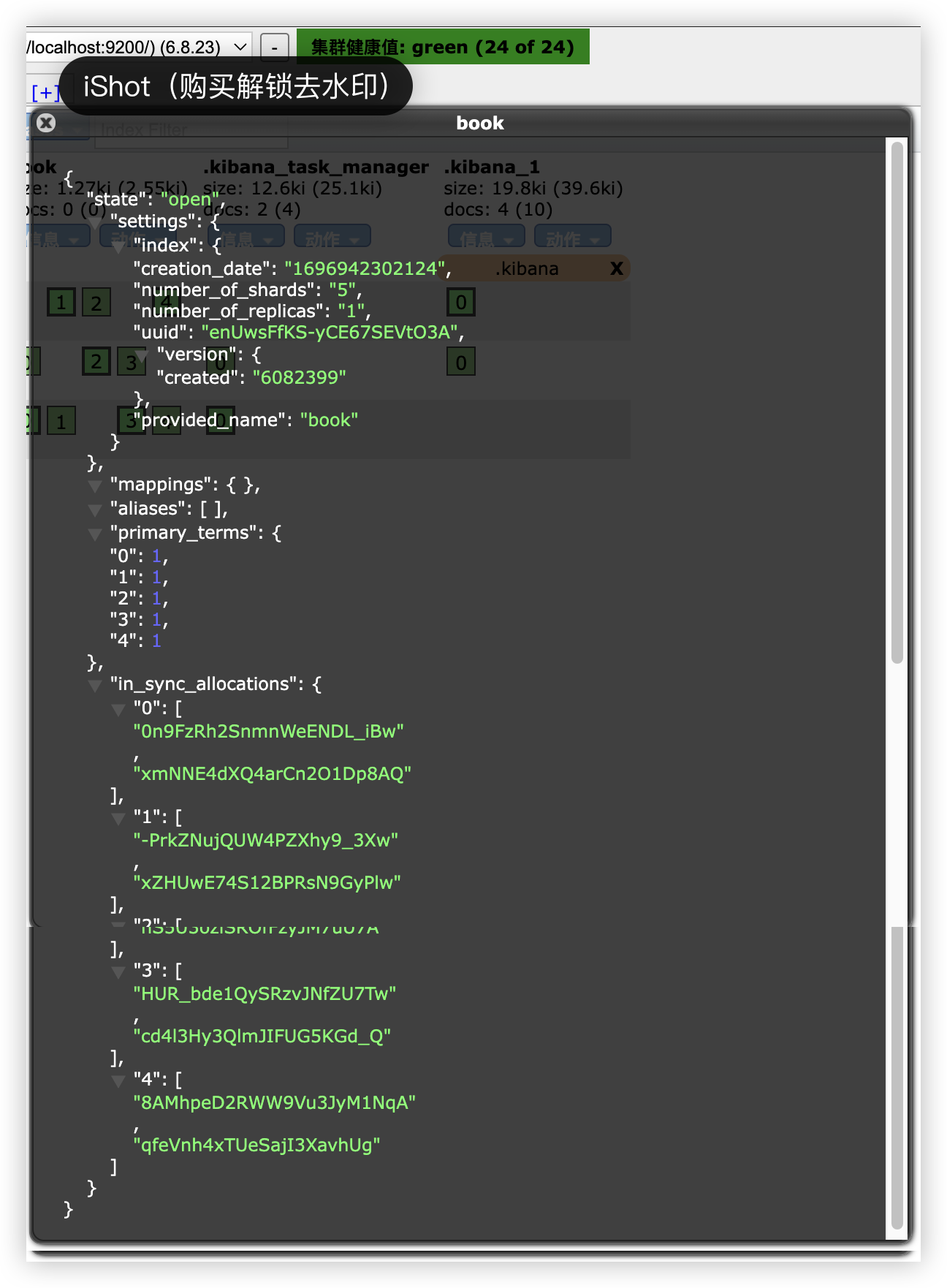
需要注意以下几点:
- 创建后分片数不能修改
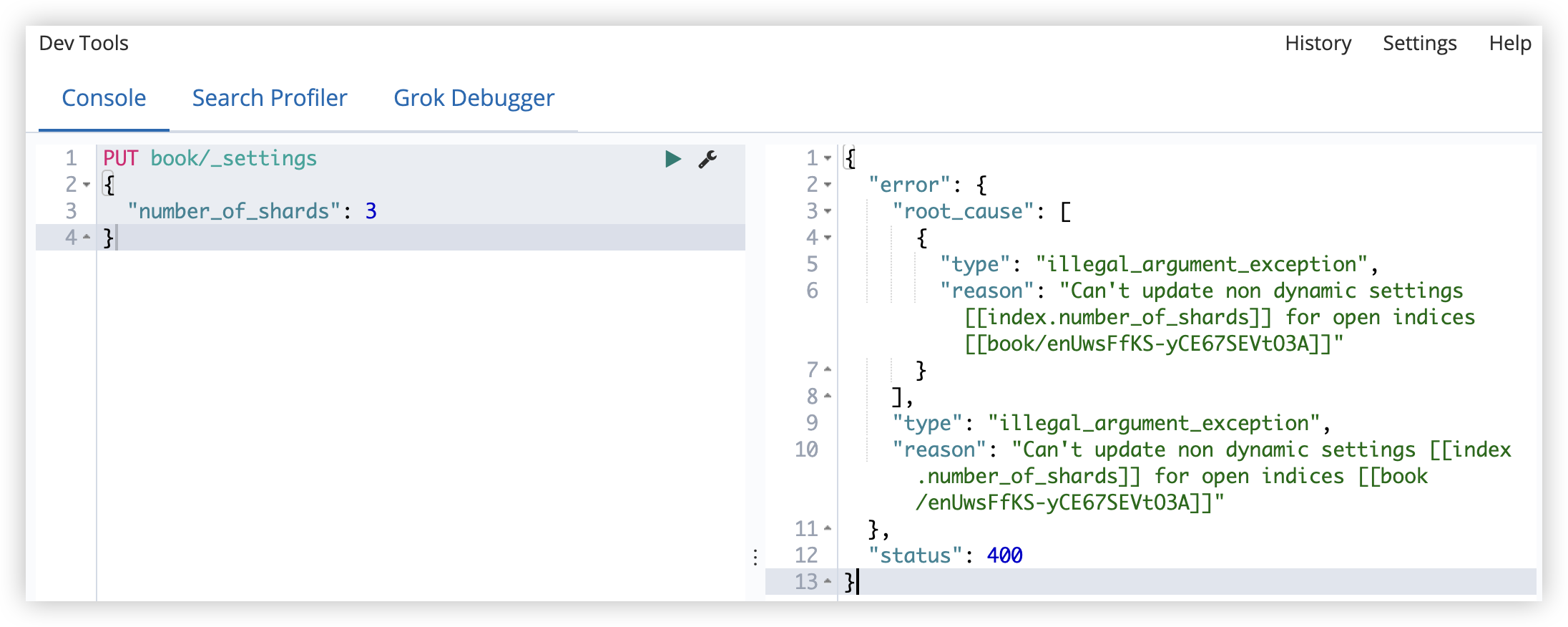
- 索引名称不能有大写字母
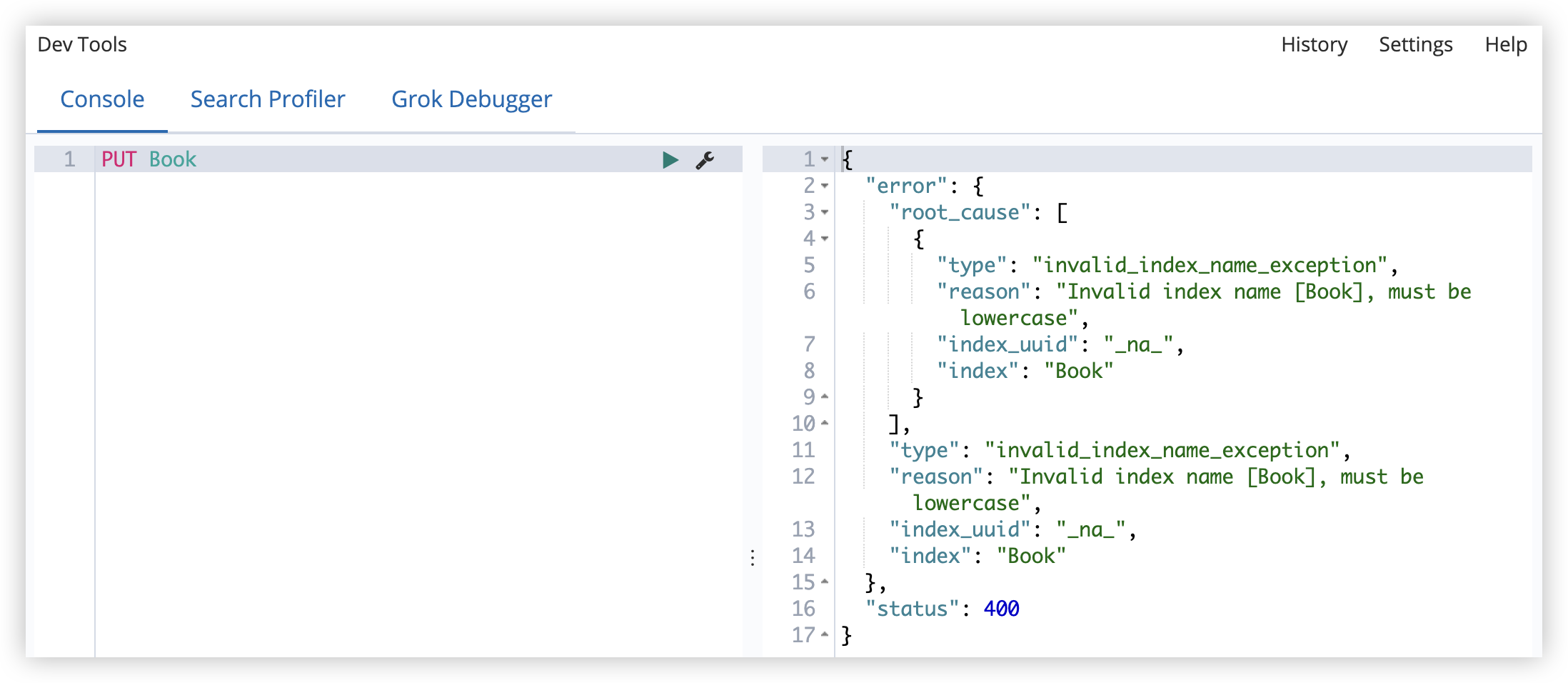
- 索引名是唯一的,不能重复
5.2 更新索引
索引创建好之后,可以修改其属性。
修改索引的副本数:
1
2
3
4
PUT book/_settings
{
"number_of_replicas": 2
}
修改成功后,如下:
5.3 修改索引的读写权限
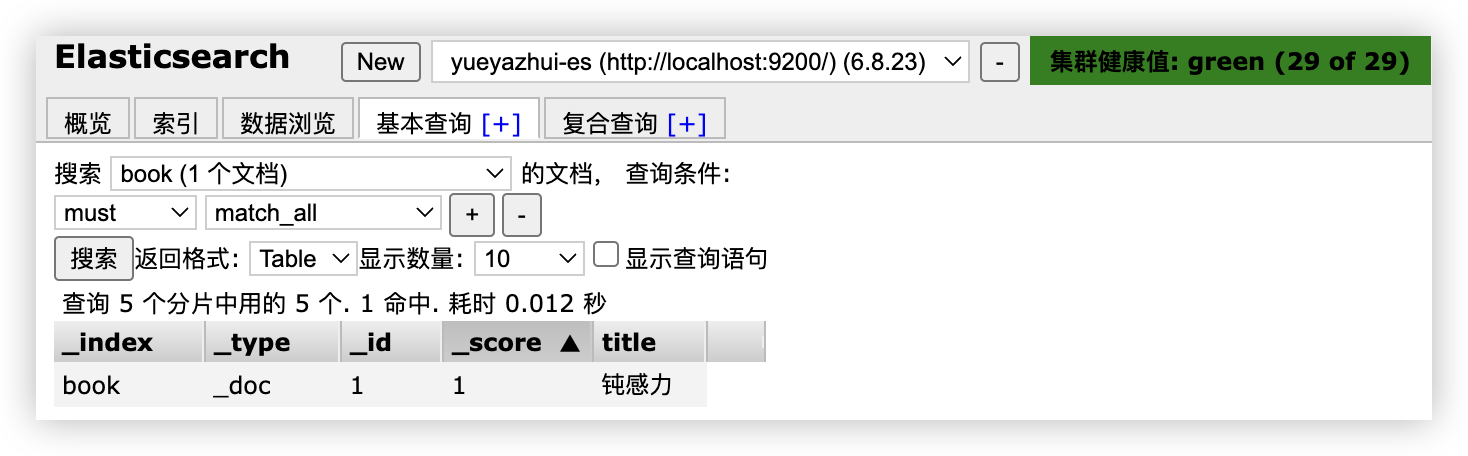
索引创建成功后,可以向索引中写入文档:(_doc为类型)
1
2
3
4
PUT book/_doc/1
{
"title":"钝感力"
}

写入成功后,可以在 head 插件中查看:
默认情况下,索引是具备读写权限的,当然这个读写权限可以关闭。
关闭索引的写权限:
1
2
3
4
PUT book/_settings
{
"blocks.write": true
}
关闭之后,就无法对文档进行写操作了
打开索引的写权限:
1
2
3
4
PUT book/_settings
{
"blocks.write": false
}
其他类似的权限:
- blocks.write
- blocks.read
- blocks.read_only
5.4 查看索引
head 插件查看方式如下:
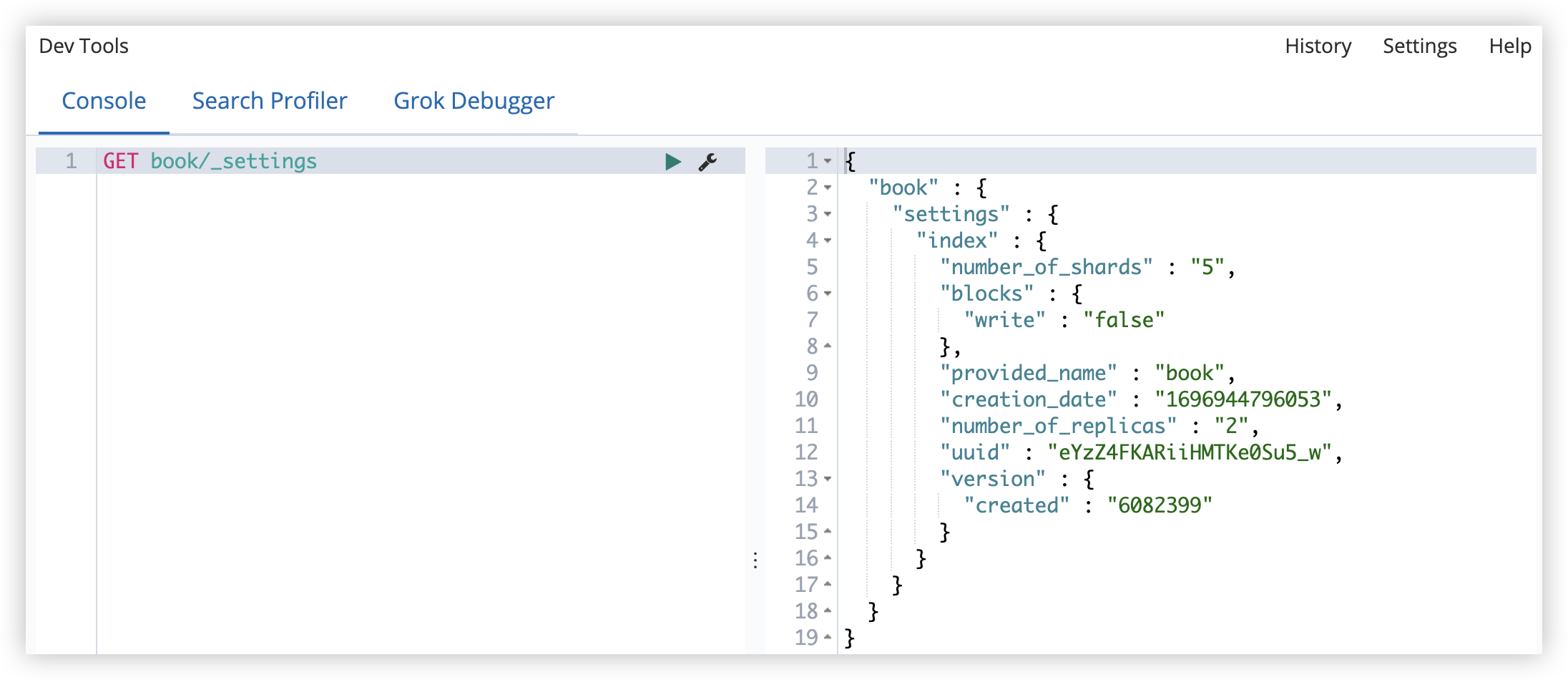
请求查看方式如下:
1
GET book/_settings
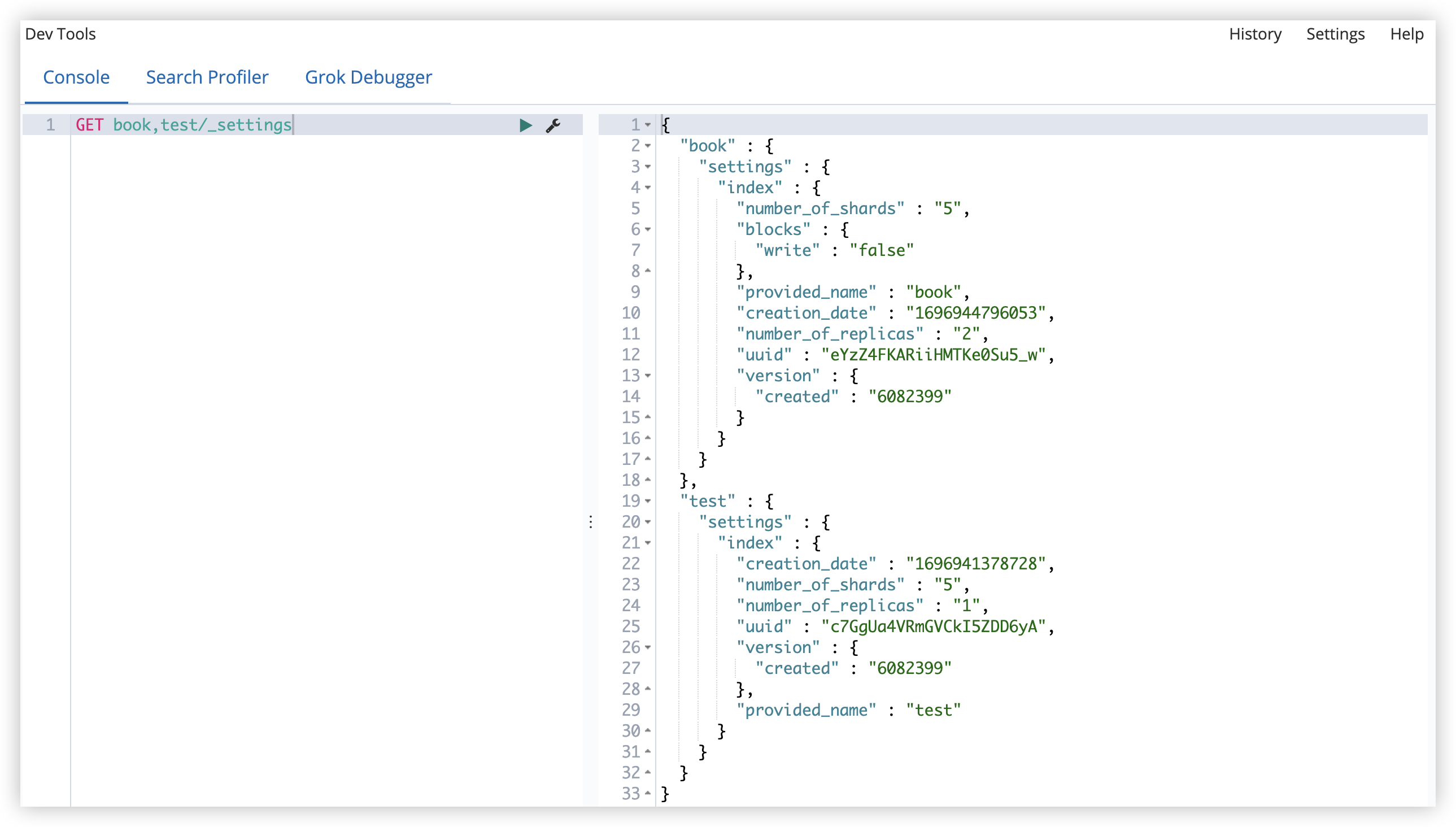
可以同时查看多个索引信息:
1
GET book,test/_settings
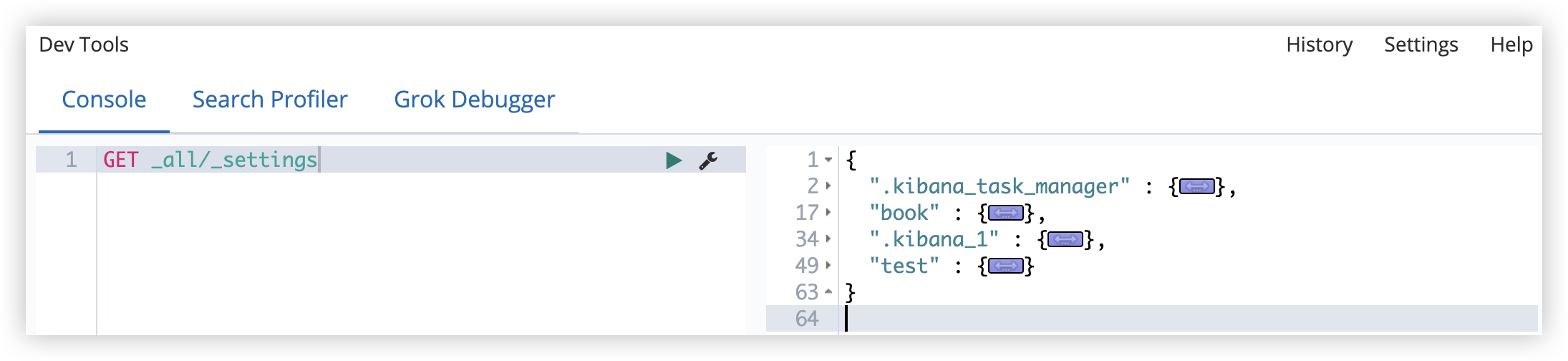
也可以查看所有索引信息:
1
GET _all/_settings
5.5 删除索引
head 插件可以删除索引:
请求删除如下:
1
DELETE test
删除一个不存在的索引会报错。
5.6 索引打开/关闭
关闭索引:
1
POST book/_close
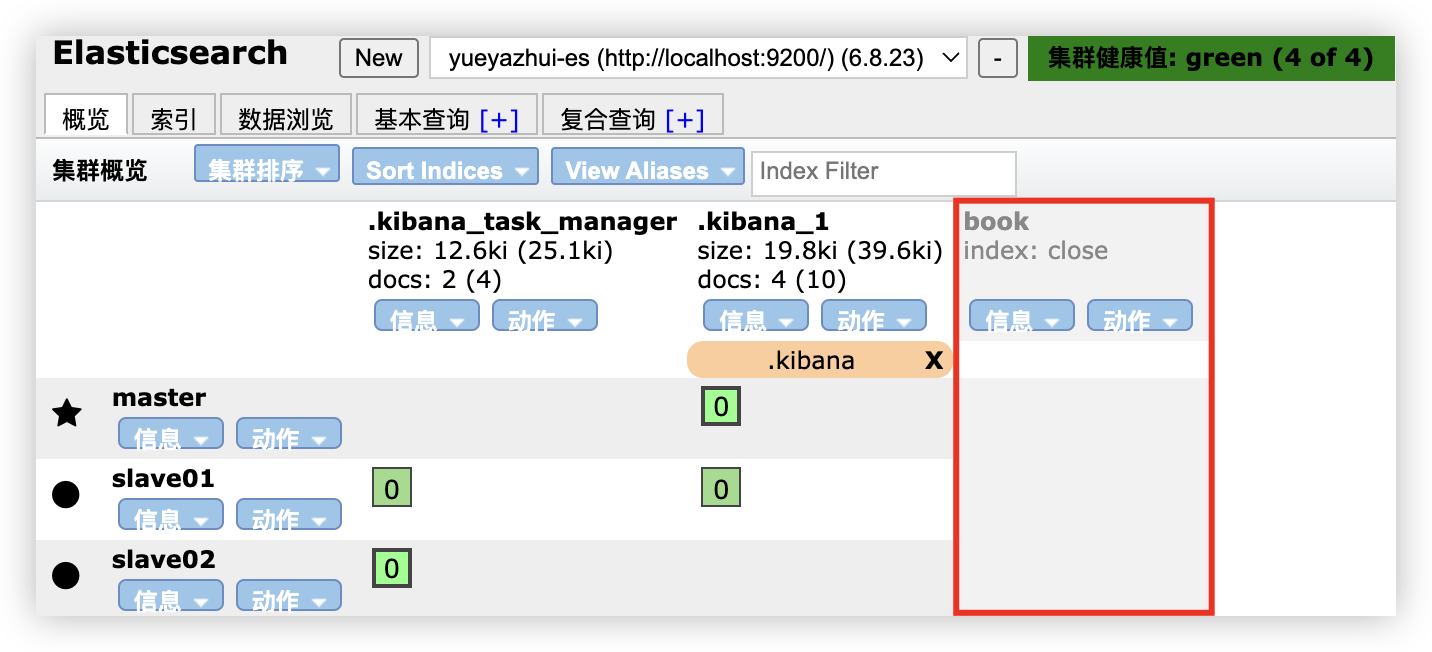
打开索引:
1
POST book/_open
当然,也可以同时打开/关闭多个索引,多个索引用,隔开,或者直接使用_all代表所有索引。
5.7 复制索引
索引复制,只会复制数据,不会复制索引配置。
1
2
3
4
5
POST _reindex
{
"source": {"index": "book"},
"dest": {"index": "book_new"}
}
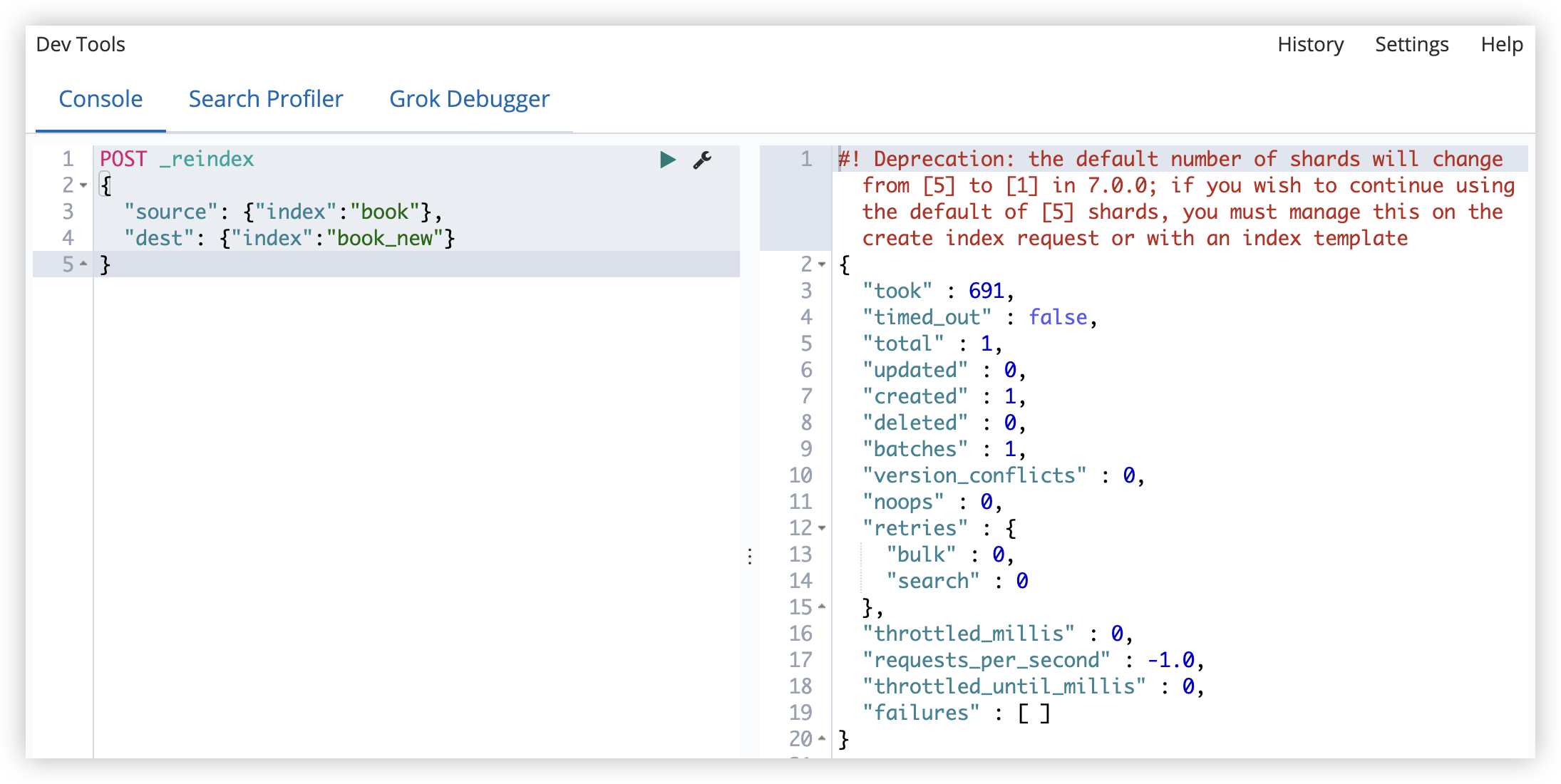
复制的时候,可以添加查询条件。
5.8 索引别名
可以为索引创建别名,如果这个别名是唯一的,该别名可以代替索引名称。
1
2
3
4
5
6
7
8
9
10
11
POST /_aliases
{
"actions": [
{
"add": {
"index": "book",
"alias": "book_alias"
}
}
]
}
创建结果如下:

将 add 改为 remove 就表示移除别名:
1
2
3
4
5
6
7
8
9
10
11
POST /_aliases
{
"actions": [
{
"remove": {
"index": "book",
"alias": "book_alias"
}
}
]
}
查看某一个索引的别名:
1
GET /book/_alias
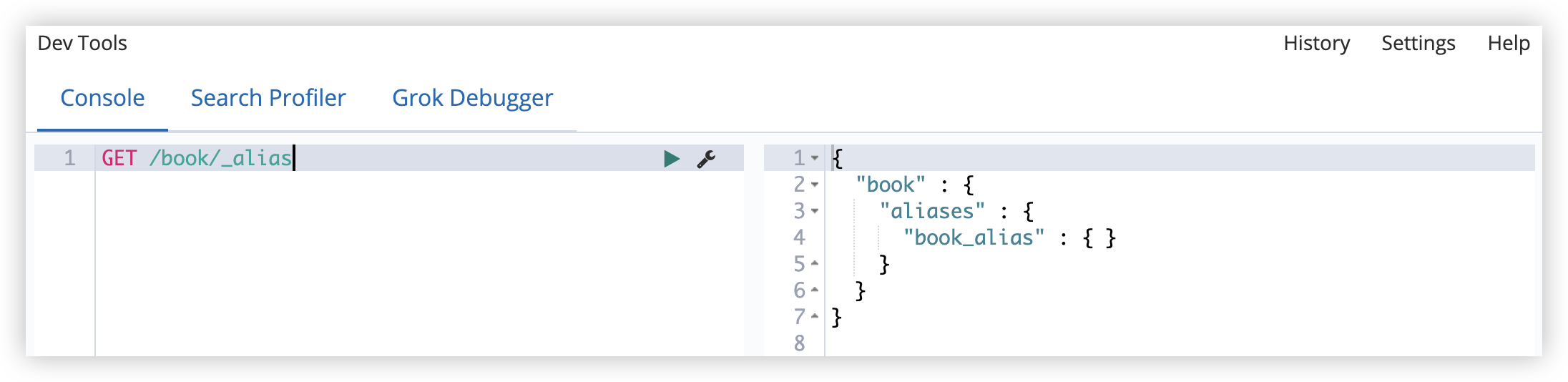
查看某一个别名对应的索引(book_alias 表示一个别名):
1
GET /book_alias/_alias
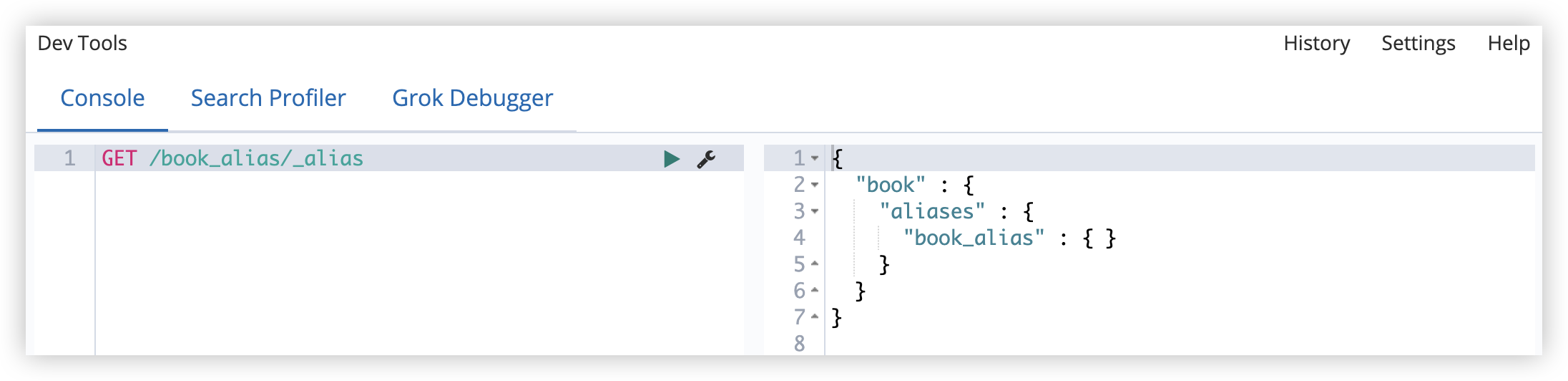
查看集群上所有可用别名:
1
GET /_alias
6 ElasticSearch 文档的 CRUD
6.1 新建文档
新建索引 book
然后向索引中添加一个文档:
1
2
3
4
5
6
7
PUT book/_doc/1
{
"name": "钝感力",
"author": "渡边淳一",
"publicationTime": "2013-10",
"type": "励志"
}
1表示新建文档的 ID
添加成功后,响应的 json 如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
{
"_index" : "book",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
- _index 表示文档索引。
- _type 表示文档类型。
- _id 表示文档的 ID。
- _version 表示文档的版本(更新文档,版本会自动加 1)。
- result 表示执行结果。
- _shards 表示分片信息。
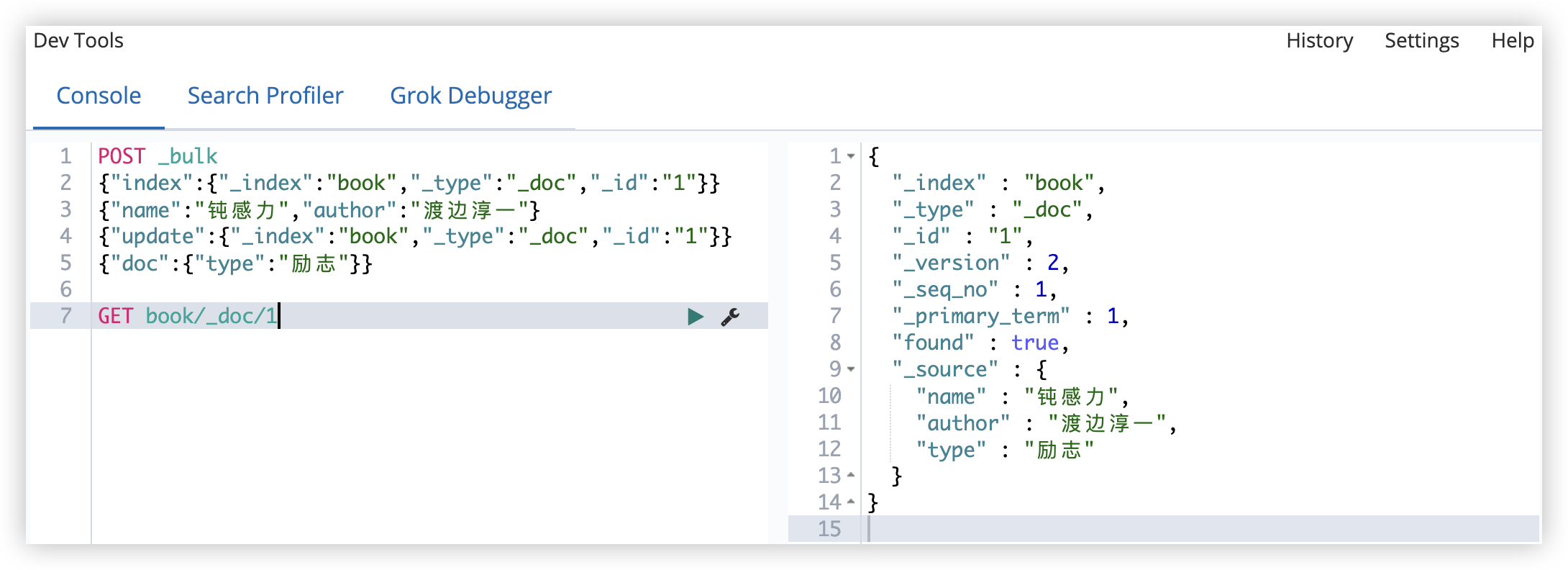
_seq_no和_primary_term这两个也是版本控制用的(针对当前索引)。
添加成功后,可以查看添加的文档:
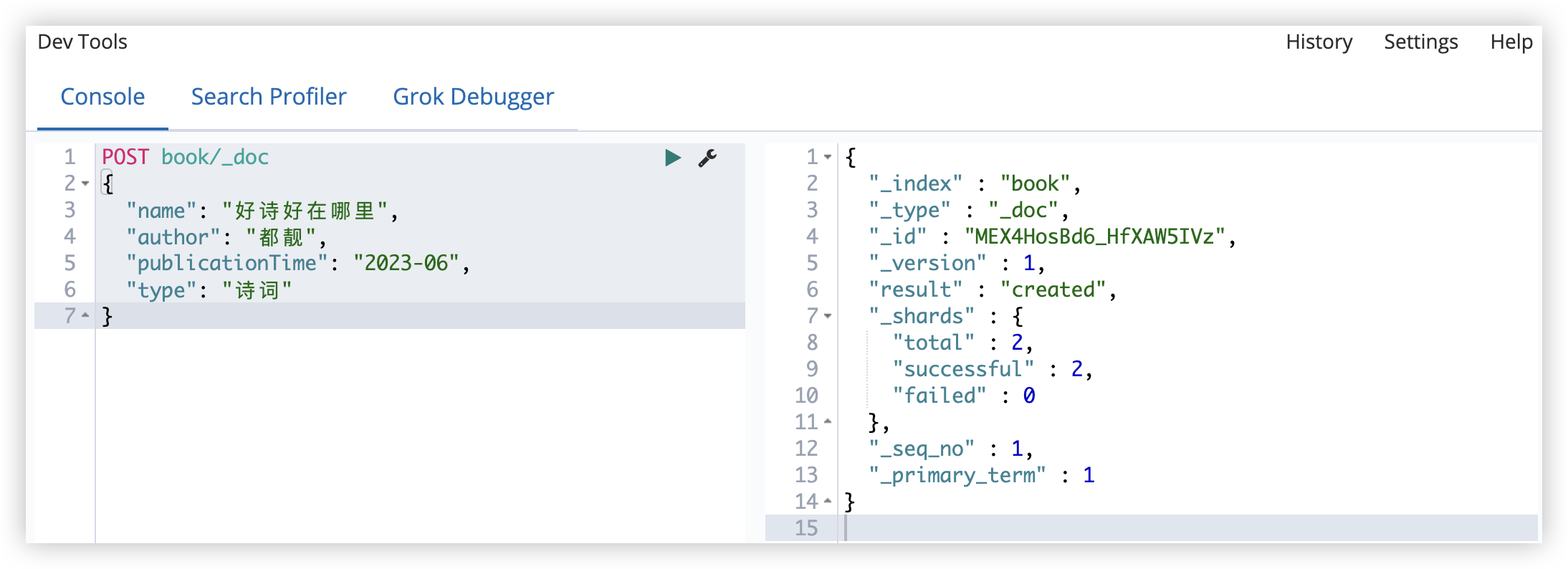
当然,添加文档时,也可以不指定 ID,此时系统会默认给出一个 ID,如果不指定 ID,则需要使用 POST 请求,而不能使用 PUT 请求。
1
2
3
4
5
6
7
POST book/_doc
{
"name": "好诗好在哪里",
"author": "都靓",
"publicationTime": "2023-06",
"type": "诗词"
}
6.2 获取文档
ES 中提供了 GET API 来查看存储在 ES 中的文档;使用方式如下:
获取 ID 为 MEX4HosBd6_HfXAW5IVz 的文档
1
GET book/_doc/MEX4HosBd6_HfXAW5IVz
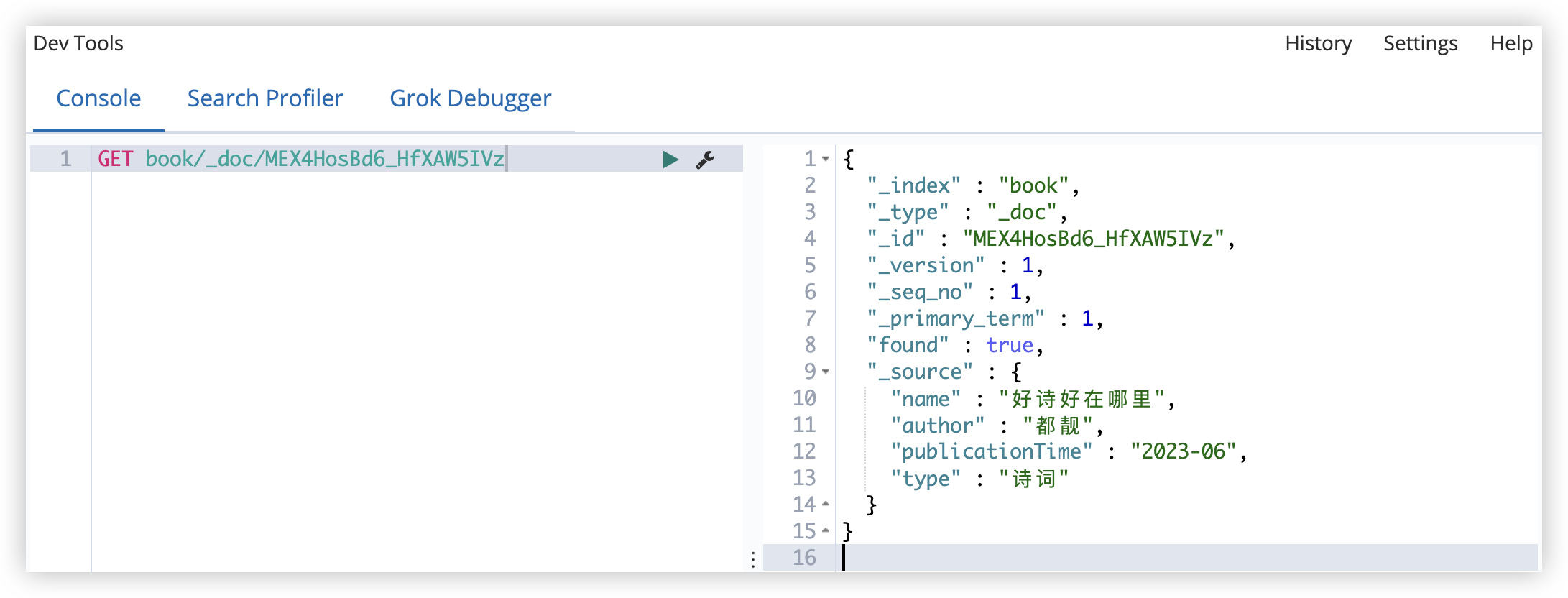
如果获取不存在的文档,会返回如下信息:
1
2
3
4
5
6
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"found" : false
}
如果仅仅只是想探测某一个文档是否存在,可以使用 head 请求:
1
HEAD book/_doc/1
如果文档存在,响应如下:

如果文档不存在,响应如下:

批量获取文档
1
2
3
4
GET book/_mget
{
"ids":["1","MEX4HosBd6_HfXAW5IVz"]
}
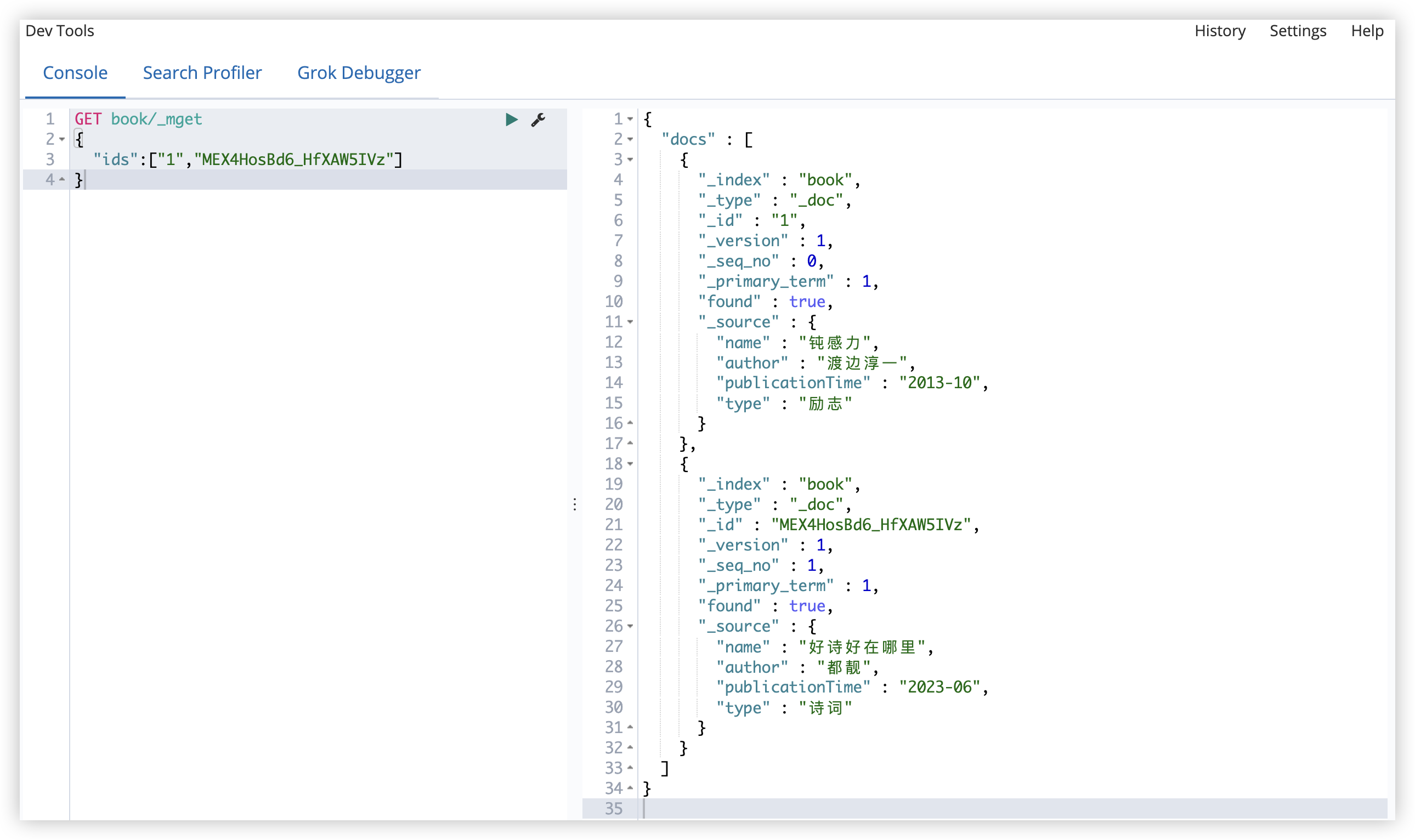
在 ES 中,GET 请求可以携带请求体?
某些特定的语言,如 JavaScript 的 HTTP 请求库是不允许 GET 请求有请求体的,实际上在 RFC7231 文档中,并没有规定 GET 请求的请求体该如何处理,这样造成了一定程度的混乱,有的 HTTP 服务器支持 GET 请求携带请求体,有的 HTTP 服务器则不支持。虽然 ES 工程师倾向于使用 GET 做查询,但为了保证兼容性,ES 同时也支持使用 POST 查询。如上面的批量查询案例,也可以使用 POST 请求。
6.3 文档更新
6.3.1 普通更新
注:文档更新一次,version 就会自增 1
可以直接更新整个文档(覆盖掉原来的文档):
1
2
3
4
PUT book/_doc/MEX4HosBd6_HfXAW5IVz
{
"name": "塔木德"
}
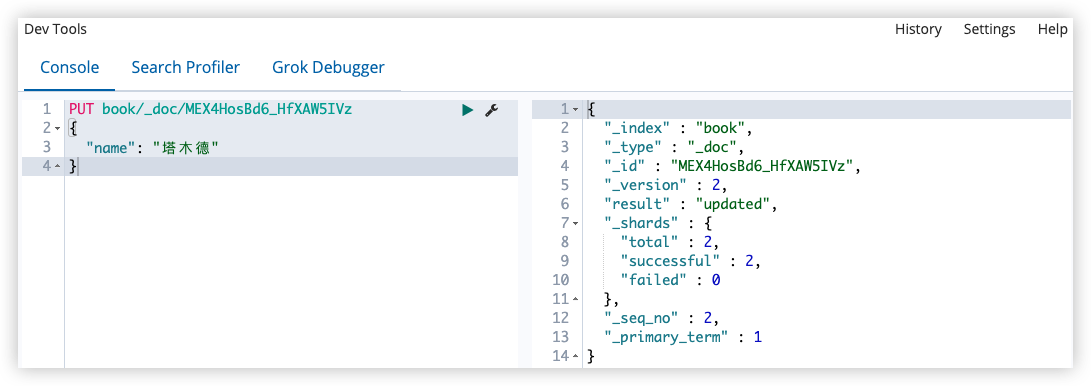
更新文档字段:
- ES6
1
2
3
4
5
6
POST book/_doc/MEX4HosBd6_HfXAW5IVz/_update
{
"doc": {
"name": "好诗好在哪里"
}
}
- ES6(脚本)
1
2
3
4
5
6
7
8
9
10
POST book/_doc/MEX4HosBd6_HfXAW5IVz/_update
{
"script": {
"lang": "painless",
"source": "ctx._source.name=params.name",
"params": {
"name": "好诗好在哪里"
}
}
}
- ES7(脚本)
1
2
3
4
5
6
7
8
9
10
POST book/_update/MEX4HosBd6_HfXAW5IVz
{
"script": {
"lang": "painless",
"source": "ctx._source.name=params.name",
"params": {
"name": "好诗好在哪里"
}
}
}
在脚本中,lang表示脚本语言,painless是 ES 内置的一种脚本语言。source表示具体执行的脚本,ctx是一个上下文对象,通过 ctx可以访问到 _source、name 等。
也可以向文档中添加字段:
- ES6
1
2
3
4
5
6
7
POST book/_doc/MEX4HosBd6_HfXAW5IVz/_update
{
"script": {
"lang": "painless",
"source":"ctx._source.tag=[\"李白\",\"杜甫\"]"
}
}

- ES7
1
2
3
4
5
6
7
POST book/_update/MEX4HosBd6_HfXAW5IVz
{
"script": {
"lang": "painless",
"source":"ctx._source.tag=[\"李白\",\"杜甫\"]"
}
}
通过脚本语言,也可以修改数组;如增加一个 tag:
- ES6
1
2
3
4
5
6
7
POST book/_doc/MEX4HosBd6_HfXAW5IVz/_update
{
"script":{
"lang": "painless",
"source":"ctx._source.tag.add(\"苏轼\")"
}
}
- ES7
1
2
3
4
5
6
7
POST book/_update/MEX4HosBd6_HfXAW5IVz
{
"script":{
"lang": "painless",
"source":"ctx._source.tag.add(\"苏轼\")"
}
}
当然,也可以使用 if else 构造稍微复杂一点的逻辑
- ES6
1
2
3
4
5
6
7
POST book/_doc/MEX4HosBd6_HfXAW5IVz/_update
{
"script": {
"lang": "painless",
"source": "if(ctx._source.tag.contains(\"李白\")){ctx.op=\"delete\"}else{ctx.op=\"none\"}"
}
}
- ES7
1
2
3
4
5
6
7
POST book/_update/MEX4HosBd6_HfXAW5IVz
{
"script": {
"lang": "painless",
"source": "if(ctx._source.tag.contains(\"李白\")){ctx.op=\"delete\"}else{ctx.op=\"none\"}"
}
}
6.3.2 查询更新
通过条件查询找到文档,然后再去更新
如将 name 中包含 诗 的文档的 type 修改为 畅销。
1
2
3
4
5
6
7
8
9
10
11
12
POST book/_update_by_query
{
"script": {
"lang": "painless",
"source": "ctx._source.type=\"畅销\""
},
"query": {
"term": {
"name": "诗"
}
}
}
6.4 删除文档
6.4.1 根据 ID 删除
从索引中删除一个文档,删除 ID 为 MUVdH4sBd6_HfXAWLIUq 的文档
1
DELETE book/_doc/MUVdH4sBd6_HfXAWLIUq
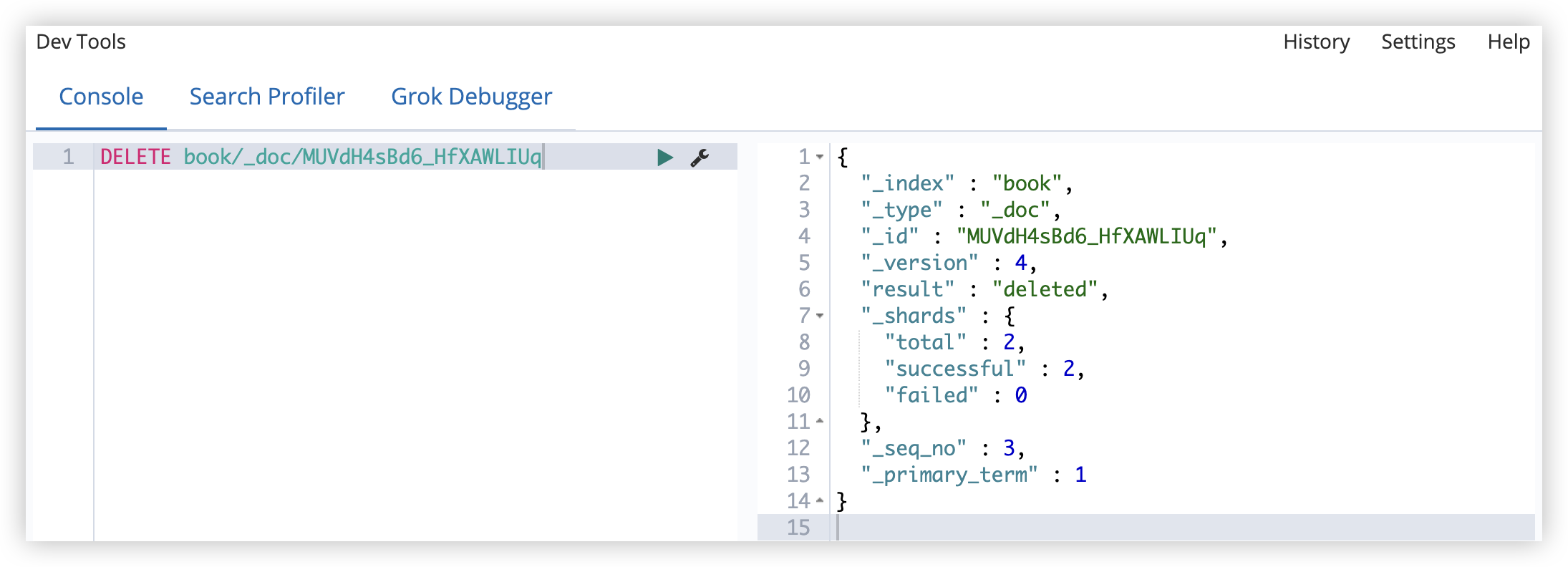
如果在添加文档时指定了路由,则删除文档时也需要指定路由,否则删除失败。
6.4.2 查询删除
查询删除是 POST 请求,删除 name 中包含 诗 的文档:
1
2
3
4
5
6
7
8
POST book/_delete_by_query
{
"query": {
"term": {
"name": "诗"
}
}
}
也可以删除某一个索引下的所有文档:
1
2
3
4
5
6
7
8
POST book/_delete_by_query
{
"query": {
"match_all": {
}
}
}
6.5 批量操作
ES 中通过 Bulk API 可以执行批量索引、批量删除、批量更新等操作。
首先需要将所有的批量操作写入一个 JSON 文件中,然后通过 POST 请求将该 JSON 文件上传并执行。
如:新建一个名为 bulk.json 的文件,内容如下:

第一行:index 表示要执行一个索引操作(index 表示一个 action,其他的 action 还有 create,update,delete)。_index 定义了索引名称,这里表示要创建一个名为 book 的索引,_type定义了类型名称(在 ES7 中,不需要指定类型),_id 表示新建文档的 id 为 1。
第二行是第一行操作的参数。
第三行的 update 表示更新。
第四行是第三行的参数。
注意:结尾要空出一行。
create 和 index 的区别:create 在 _id 重复的情况下会报错,而 index 不会报错。
bulk.json 文件创建成功后,在该目录下,执行请求命令,如下:
1
curl -XPOST "http://localhost:9200/book/_bulk" -H "content-type:application/json" --data-binary @bulk.json

执行完成后,就会创建一个名为 book 的索引,同时向该索引中添加一条记录,然后修改该记录,最终结果如下:
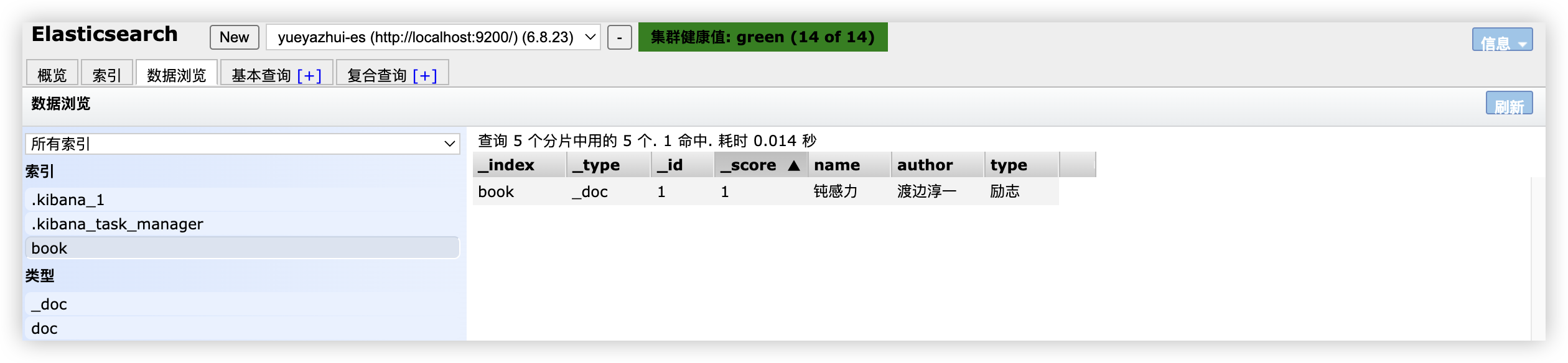
7 ElasticSearch 文档路由,数据存储在哪个分片
ES 是一个分布式系统,它使用数据分片(shard)来提高服务的可用性,将数据分散保存在不同节点上,以降低当单个节点发生故障时对数据完整性的影响。
新建一个索引,该索引有2个分片,0个副本,如下:
1
2
3
4
5
6
7
8
PUT book
{
"settings":
{
"number_of_shards": 2,
"number_of_replicas": 0
}
}
接下来,向该索引中保存一个文档:
1
2
3
4
PUT book/_doc/1
{
"name": "钝感力"
}
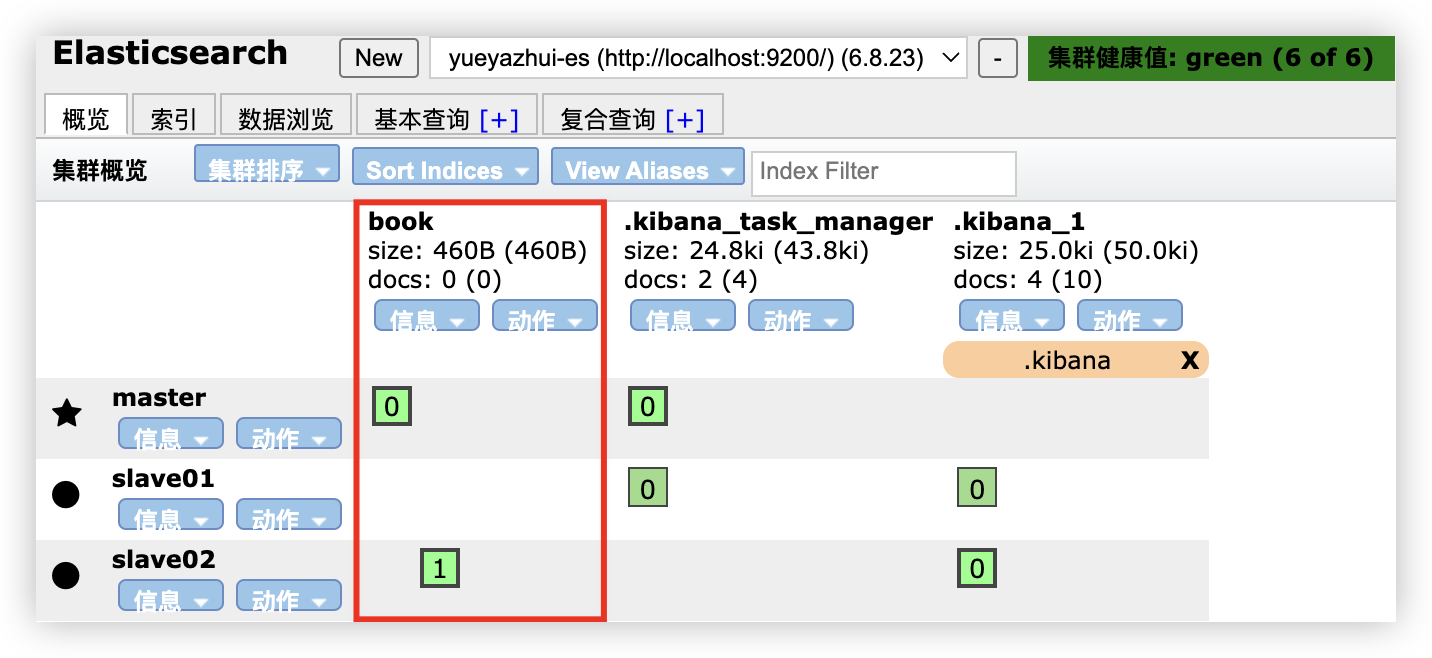
文档保存成功后,可以查看该文档被保存到哪个分片中了:
1
GET _cat/shards/book?v
查看结果如下:
1
2
3
index shard prirep state docs store ip node
book 1 p STARTED 1 3.3kb 127.0.0.1 slave02
book 0 p STARTED 0 230b 127.0.0.1 master
从这个结果中,可以看出,文档是被保存到分片 1 中的。
那么 ES 中到底是按照什么样的规则去分配分片的?
ES 中的路由机制是通过哈希算法,将具有相同哈希值的文档放到一个分片中,分片位置的计算方式如下:
shard=hash(routing) % number_of_primary_shards
routing 可以是一个任意字符串,ES 默认是将文档的 ID 作为 routing 的值,通过哈希函数根据 routing 生成一个数字,然后将该数字和分片数取余,取余的结果就是分片的位置。
默认的这种路由模式,最大的优势在于负载均衡,这种方式可以保证数据平均分配在不同的分片上。但它有一个很大的劣势,就是查询时无法确定文档的位置,此时它会将请求广播到所有的分片上去执行。
当然开发者可以自定义 routing 的值,方式如下:
1
2
3
4
PUT book/_doc/2?routing=yueyazhui
{
"name": "好诗好在哪里"
}
如果文档在添加时指定了 routing,则查询、更新、删除时也需要指定 routing。
1
GET book/_doc/2?routing=yueyazhui
自定义 routing 有可能会导致负载不均衡,这个需要结合实际情况选择。
典型场景:
对于用户数据,可以将 userId 作为 routing,这样就能保证同一个用户的数据保存在同一个分片中,检索时,同样使用 userId 作为 routing,这样就可以精准的从某一个分片中获取数据。
8 ElasticSearch 并发的处理方式:锁和版本控制
当使用 ES 的 API 去进行文档更新时,它首先读取原文档出来,然后对原文档进行更新,更新完成后再重新索引整个文档。不论你执行多少次更新,最终保存在 ES 中的是最后一次更新的文档。但如果有两个线程同时去更新,就有可能出问题,要解决这个问题,就用到了锁。
8.1 锁
悲观锁
每次去读取数据时,都认为别人可能会修改数据,所以屏蔽一切可能破坏数据完整性的操作。在关系型数据库中,悲观锁使用较多,例如行锁、表锁、读锁、写锁等。
乐观锁
每次读取数据时,都认为别人不会修改数据,因此也不锁定数据,只有在提交数据时,才会检查数据完整性。这种方式可以省去锁的开销,进而提高吞吐量。
在 ES 中,实际上使用的就是乐观锁。
8.2 版本控制
ES6.7 之前
在 ES6.7 之前,使用 version + version_type 来进行乐观并发控制。根据前面的介绍,文档每被修改一次,version 就会自增一次,ES 通过 version 字段来确保所有的操作都有序进行。
version 分为内部版本控制和外部版本控制。
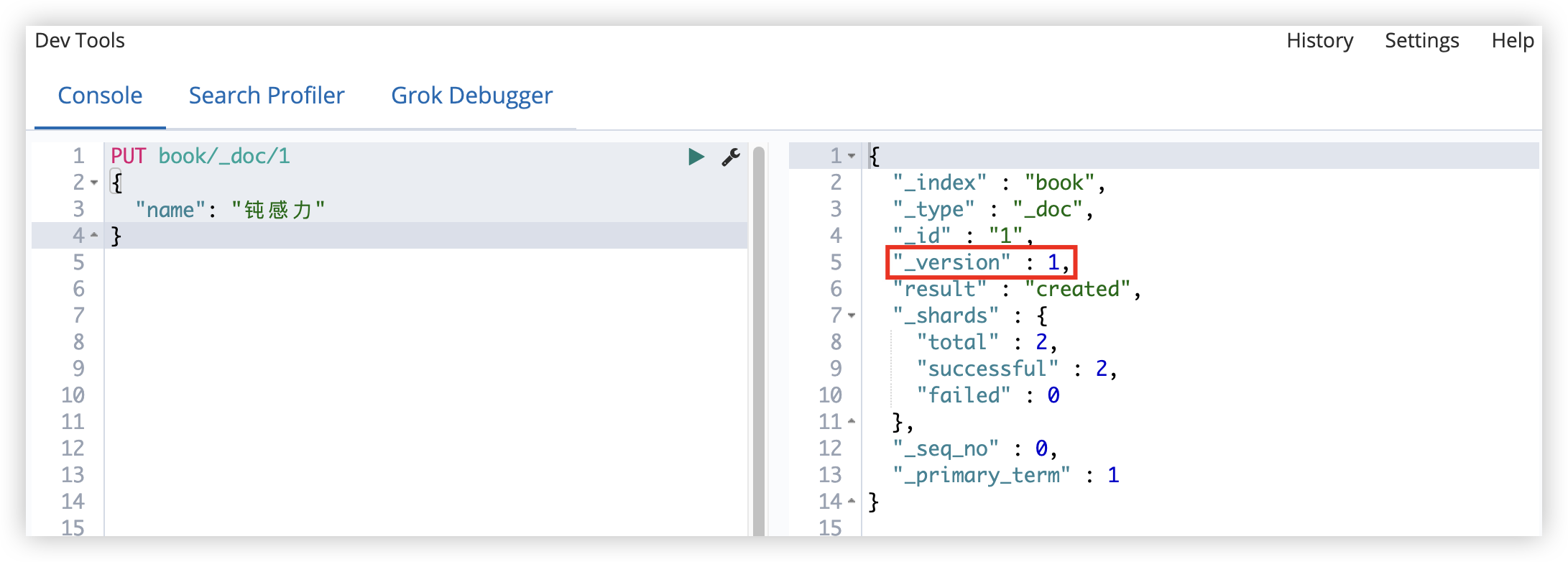
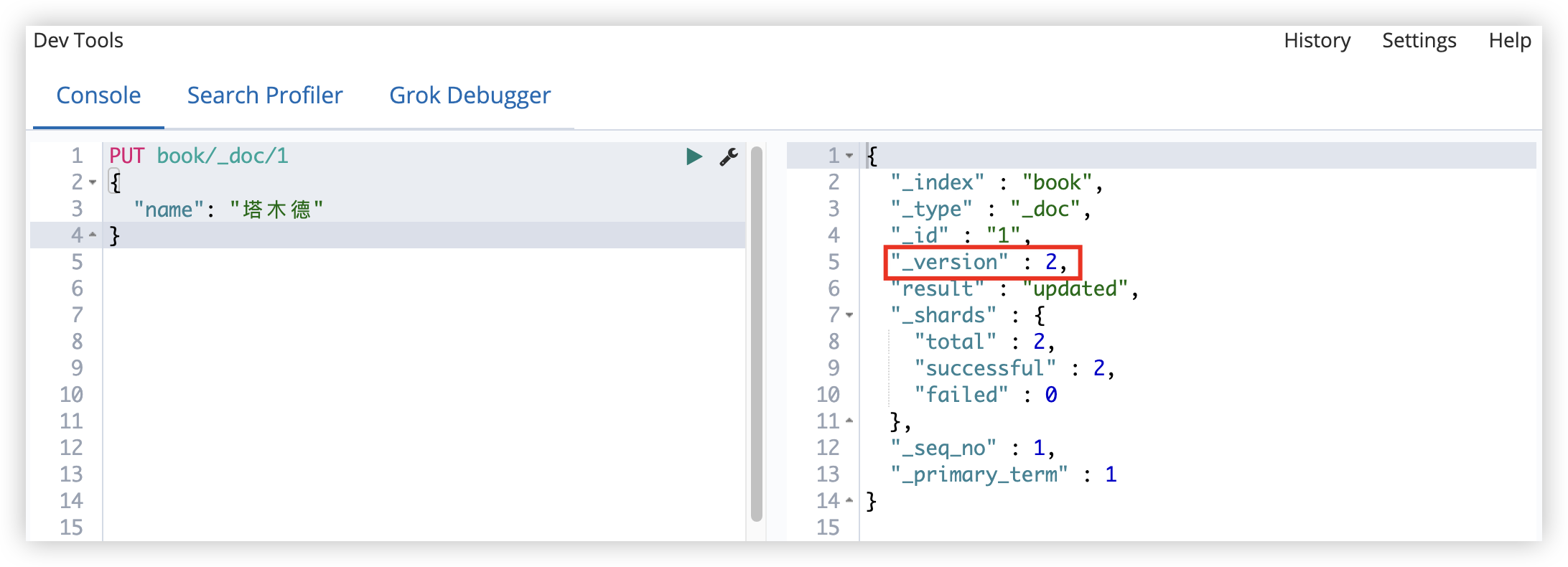
8.2.1 内部版本
ES 自己维护的就是内部版本,当创建文档时,ES 会给这个文档的版本赋值为 1。
每修改一次文档,版本号就会自增 1。
如果使用内部版本,ES 要求 version 参数值必须等于 ES 文档中 version 的值,才能操作成功。
8.2.2 外部版本
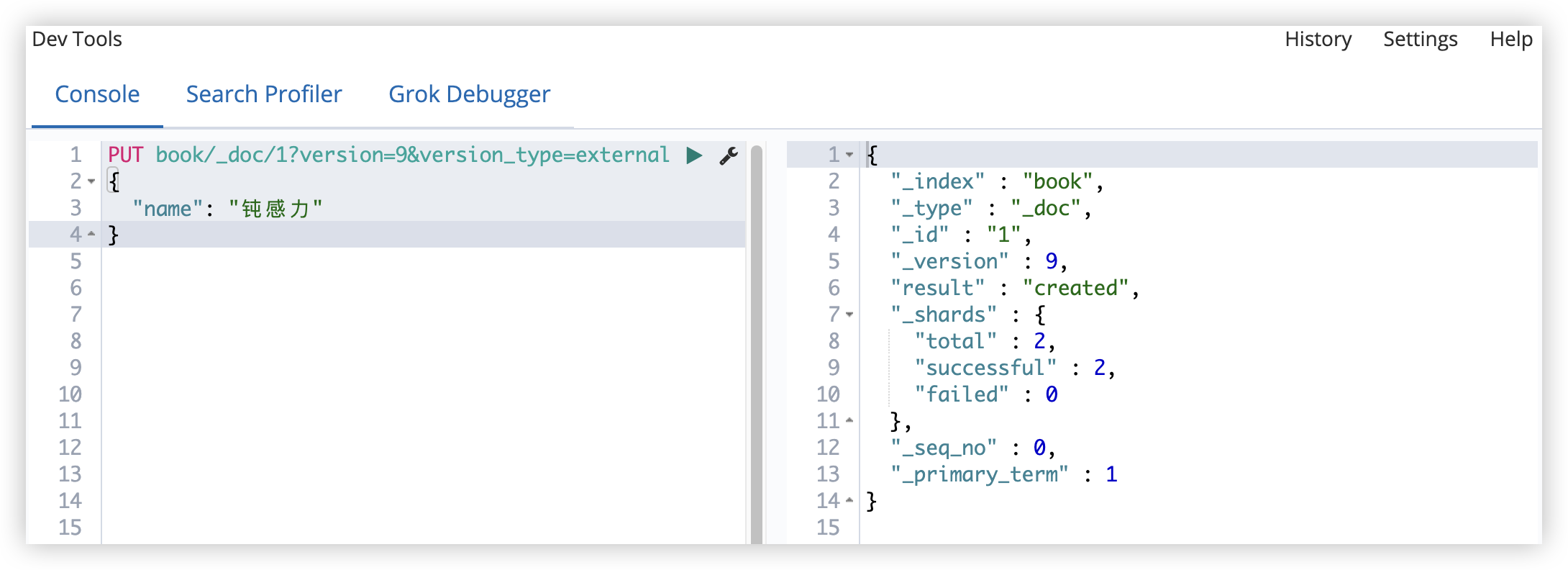
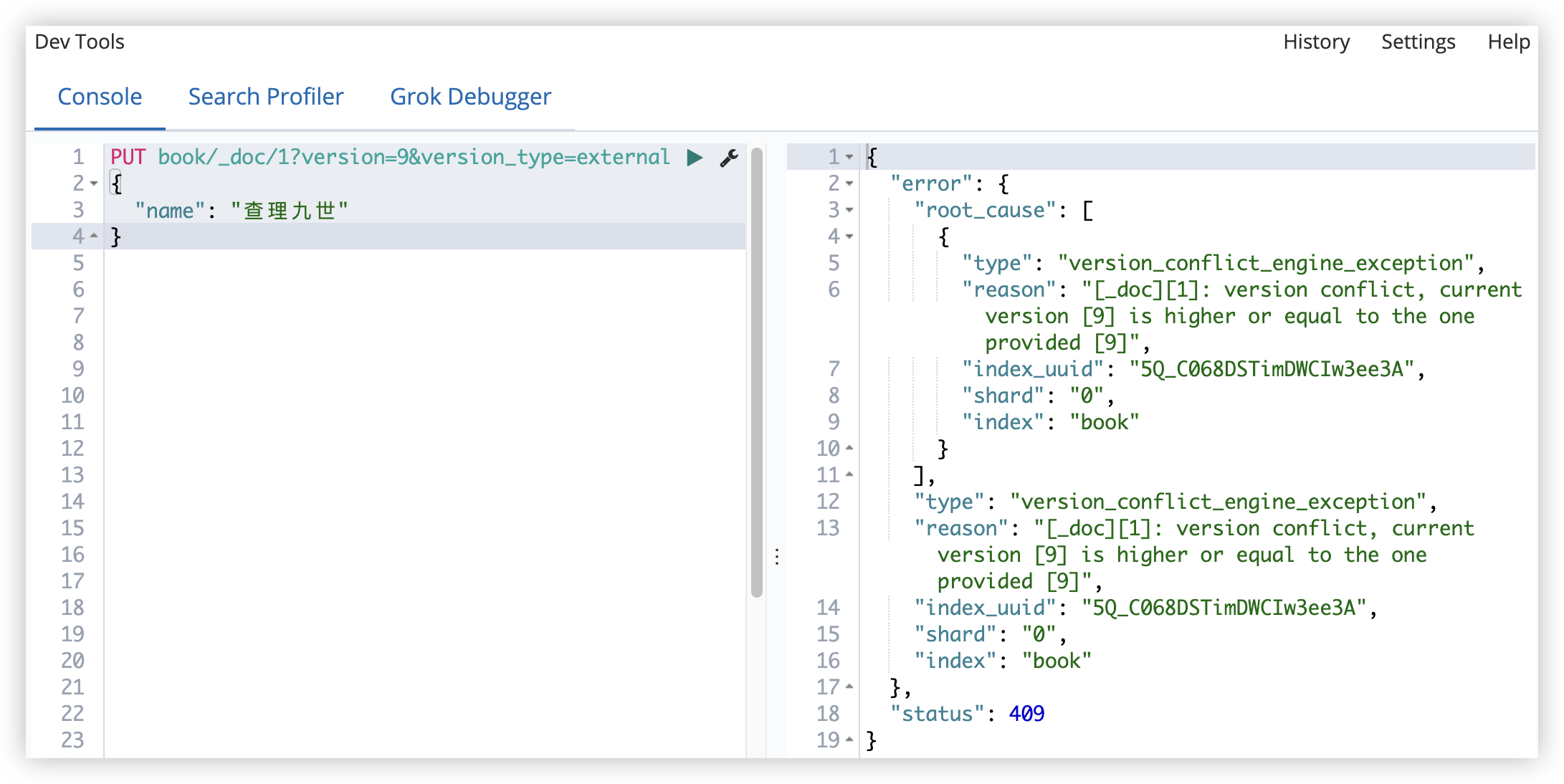
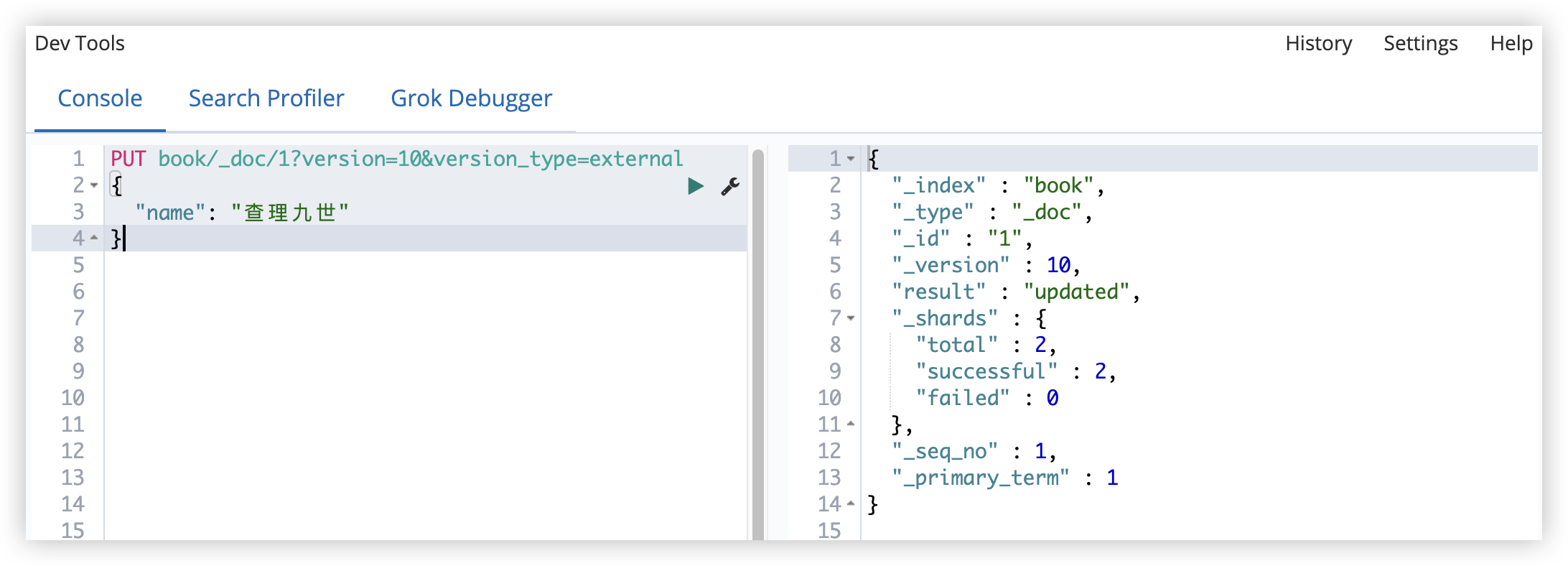
也可以维护外部版本。
在添加文档时,就指定版本号:
1
2
3
4
PUT book/_doc/9?version=9&version_type=external
{
"name": "钝感力"
}
以后更新的时候,版本要大于已有的版本号。
- vertion_type=external 表示以后更新的时候,版本要大于已有的版本号。
- vertion_type=external_gte 表示以后更新的时候,版本要大于等于已有的版本号。
8.2.3 最新方案(ES6.7 之后)
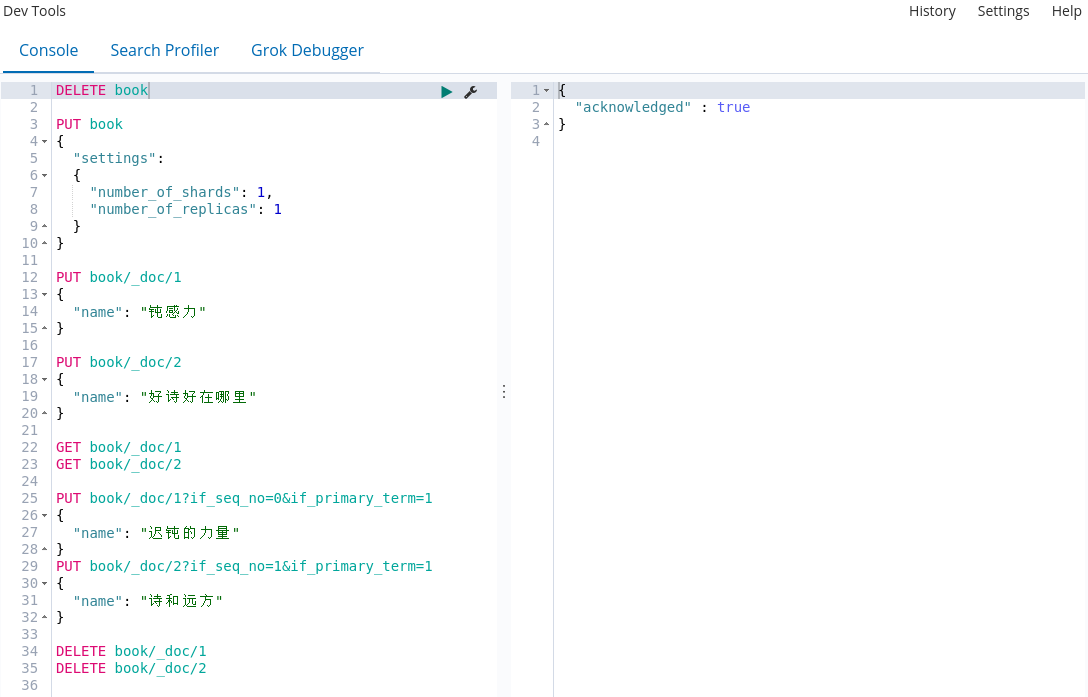
现在使用if_seq_no和if_primary_term两个参数来做并发控制。
seq_no不属于某一个文档,它是属于整个索引的(version 则是属于某一个文档的,每个文档的 version 互不影响)。现在更新文档时,使用_seq_no来做并发。由于_seq_no是属于整个 index 的,所以该索引中任何文档的修改或者新增,_seq_no都会自增。
现在就可以通过if_seq_no和if_primary_term来做乐观并发控制。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
DELETE book
PUT book
{
"settings":
{
"number_of_shards": 1,
"number_of_replicas": 1
}
}
PUT book/_doc/1
{
"name": "钝感力"
}
PUT book/_doc/2
{
"name": "好诗好在哪里"
}
GET book/_doc/1
GET book/_doc/2
PUT book/_doc/1?if_seq_no=0&if_primary_term=1
{
"name": "迟钝的力量"
}
PUT book/_doc/2?if_seq_no=1&if_primary_term=1
{
"name": "诗和远方"
}
DELETE book/_doc/1
DELETE book/_doc/2
9 ElasticSearch 倒排索引
倒排索引是 ES 中非常重要的索引结构,是从文档词项到文档 ID 的一个映射过程。
9.1 “正排索引”
在关系型数据库中见到的索引,就是“正排索引”。
关系型数据库中的索引如下,假设有一个图书表:
| id | name | author | publicationTime | content |
|---|---|---|---|---|
| 1 | 钝感力 | 渡边淳一 | 2013-10 | 迟钝的力量 |
| 2 | 好诗好在哪里 | 都靓 | 2023-06 | 诗和远方 |
针对该表建立索引(正排索引):
| 索引 | 内容 |
|---|---|
| 1 | 迟钝的力量 |
| 2 | 诗和远方 |
| 钝感力 | 迟钝的力量 |
| 好诗好在哪里 | 诗和远方 |
当通过 id 或者 name 去搜索 content 时,可以快速搜到。
但如果按照 content 的关键字去搜索,就只能去内容中做字符匹配了。为了提高查询效率,就要考虑使用倒排索引。
9.2 倒排索引
倒排索引就是以内容的关键字建立索引,通过索引找到文档 ID,进而找到整个文档。
| 索引 | 文档 id=1 | 文档 id=2 |
|---|---|---|
| 迟钝 | ✔ | |
| 力量 | ✔ | |
| 诗 | ✔ | |
| 远方 | ✔ |
一般来说,倒排索引分为两个部分:
- 单词词典(记录所有的文档词项以及词项到倒排列表的关联关系)
- 倒排列表(记录单词与对应的关系,由一系列倒排索引项组成,倒排索引项:文档 id、词频(TF)(词项在文档中出现的次数,评分时使用)、位置(Position,词项在文档中分词的位置)、偏移(记录词项开始和结束的位置))
当索引一个文档时,就会建立倒排索引,搜索时,直接根据倒排索引去搜索。
10 ElasticSearch 动态映射与静态映射
映射(Mapping),它用来定义一个文档以及文档所包含的字段该如何被存储和索引。所以,它其实有点类似于关系型数据库中表的定义。
10.1 映射分类
signpost_go_dynamic
动态映射就是自动创建出来的映射。ES 根据存入的文档,自动分析出文档中字段的类型以及存储方式,这就是动态映射。
例:新建一个索引,然后查看索引信息:
1
2
3
4
5
6
7
8
PUT book
{
"settings":
{
"number_of_shards": 1,
"number_of_replicas": 1
}
}
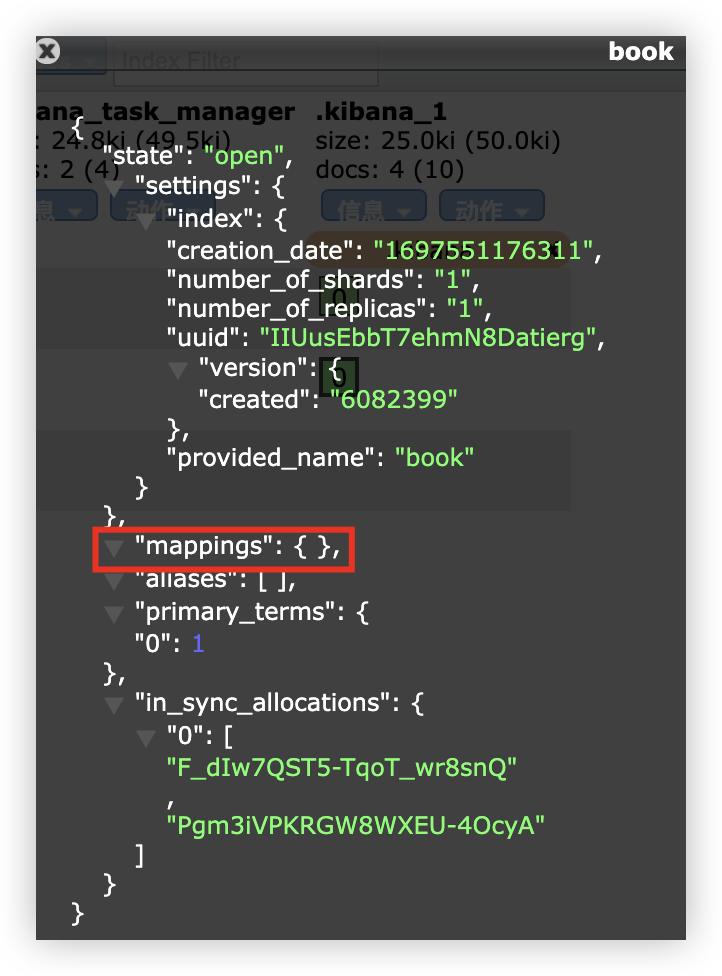
在创建好的索引信息中,可以看到,mappings 为空,这个 mappings 中保存的就是映射信息。
向索引中添加一个文档,如下:
1
2
3
4
5
6
PUT book/_doc/1
{
"name": "钝感力",
"author": "渡边淳一",
"publicationTime": "2013-10"
}
文档添加成功后,就会自动生成 Mappings:
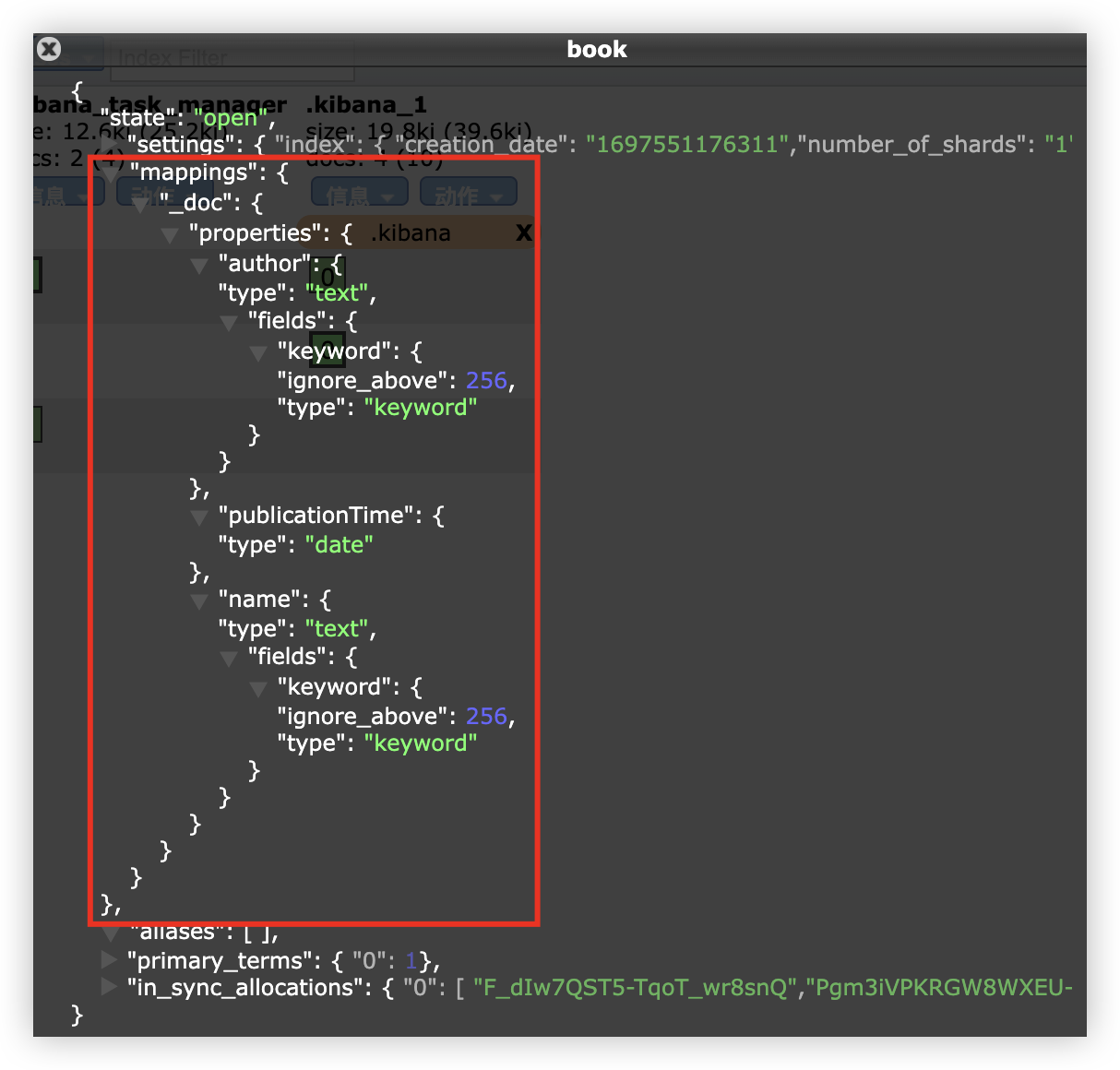
可以看到,publicationTime 字段的类型为 date,name 和 author 的类型有两个,text 和 keyword。
默认情况下,文档中如果新增了字段,mappings 中也会自动新增进来。
1
2
3
4
5
6
7
PUT book/_doc/2
{
"name": "好诗好在哪里",
"author": "都靓",
"publicationTime": "2023-06",
"content": "诗和远方"
}
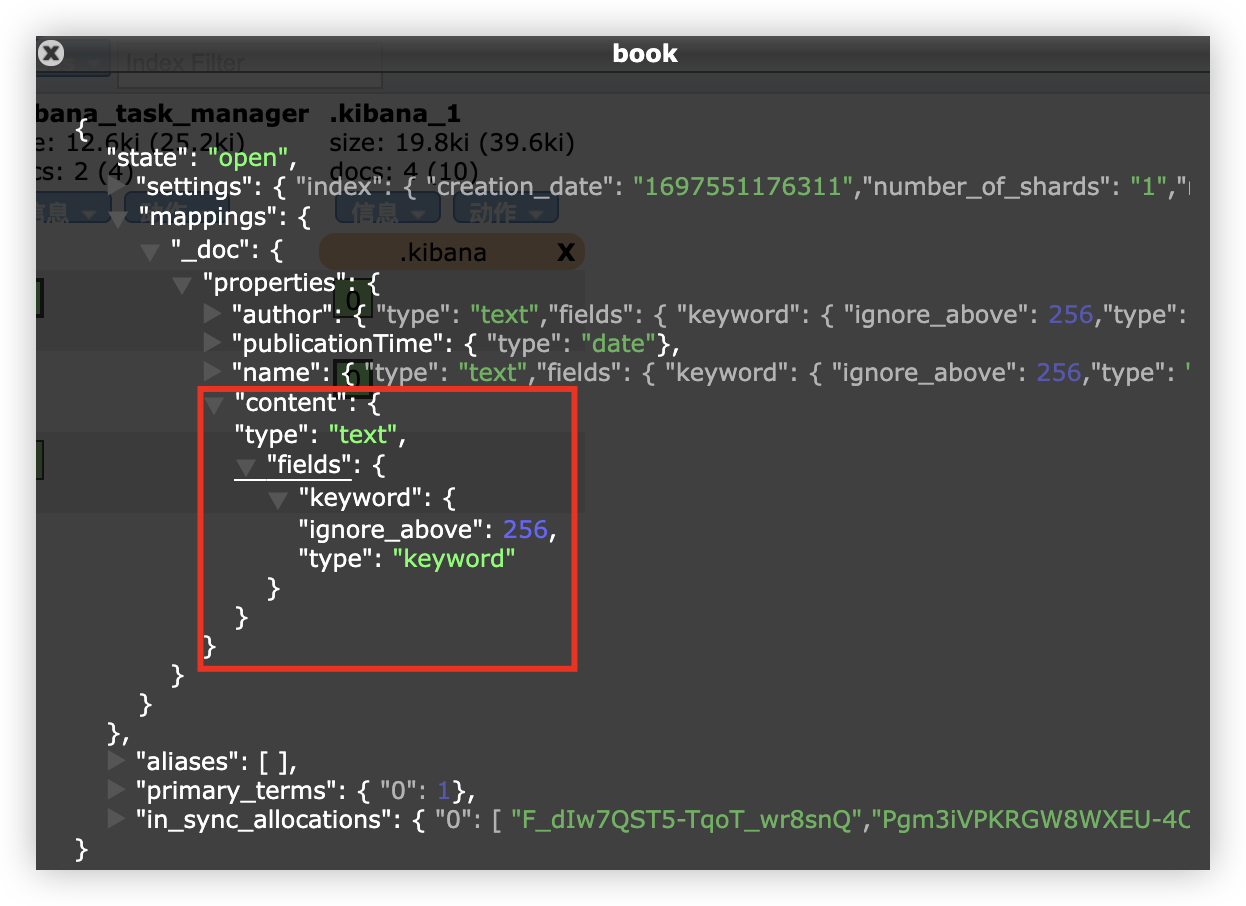
如果希望在新增字段时,能够抛出异常来提醒开发者,这个可以通过 mappings 中 dynamic 属性来配置。
dynamic 属性有三种取值:
- true,默认,自动添加新字段。
- false,忽略新字段。
- strict,严格模式,发现新字段会抛出异常。
具体的配置方式如下,创建索引时指定 mappings(静态映射):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
PUT book?include_type_name=false
{
"mappings":
{
"dynamic": "strict",
"properties":
{
"name":
{
"type": "text"
},
"publicationTime":
{
"type": "date"
}
}
},
"settings":
{
"number_of_shards": 1,
"number_of_replicas": 1
}
}
然后向 book 索引中添加数据:
1
2
3
4
5
6
PUT book/_doc/1
{
"name": "钝感力",
"author": "渡边淳一",
"publicationTime": "2013-10"
}
在添加的文档中,author 字段没有预定义,所以这个添加操作就会报错:
1
2
3
4
5
6
7
8
9
10
11
12
13
{
"error": {
"root_cause": [
{
"type": "strict_dynamic_mapping_exception",
"reason": "mapping set to strict, dynamic introduction of [author] within [doc] is not allowed"
}
],
"type": "strict_dynamic_mapping_exception",
"reason": "mapping set to strict, dynamic introduction of [author] within [doc] is not allowed"
},
"status": 400
}
动态映射的日期检测
例:新建一个索引,然后添加一个含有日期的文档,如下:
1
2
3
4
PUT book/_doc/1
{
"publicationTime": "2023-06"
}
添加成功后,publicationTime 字段会被推断出是一个日期类型。
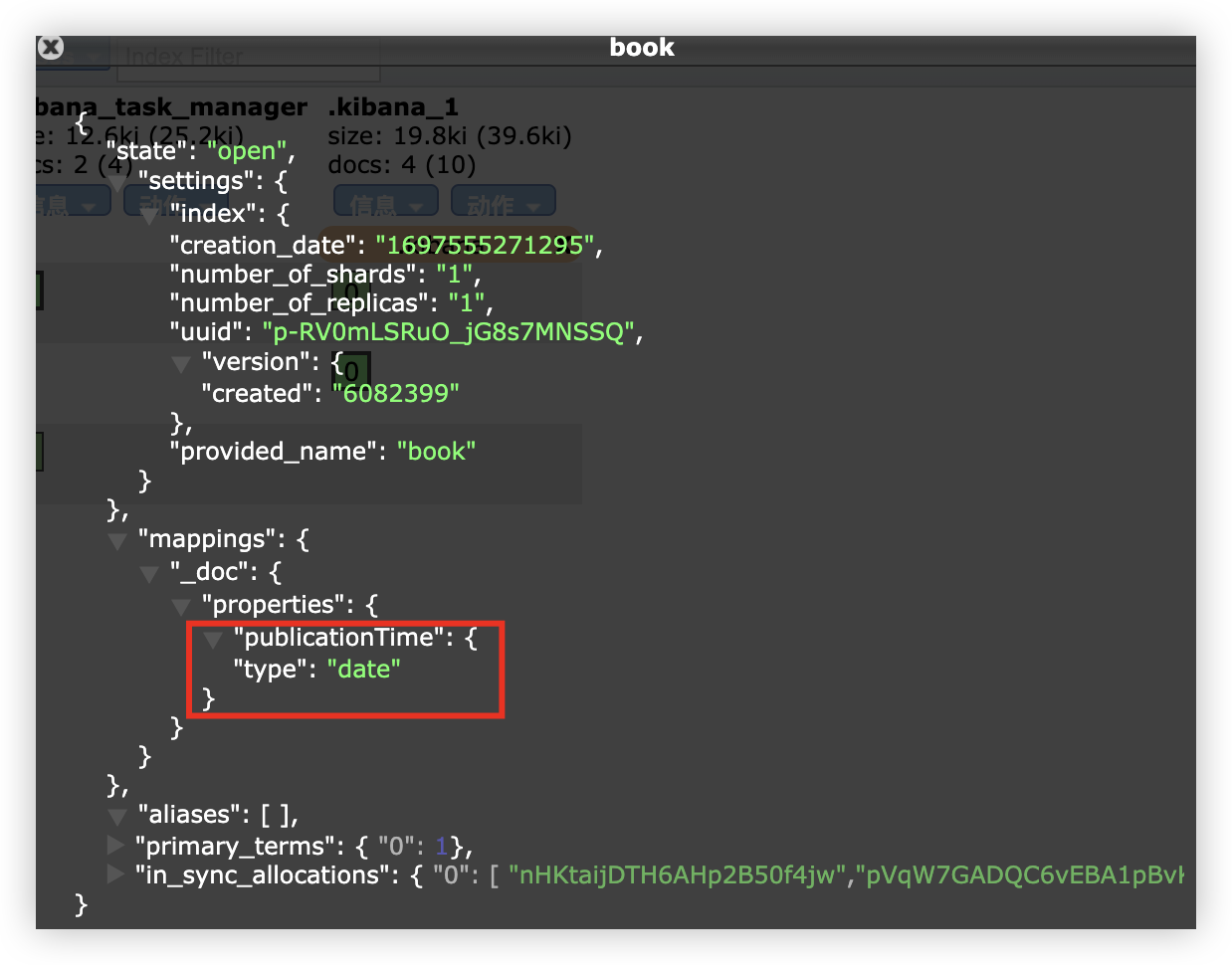
此时,publicationTime 字段已经无法存储其他类型的值了。
1
2
3
4
PUT book/_doc/2
{
"publicationTime": "好诗好在哪里"
}
此时报错如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
{
"error": {
"root_cause": [
{
"type": "mapper_parsing_exception",
"reason": "failed to parse field [publicationTime] of type [date] in document with id '2'"
}
],
"type": "mapper_parsing_exception",
"reason": "failed to parse field [publicationTime] of type [date] in document with id '2'",
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Invalid format: \"好诗好在哪里\""
}
},
"status": 400
}
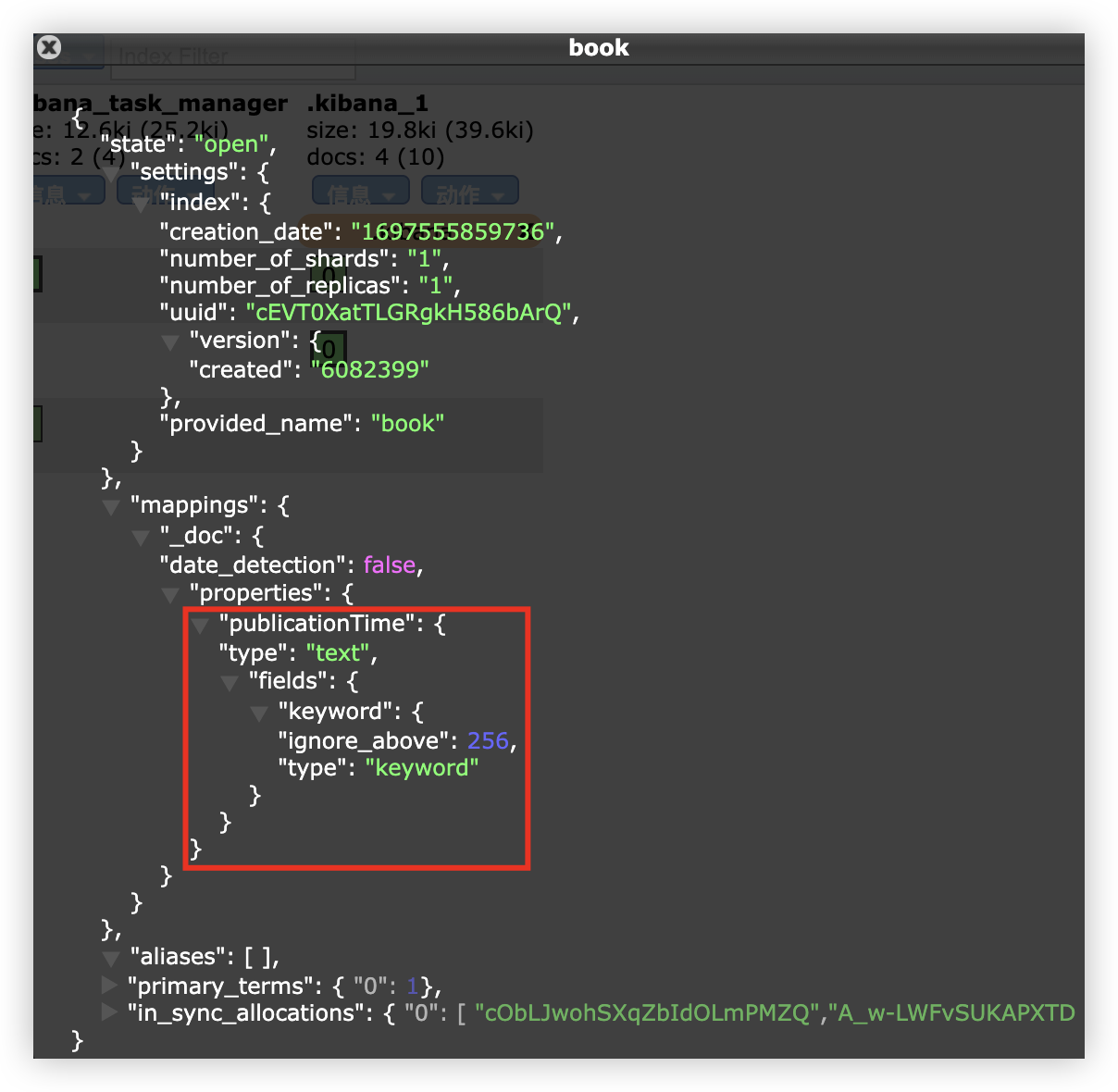
解决这个问题,可以使用静态映射,即在创建索引时,将 publicationTime 指定为 text 类型 或 直接关闭日期检测。
1
2
3
4
5
6
7
8
9
10
11
PUT book?include_type_name=false
{
"mappings": {
"date_detection": false
},
"settings":
{
"number_of_shards": 1,
"number_of_replicas": 1
}
}
此时日期类型就会当成文本来处理。
10.2 类型推断
ES 中动态映射类型推断方式如下:
| JSON 数据 | 推断出的数据类型 |
|---|---|
| null | 没有字段被添加 |
| true/false | boolean |
| 浮点数 | float |
| 数字 | long |
| JSON 对象 | object |
| 数组 | 数组中第一个非空值来决定 |
| string | text/keyword/date/double/long 都有可能 |
11 ElasticSearch 字段类型
11.1 核心类型
11.1.1 字符串类型
- string:这是一个已经过期的字符串类型。在 ES5 之前,用这个来描述字符串,现在已被 text 和 keyword 替代。
- text:如果一个字段是要被全文检索的,比如说博客内容、新闻内容、产品描述等,就可以使用该类型。用该类型之后,字段内容会被分析,在生成倒排索引之前,字符串会被分词器分成一个个词项。该类型的字段不用于排序,很少用于聚合。这种字符串也被称为 analyzed 字段。
- keyword:该类型适用于结构化的字段,例如名称、邮箱、手机号等,该类型的字段可以用作过滤、排序、聚合等。这种字符串也被称之为 not-analyzed 字段。
11.1.2 数字类型
| 类型 | 取值范围 |
|---|---|
| long | -2^63到2^63-1 |
| integer | -2^31到2^31-1 |
| short | -2^15到2^15-1 |
| byte | -2^7到2^7-1 |
| double | 64 位的双精度 IEEE754 浮点类型 |
| float | 32 位的双精度 IEEE754 浮点类型 |
| half_float | 16 位的双精度 IEEE754 浮点类型 |
| scaled_float | 可以缩放的浮点类型 |
- 在满足需求的情况下,优先使用范围小的字段,字段长度越短,索引和搜索的效率就越高。
- 浮点数,优先考虑使用 scaled_float。
scaled_float 举例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"price": {
"type": "scaled_float",
"scaling_factor": 100
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
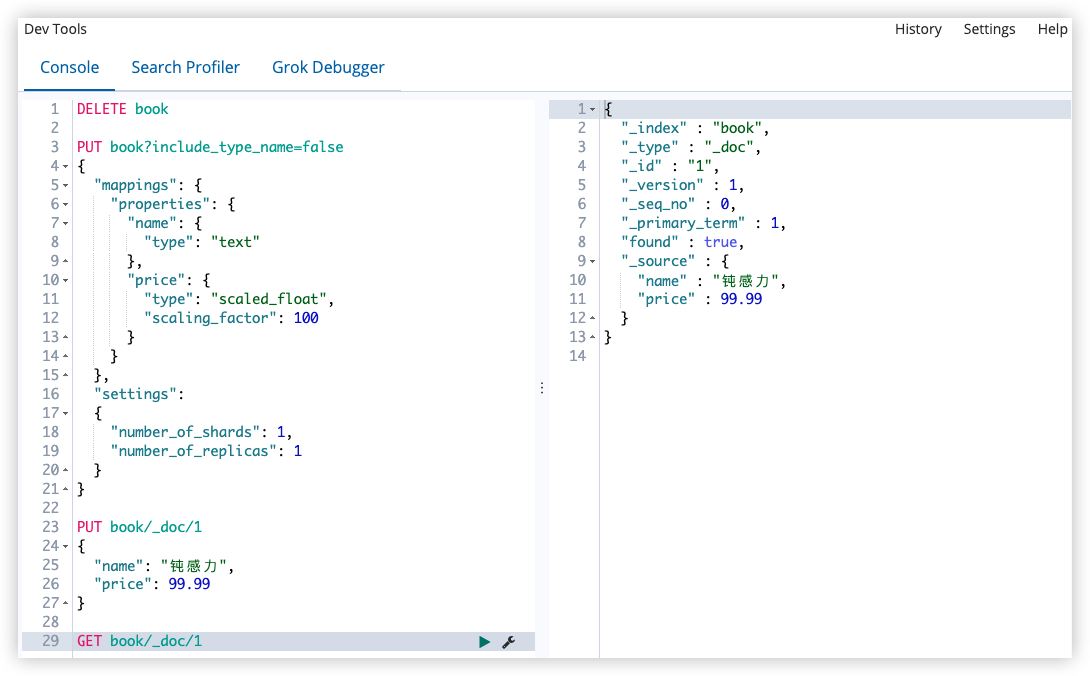
如果这本书的价格是 99.99,ES 会将 99.99 存储为 9999,因为缩放因子是 100;这样存储更节省空间。
11.1.3 日期类型
由于 JSON 中没有日期类型,所以 ES 中的日期类型形式比较多样:
- 2023-10-19 或者 2023-10-19 22:22:22
- 一个从 1970-01-01 到现在的一个秒数或者毫秒数
ES 内部将时间转为 UTC,然后将时间按照 millseconds-since-the-epoch 的长整型来存储。
自定义日期类型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"publicationTime": {
"type": "date"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
这个能够解析出来的时间格式比较多。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
PUT book/_doc/1
{
"publicationTime": "2013-10"
}
PUT book/_doc/2
{
"date": "2013-10-19"
}
PUT book/_doc/3
{
"date": "2023-10-19T22:22:22Z"
}
PUT book/_doc/4
{
"date": "1697725342000"
}
上面文档中的日期都可以被解析,ES 内部存储的是毫秒计时的长整型数字。
11.1.4 布尔类型(boolean)
JSON 中的 “true”、“false”、true、false 都可以。
11.1.5 二进制类型(binary)
二进制接受的是 Base64 编码的字符串,默认不存储,也不可搜索。
11.1.6 范围类型
- integer_range
- float_range
- long_range
- double_range
- date_range
- ip_range
定义的时候,指定范围类型即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"publicationTime": {
"type": "date"
},
"price": {
"type": "float_range"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
插入文档的时候,需要指定范围的界限:
1
2
3
4
5
6
7
8
9
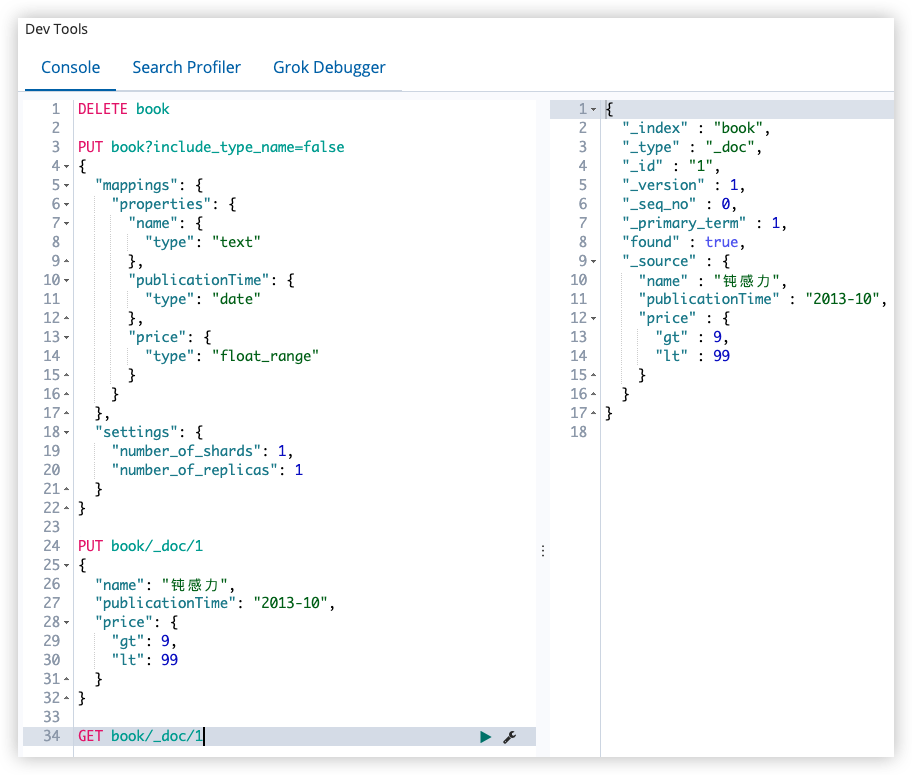
PUT book/_doc/1
{
"name": "钝感力",
"publicationTime": "2013-10",
"price": {
"gt": 9,
"lt": 99
}
}
指定范围时,可以使用 gt、gte、lt、lte。
11.2 复合类型
11.2.1 数组类型
ES 中没有专门的数组类型。默认情况下,任何字段都可以有一个或者多个值;需要注意的是,数组中的元素必须是同一种类型。
数组中的第一个元素决定了整个数组的类型。
11.2.2 对象类型(object)
由于 JSON 本身具有层级关系,所以文档包含内部对象;在内部对象中,还可以再包含内部对象。
1
2
3
4
5
6
7
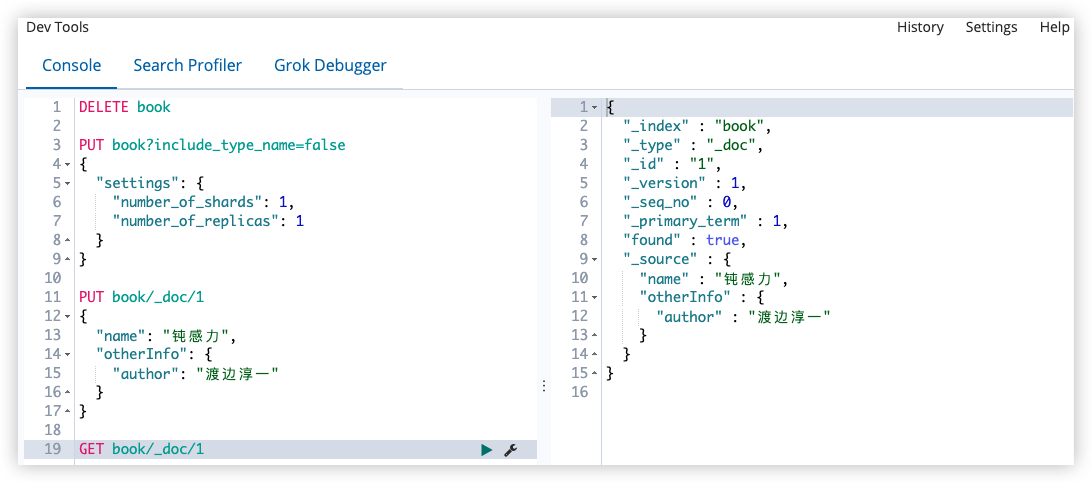
PUT book/_doc/1
{
"name": "钝感力",
"otherInfo": {
"author": "渡边淳一"
}
}
11.2.3 嵌套类型(nested)
signpost_go_nested
nested 是 object 中的一个特例。
如果使用 object 类型,文档如下:
1
2
3
4
5
6
7
8
9
{
"user": [{
"first": "张",
"last": "三"
}, {
"first": "李",
"last": "四"
}]
}
由于 Lucene 没有内部对象的概念,所以 ES 会将对象层次扁平化,将一个对象转化为字段属性和属性值构成的简单列表,最终的存储形式如下:
1
2
3
4
{
"user.first": ["张","李"],
"user.last": ["三","四"]
}
扁平化之后,用户名之间的联系就没有了;这样会导致如果搜索 张四 这个人,就可以搜索到。
这种情况下,可以用 nested 类型来解决问题,nested 类型可以保持数组中每个对象的独立性;nested 类型将数组中的每一个对象作为独立隐藏文档来索引,这样每一个嵌套对象都可以独立的被索引。
1
2
3
4
5
6
7
8
9
{
{
"user.first": "张",
"user.last": "三"
}, {
"user.first": "李",
"user.last": "四"
}
}
优点:文档读取的准确性更高。
缺点:更新父或者子文档时需要更新整个文档。
11.3 地理类型
使用场景:
- 查找某一个范围内的地理位置
- 通过地理位置或者相对中心点的距离来聚合文档(把聚合理解为索引或查询)
- 把距离整合到文档的评分中(如:距离越近评分越高)
- 通过距离对文档进行排序
11.3.1 geo_point
geo_point 就是一个坐标点,定义方式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
PUT people?include_type_name=false
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
创建时指定字段类型,存储的时候,有四种方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
PUT people/_doc/1
{
"location": {
"lon": 116.403425,
"lat": 39.924079
}
}
# 先纬度后经度
PUT people/_doc/2
{
"location": "39.924079,116.403425"
}
PUT people/_doc/3
{
"location": [116.403425,39.924079]
}
# 空间索引
PUT people/_doc/4
{
"location": "wx4g0gfqs7sx"
}
11.3.2 geo_shape
| GeoJson | ElasticSearch | 备注 |
|---|---|---|
| Point | point | 一个由经纬度描述的点 |
| LineString | linestring | 一个任意的线条,由两个以上的点组成 |
| Polygon | polygon | 一个封闭多边形 |
| MultiPoint | multipoint | 多个不连续的点 |
| MultiLineString | multilinestring | 多条不关联的线 |
| MultiPolygon | multipolygon | 多个多边形 |
| GeometryCollection | geometrycollection | 几何对象的集合 |
| circle | 一个圆形 | |
| envelope | 通过左上角和右下角两个点确定的矩形 |
指定 geo_shape 类型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
PUT people?include_type_name=false
{
"mappings": {
"properties": {
"location": {
"type": "geo_shape"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
添加文档时需要指定具体的类型
point:
1
2
3
4
5
6
7
PUT people/_doc/1
{
"location": {
"type": "point",
"coordinates": [116.403425,39.924079]
}
}
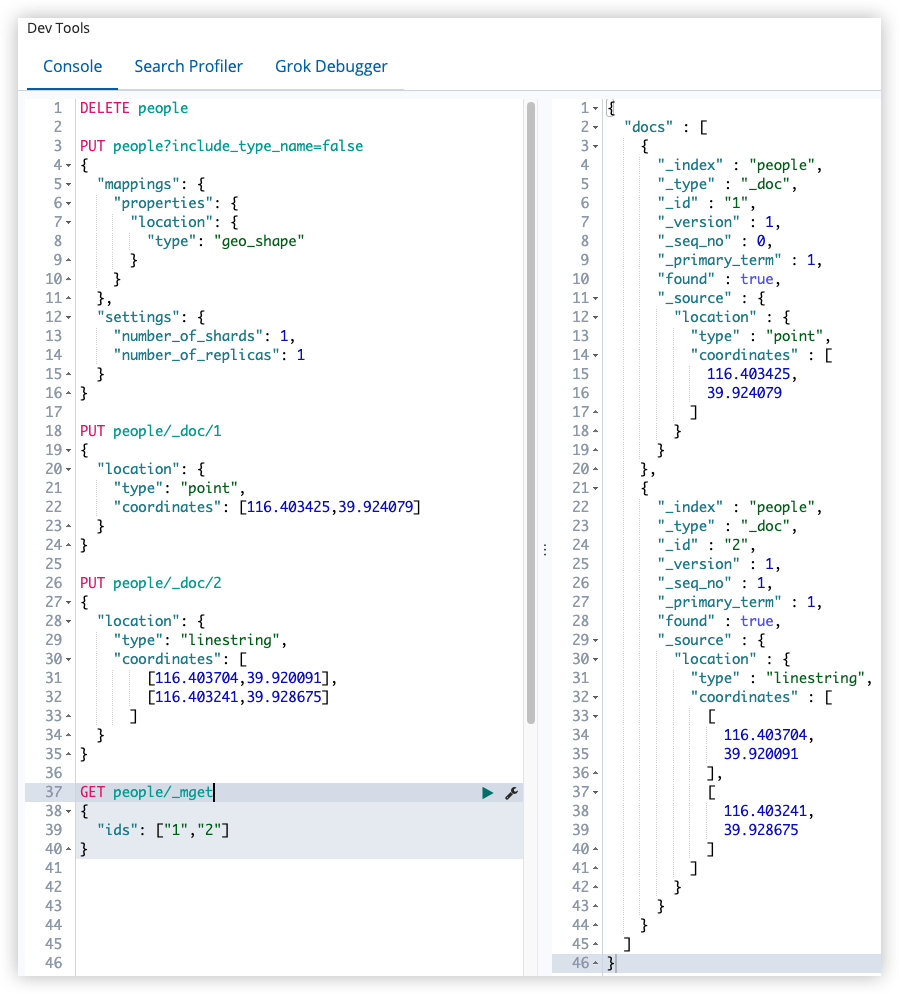
linestring:
1
2
3
4
5
6
7
8
9
10
PUT people/_doc/2
{
"location": {
"type": "linestring",
"coordinates": [
[116.403704,39.920091],
[116.403241,39.928675]
]
}
}
11.4 特殊类型
11.4.1 IP
存储 IP 地址,类型是 ip:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
PUT service?include_type_name=false
{
"mappings": {
"properties": {
"ipAddress": {
"type": "ip"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
添加文档:
1
2
3
4
PUT service/_doc/1
{
"ipAddress": "127.0.0.1"
}
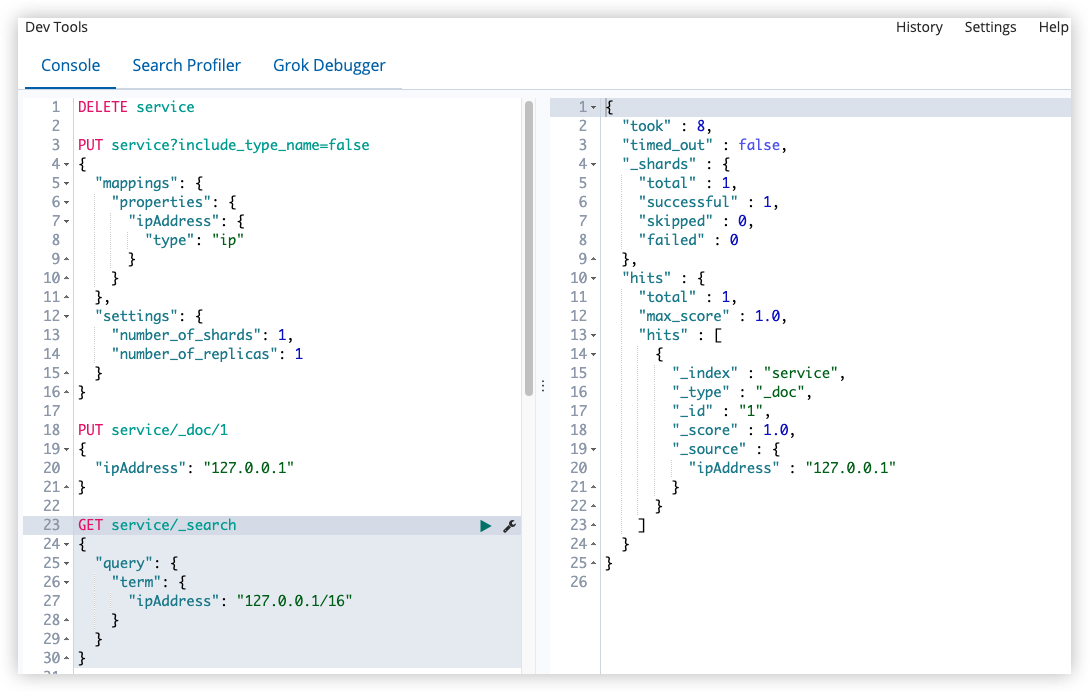
搜索文档:
1
2
3
4
5
6
7
8
GET service/_search
{
"query": {
"term": {
"ipAddress": "127.0.0.1/16"
}
}
}
11.4.2 token_count
用于统计字符串分词后的词项个数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"name": {
"type": "text",
"fields": {
"length": {
"type": "token_count",
"analyzer": "ik_smart"
}
}
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
相当于新增了 name.length 字段用来统计分词后词项的个数
添加文档:
1
2
3
4
PUT book/_doc/1
{
"name": "好诗好在哪里"
}
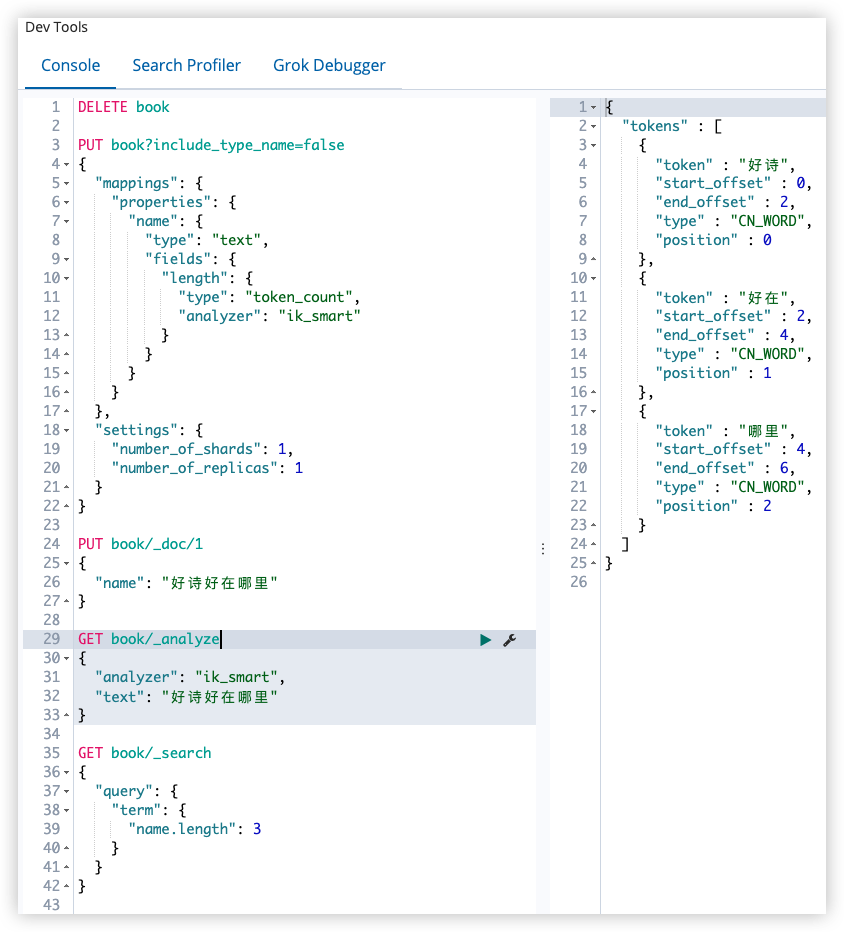
分词查询:
1
2
3
4
5
GET book/_analyze
{
"analyzer": "ik_smart",
"text": "好诗好在哪里"
}
通过 token_count 去查询:
1
2
3
4
5
6
7
8
GET book/_search
{
"query": {
"term": {
"name.length": 3
}
}
}
12 ElasticSearch 映射参数
12.1 analyzer
定义文本字段的分词器。默认情况下,对索引和查询都是有效的。
- 不用分词器
创建索引
1
2
3
4
5
6
7
8
9
10
11
12
13
14
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"name": {
"type": "text"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
添加文档
1
2
3
4
PUT book/_doc/1
{
"name": "好诗好在哪里"
}
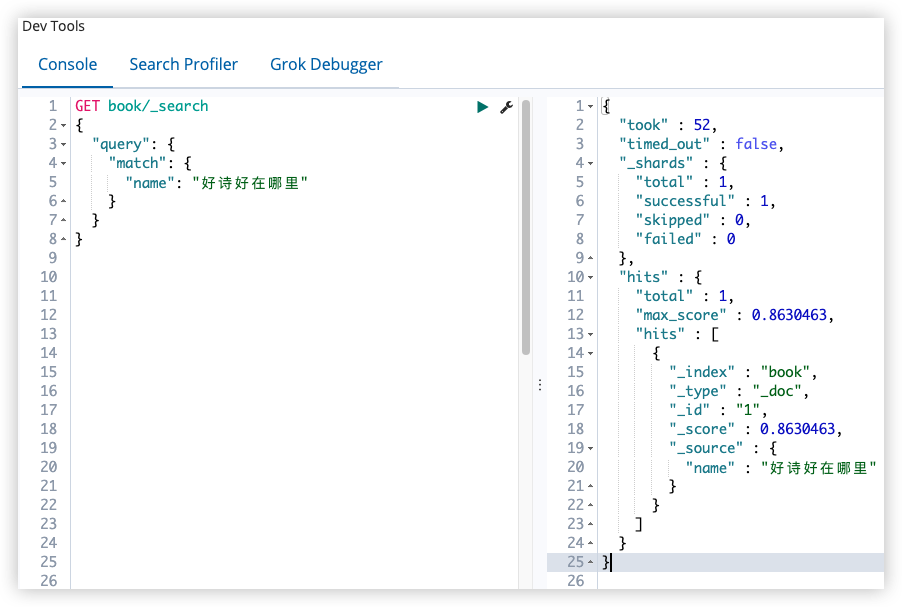
查看词条向量(term vectors)
ES6:
1
2
3
4
GET book/_doc/1/_termvectors
{
"fields": ["name"]
}
ES7:
1
2
3
4
GET book/_termvectors/1
{
"fields": ["name"]
}
查看结果
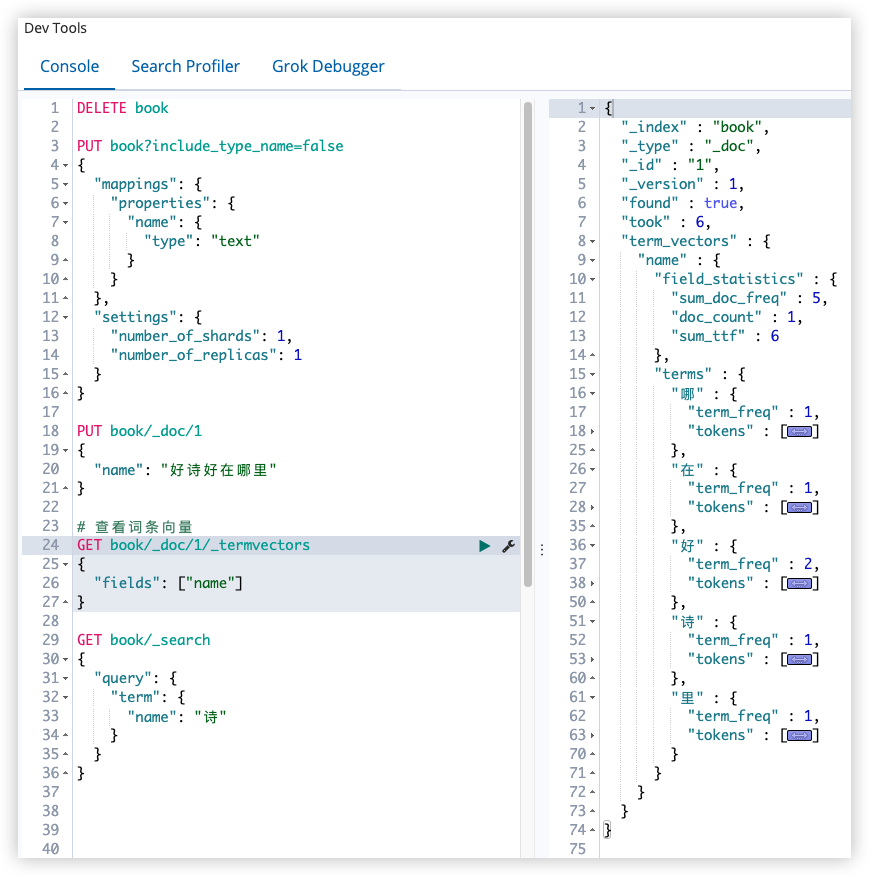
从查看词条向量结果来看,如果不使用分词器,默认是将中文一个字一个字的单独分开,这样搜索就没有了意义,只能通过单个字来搜索。
1
2
3
4
5
6
7
8
GET book/_search
{
"query": {
"term": {
"name": "诗"
}
}
}
- 使用 ik 分词器
创建索引
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_smart"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
添加文档、查看词条向量同上
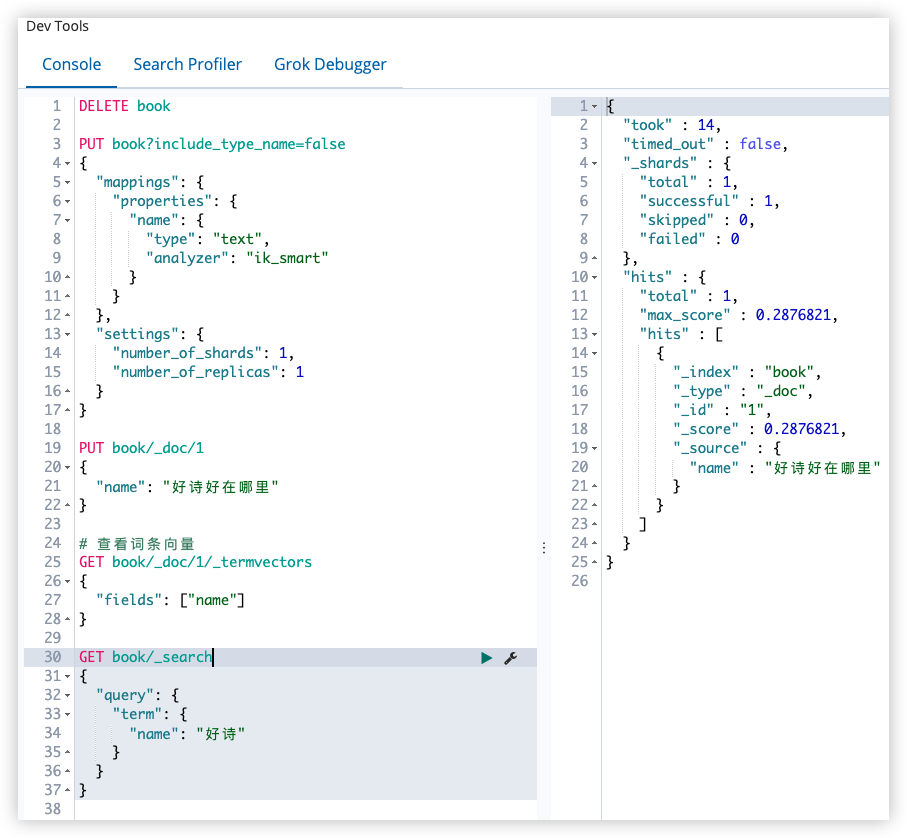
搜索
1
2
3
4
5
6
7
8
GET book/_search
{
"query": {
"term": {
"name": "好诗"
}
}
}
12.2 search_analyzer
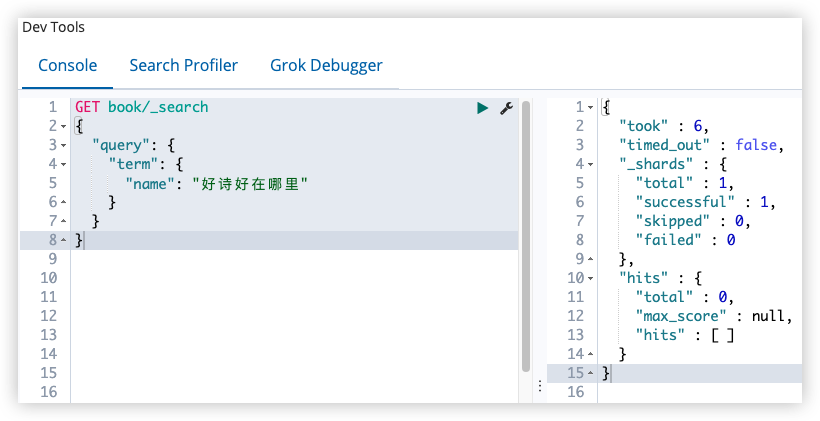
查询时用的分词器。默认情况下,在查询时,首先查看有没有 search_analyzer,如果有,就用 search_analyzer 来进行分词,如果没有,再看有没有 analyzer,如果有,就用 ananlyzer 来进行分词,否则使用 ES 默认分词器。
- 词项匹配
- 全文匹配
12.3 normalizer
normalizer 用于解析前(索引或查询)的标准化配置。
在 ES 中,对于一些不想切分的字符串,通常会将其设置为 keyword 类型,搜索时也是使用整个词进行搜索。如果在索引前没有做好数据清洗,导致大小写不一致,例如 yueyazhui 和 YUEYAZHUI,此时,就可以使用 normalizer 在索引或查询之前进行文档的标准化。
反例:
创建 book 索引,设置 author 字段的类型 keyword
1
2
3
4
5
6
7
8
9
10
11
12
13
14
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"author": {
"type": "keyword"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
添加两个文档
1
2
3
4
5
6
7
8
9
PUT book/_doc/1
{
"author": "yueyazhui"
}
PUT book/_doc/2
{
"author": "YUEYAZHUI"
}
搜索
1
2
3
4
5
6
7
8
GET book/_search
{
"query": {
"term": {
"author": "yueyazhui"
}
}
}
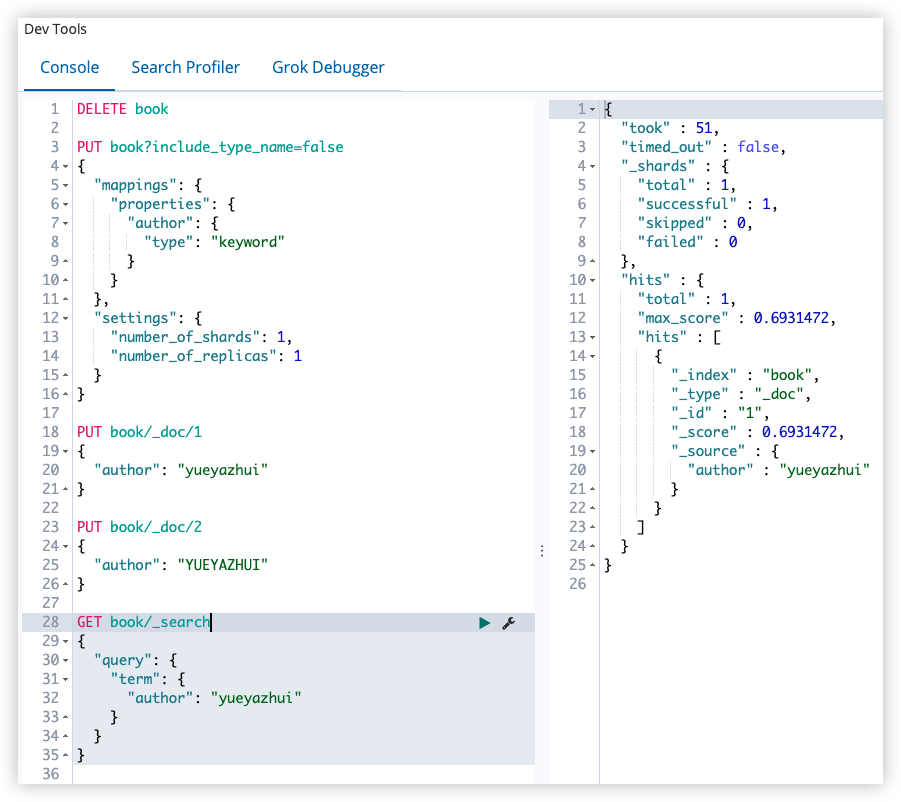
此时搜索是区分大小写的。
如果使用了 normalizer,可以在索引或查询时,分别对文档进行预处理。
正例:
normalizer 定义方式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
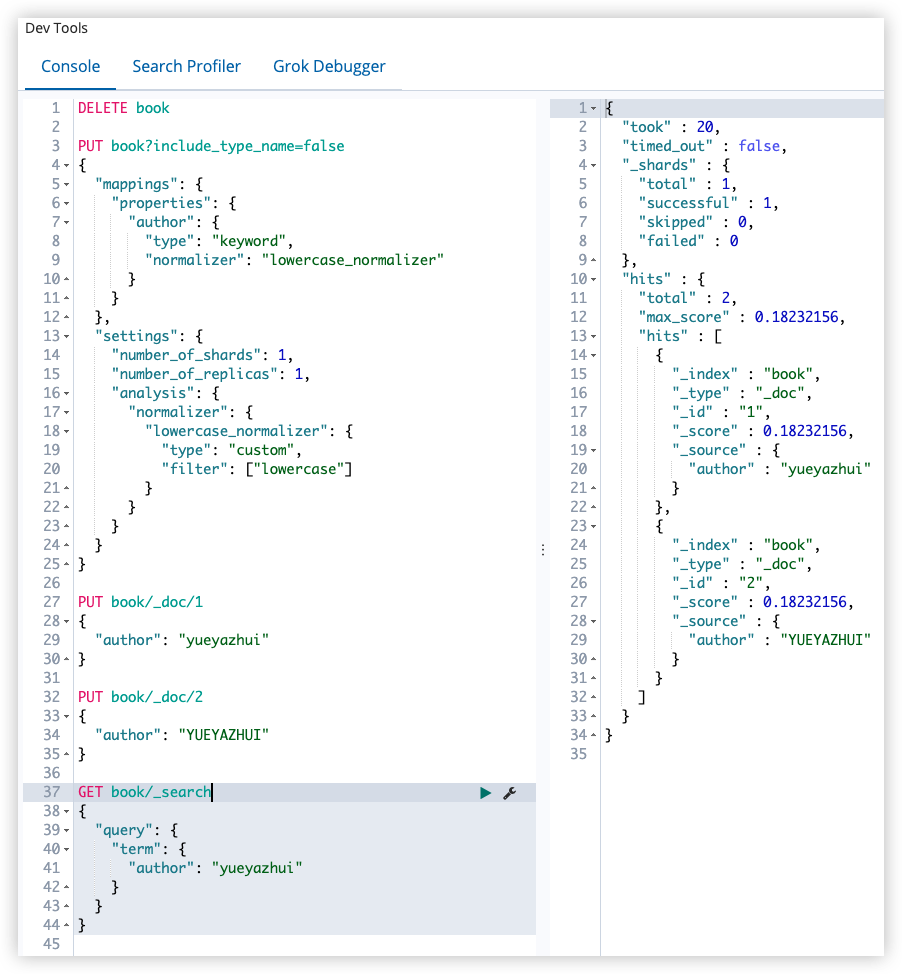
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"author": {
"type": "keyword",
"normalizer": "lowercase_normalizer"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"analysis": {
"normalizer": {
"lowercase_normalizer": {
"type": "custom",
"filter": ["lowercase"]
}
}
}
}
}
在 settings 中定义 normalizer,然后在 mappings 中引用,lowercase_normalizer 这个 key 的名称可以自定义。
测试方式同上,此时查询的时候,就会忽略大小写,因为无论是索引还是查询,都会将大写转为小写。
12.4 boost
boost 参数可以设置字段的权重;boost 默认值为 1。
boost 有两种使用方式,一种是在定义 mappings 指定字段类型时使用;另一种是在查询时使用。
在实际开发中建议使用后者,前者如果不重新索引文档,权重无法修改。
mappings 中指定 boost(不推荐):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"summary": {
"type": "text",
"analyzer": "ik_smart",
"boost": 2
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
在查询时,指定 boost
1
2
3
4
5
6
7
8
9
10
11
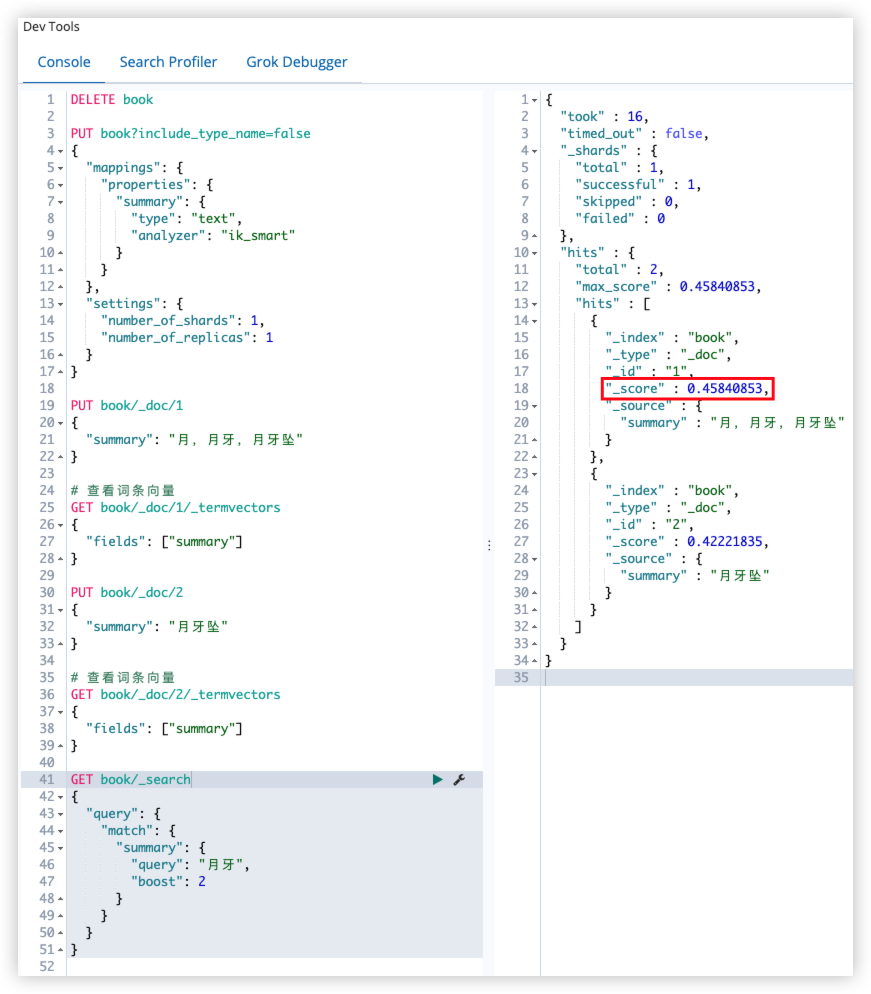
GET book/_search
{
"query": {
"match": {
"summary": {
"query": "月牙",
"boost": 2
}
}
}
}
12.5 coerce
coerce 用来清除脏数据,默认为 true。
例如:在 JSON 中,保存一个不正确的数字类型。
1
{"price":"99.9"}
默认情况下,以上操作没有问题,就是 coerce 起的作用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"price": {
"type": "double"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
PUT book/_doc/1
{
"price": "99.9"
}
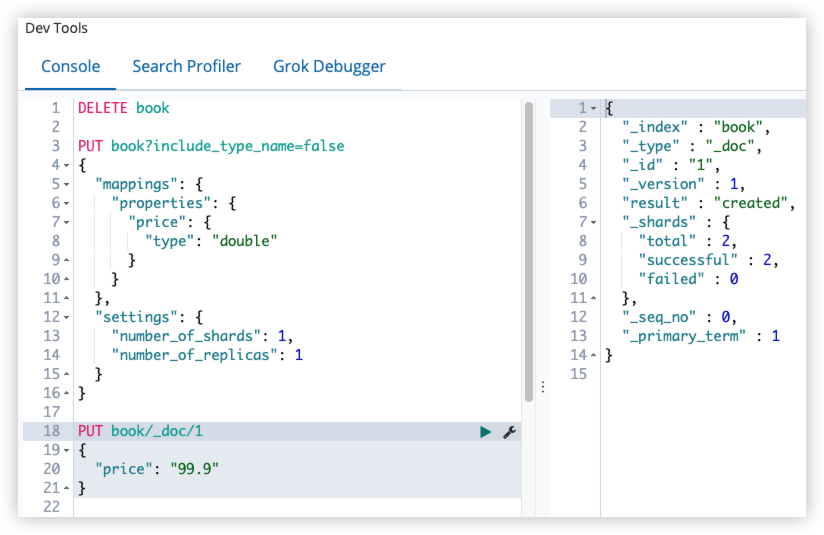
修改 coerce ,方式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"price": {
"type": "double",
"coerce": false
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
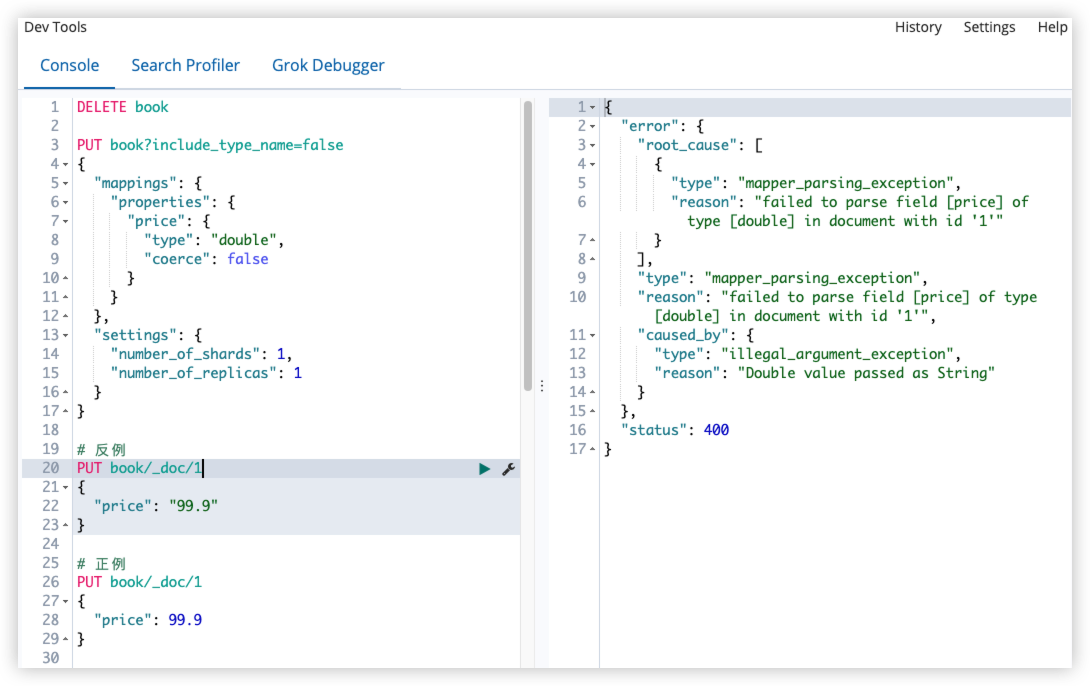
# 反例
PUT book/_doc/1
{
"price": "99.9"
}
# 正例
PUT book/_doc/1
{
"price": 99.9
}
当 coerce 修改为 false 之后,数字类型就只能录入数字,录入字符串会报错。
12.6 copy_to
这个属性,可以将多个字段的值,复制到同一个字段中。
定义方式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"first_name": {
"type": "text",
"analyzer": "ik_smart",
"copy_to": "full_name"
},
"last_name": {
"type": "text",
"analyzer": "ik_smart",
"copy_to": "full_name"
},
"full_name": {
"type": "text",
"analyzer": "ik_smart"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
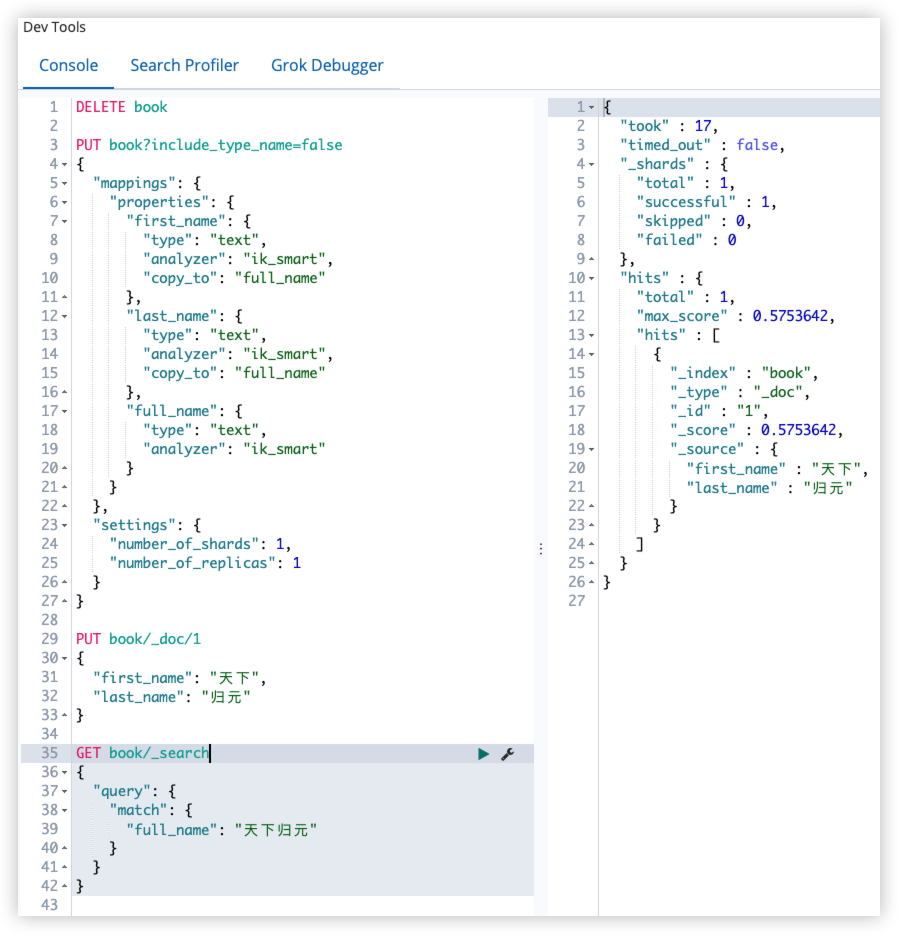
PUT book/_doc/1
{
"first_name": "天下",
"last_name": "归元"
}
GET book/_search
{
"query": {
"match": {
"full_name": "天下归元"
}
}
}
12.7 doc_values 和 fielddata
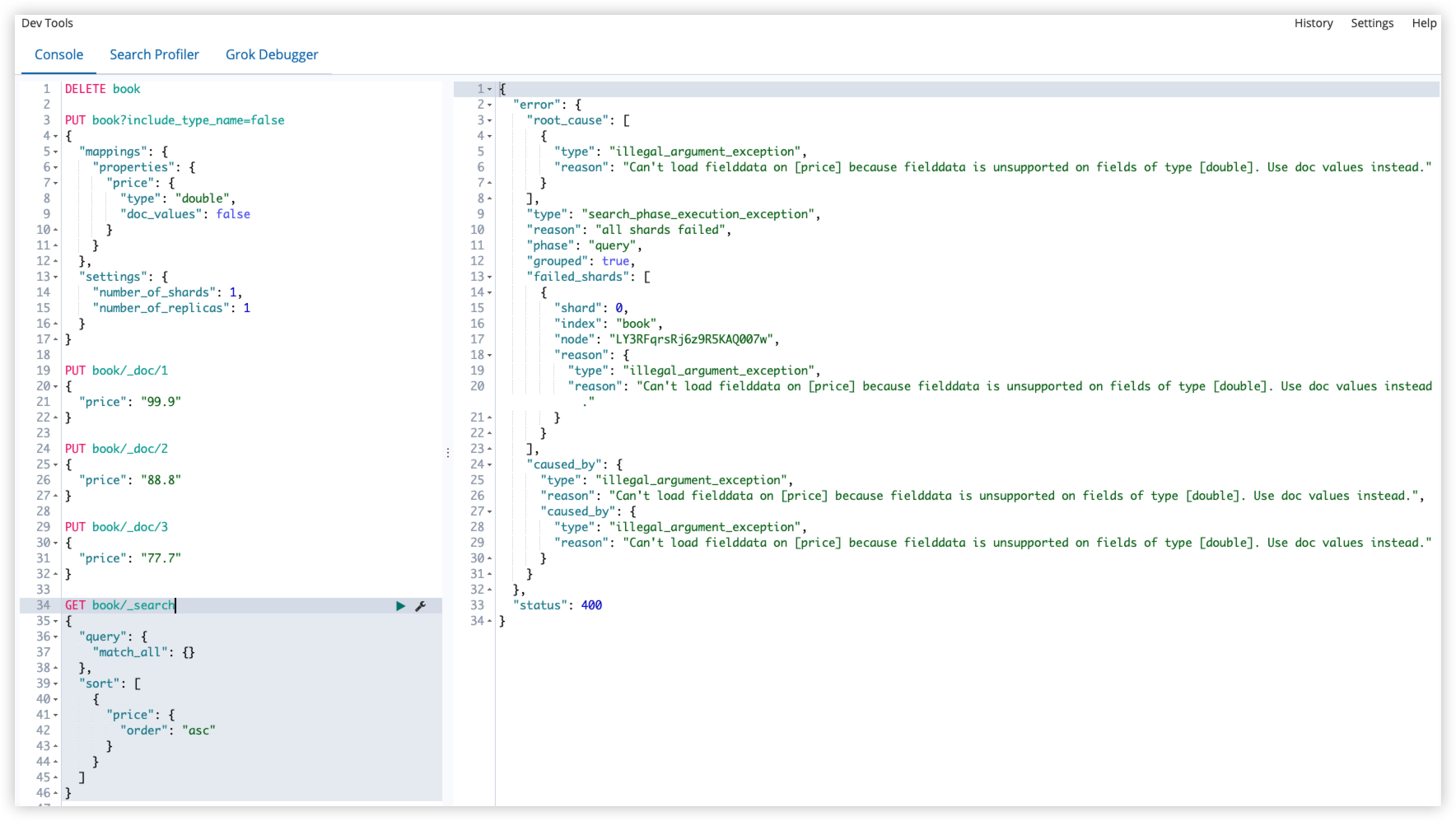
ES 中的搜索主要是用到倒排索引,doc_values 参数是为了加快排序、聚合1操作而生的。当建立倒排索引时,会额外增加列式存储映射。
doc_values 默认是开启的,如果确定某个字段不需要排序或者不需要聚合,那么可以关闭 doc_values,这样可节省空间。
大部分字段在索引时都会生成 doc_values,除了 text 类型的字段。text 类型的字段在查询时会生成一个 fielddata 的数据结构,fieldata 在字段首次被聚合、排序时生成,ES 通过读取磁盘上的倒排记录表,重新生成文档和词项的关系,最后在 Java 堆内存中进行排序。
| doc_values | fielddata |
|---|---|
| 索引时创建 | 使用时动态创建 |
| 磁盘 | 内存 |
| 不占用内存 | 不占用磁盘 |
| 索引速度稍微低一点 | 文档很多时,动态创建慢,占内存 |
doc_values 默认开启,fielddata 默认关闭。
doc_values 演示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"price": {
"type": "double"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
PUT book/_doc/1
{
"price": "99.9"
}
PUT book/_doc/2
{
"price": "88.8"
}
PUT book/_doc/3
{
"price": "77.7"
}
GET book/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"price": {
"order": "asc"
}
}
]
}
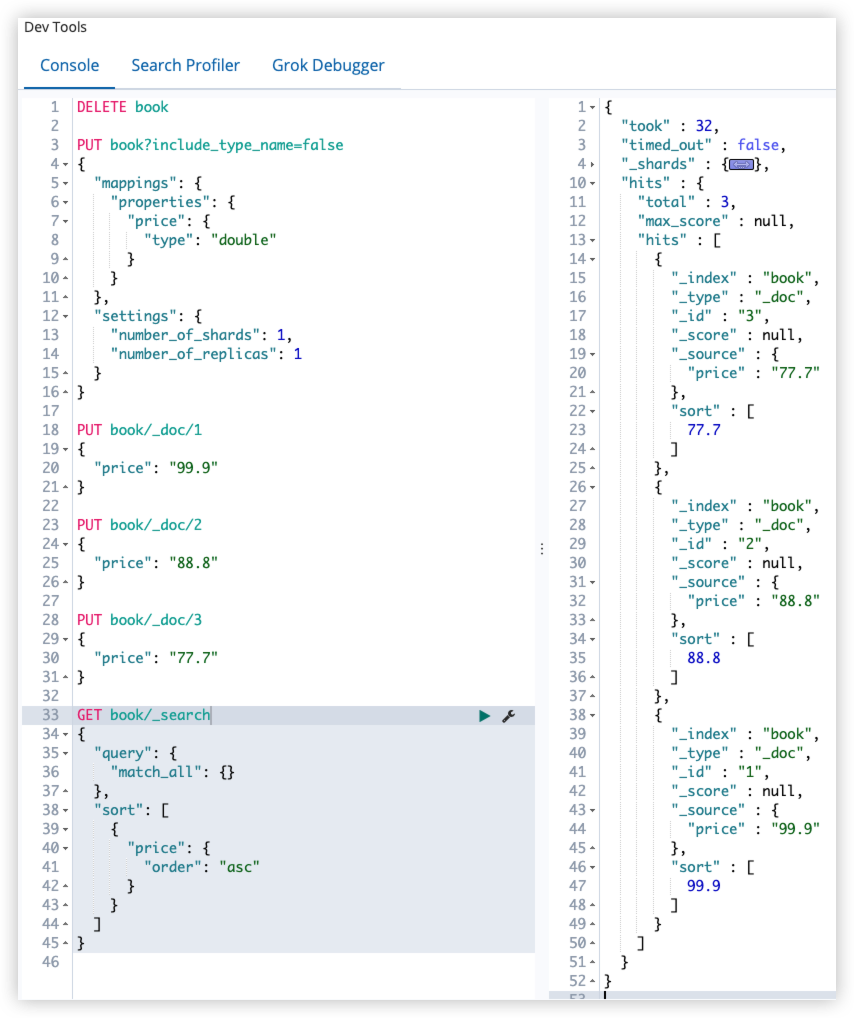
由于 doc_values 默认时开启的,所以可以直接使用该字段进行排序,如果想关闭 doc_values ,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"price": {
"type": "double",
"doc_values": false
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
12.8 dynamic
是否允许添加新字段。
dynamic 属性有三种取值:
- true,默认,自动添加新字段。
- false,忽略新字段。
- strict,严格模式,发现新字段会抛出异常。
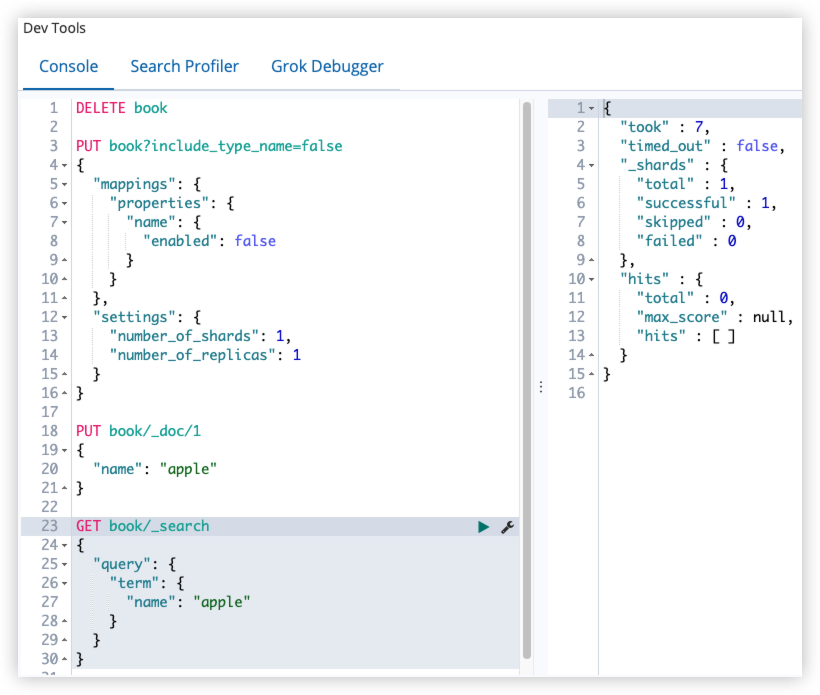
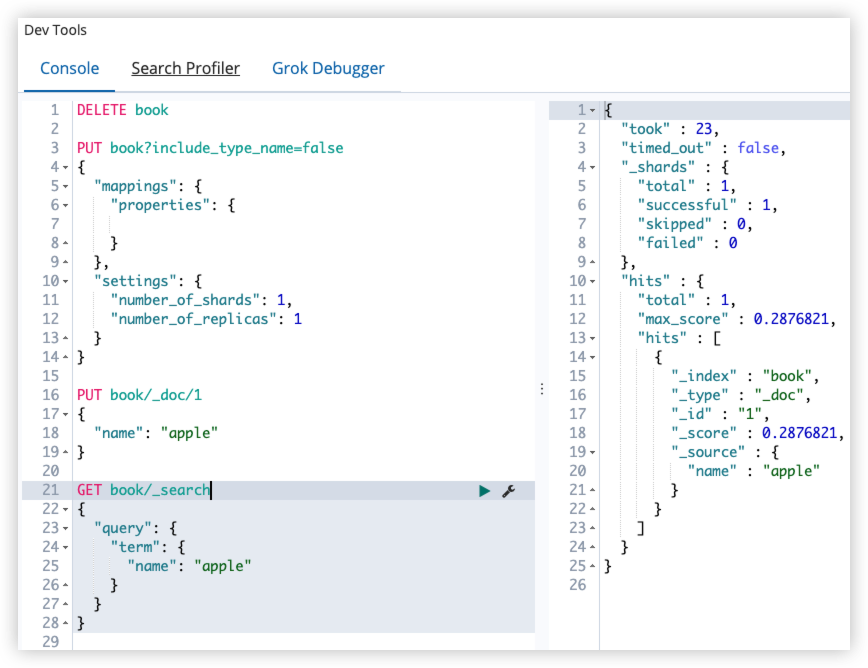
12.9 enabled
ES 默认会索引所有的字段,但是有的字段可能只需要存储,不需要索引。此时可以通过 enabled 字段来控制:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
PUT book?include_type_name=false
{
"mappings": {
"properties": {
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
PUT book/_doc/1
{
"name": "apple"
}
GET book/_search
{
"query": {
"term": {
"name": "apple"
}
}
}
12.10 format
日期格式。format 可以规范日期格式,而且一次可以定义多个 format。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"publishTime": {
"type": "date",
"format": "yyyy-MM-dd||yyyy-MM-dd HH:mm:ss"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
PUT book/_doc/1
{
"publishTime": "2023-11-11"
}
PUT book/_doc/2
{
"publishTime": "2023-11-11 11:11:11"
}
-
多个日期格式之间,使用 符号连接,注意没有空格。 -
如果没有指定 format,默认的日期格式是 strict_date_optional_time epoch_mills
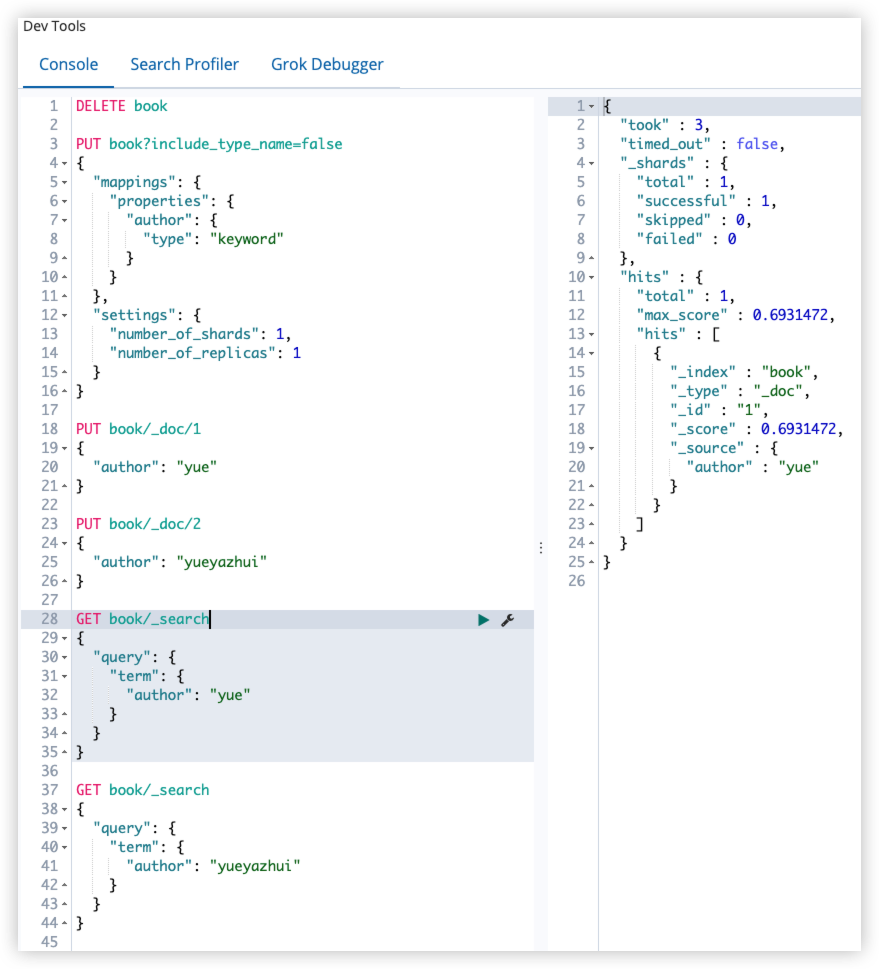
12.11 ignore_above
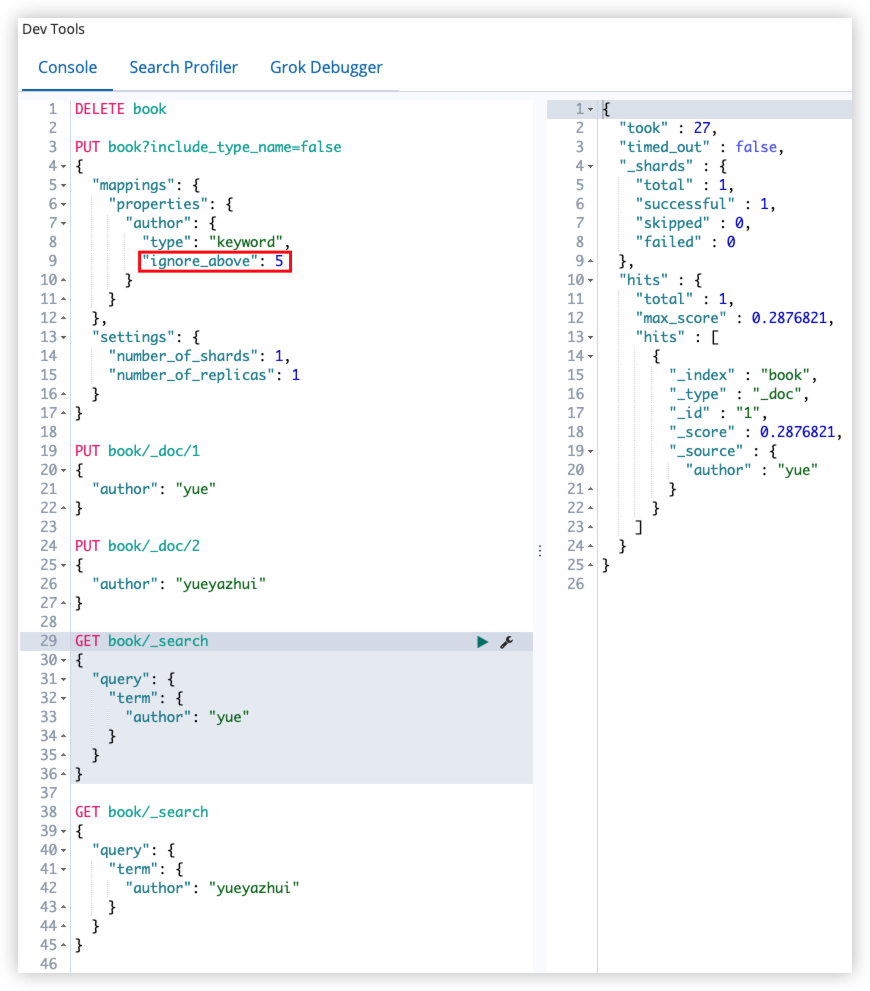
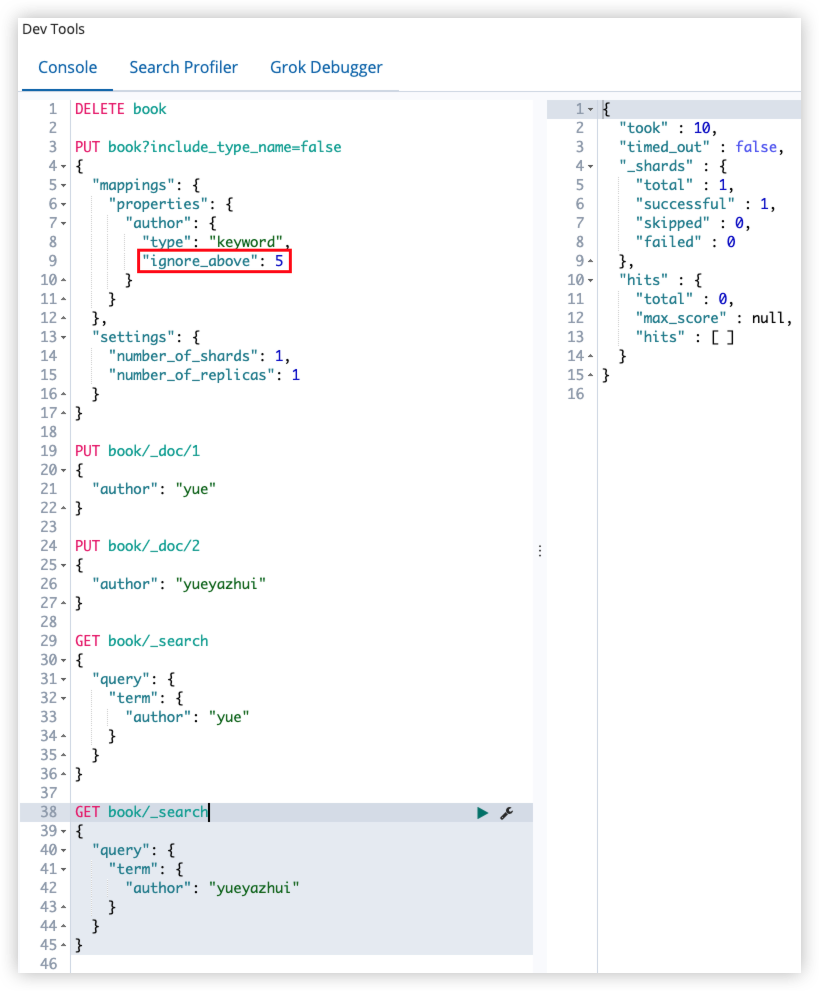
ignore_above 用于指定字符串的最大长度,超过最大长度,该字段将不会被索引,该属性只适用于 keyword 类型。
正例:
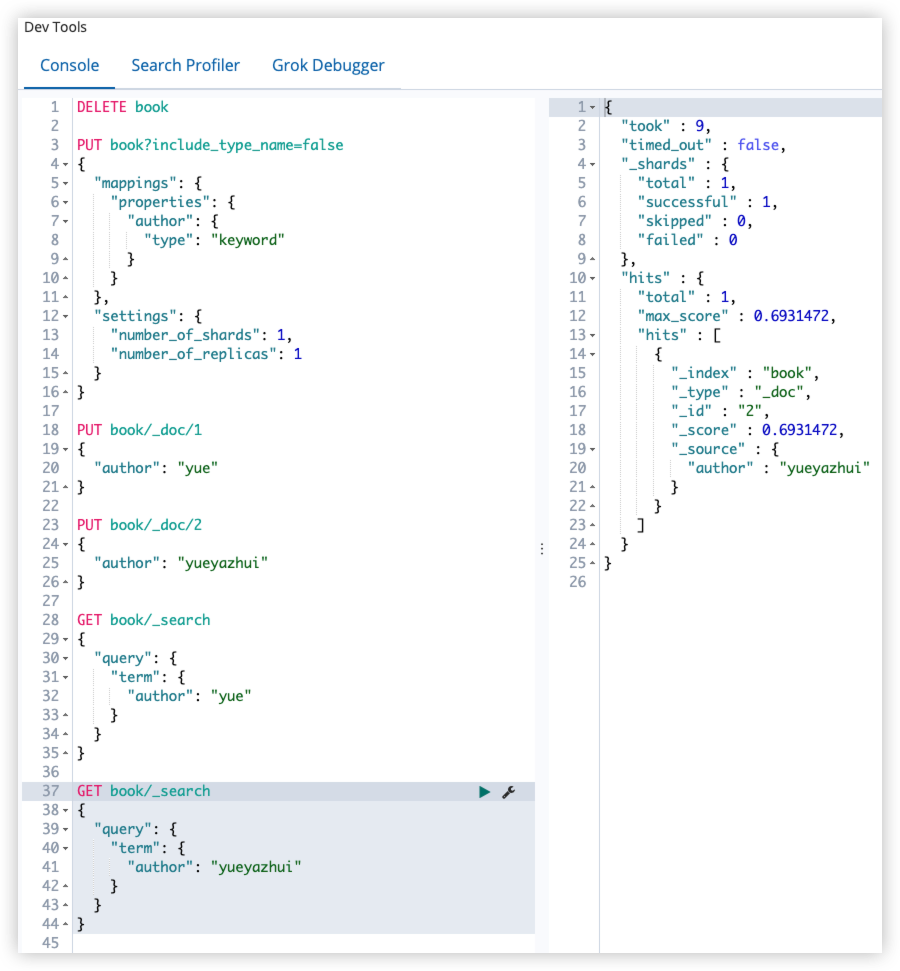
反例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"author": {
"type": "keyword",
"ignore_above": 5
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
PUT book/_doc/1
{
"author": "yue"
}
PUT book/_doc/2
{
"author": "yueyazhui"
}
GET book/_search
{
"query": {
"term": {
"author": "yue"
}
}
}
GET book/_search
{
"query": {
"term": {
"author": "yueyazhui"
}
}
}
12.12 ignore_malformed
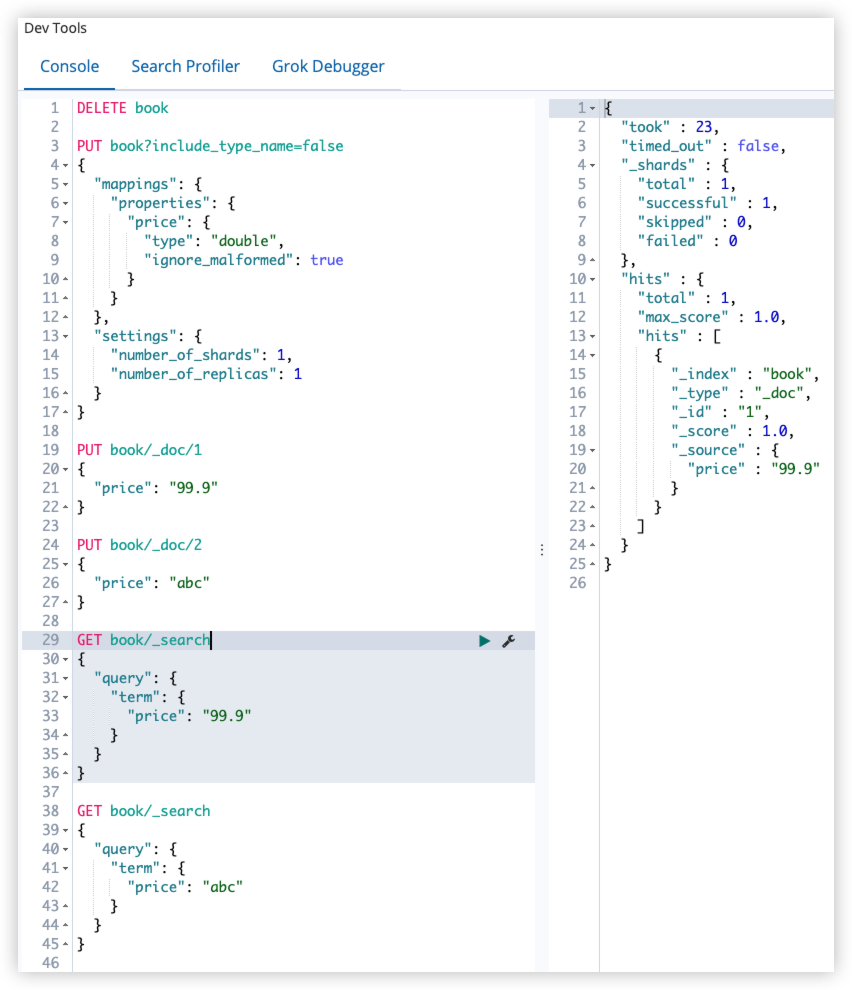
ignore_malformed 可以忽略不规则的数据,该参数默认为 false。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"price": {
"type": "double",
"ignore_malformed": true
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
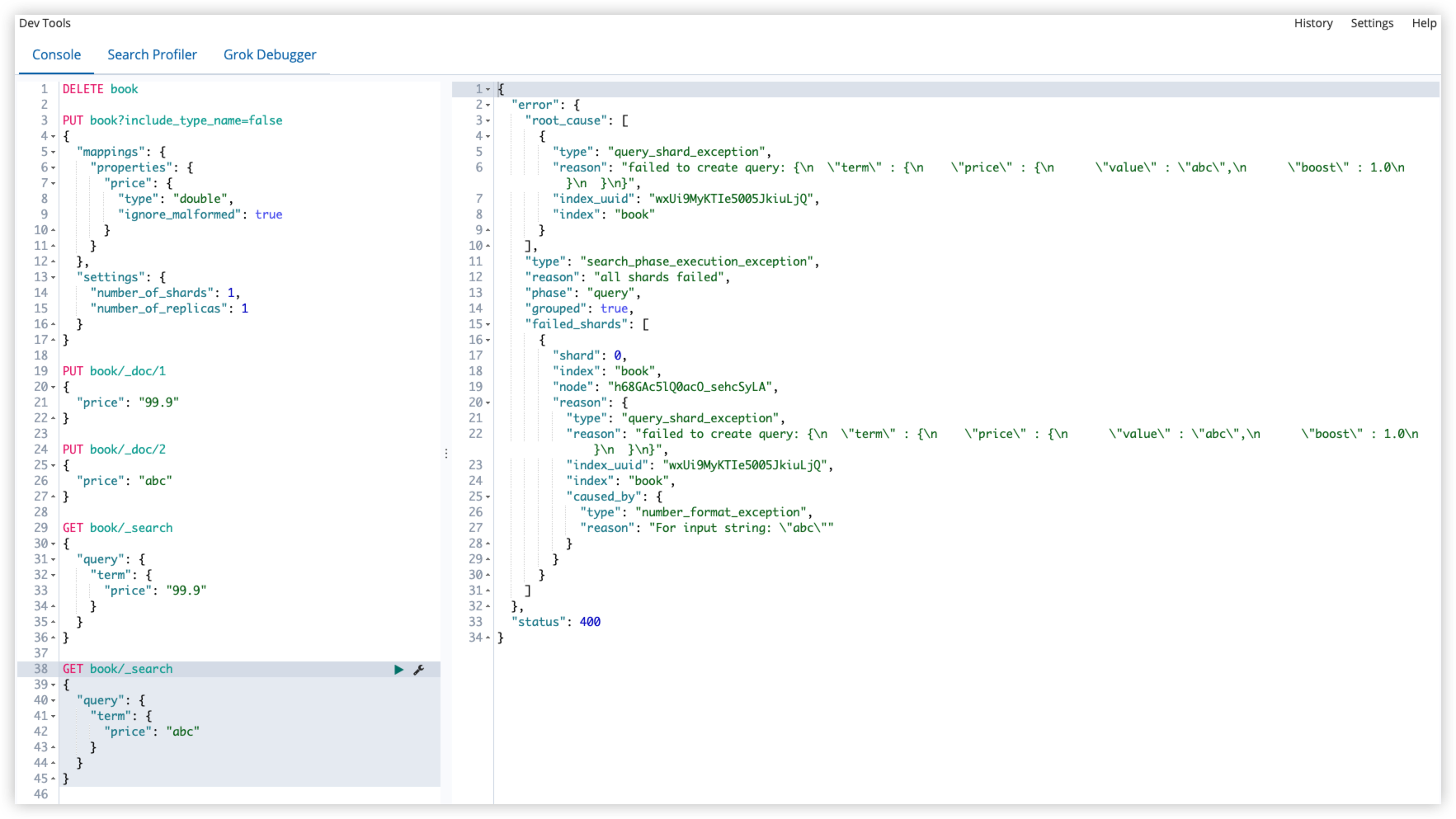
PUT book/_doc/1
{
"price": "99.9"
}
PUT book/_doc/2
{
"price": "abc"
}
GET book/_search
{
"query": {
"term": {
"price": "99.9"
}
}
}
GET book/_search
{
"query": {
"term": {
"price": "abc"
}
}
}
12.13 include_in_all
这个属性是针对_all字段的,但在 ES6 中,这个属性已经被废弃了。
_all和copy_to类似,_all是将所有字段值都保存了。
12.14 index
index 属性指定一个字段是否可以被查询,true 表示可以通过该字段查询(默认),false 表示不可以通过该字段查询。
index:true(默认)
index:false
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"name": {
"type": "text",
"index": false
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
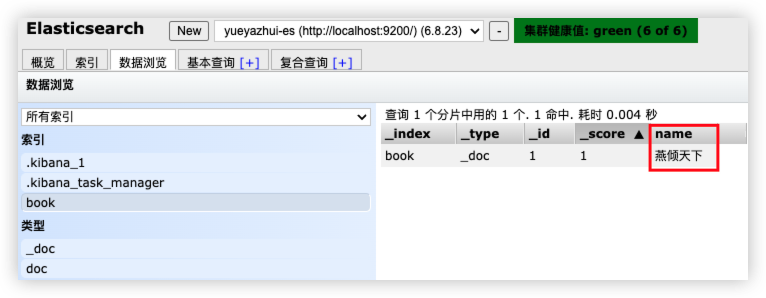
}
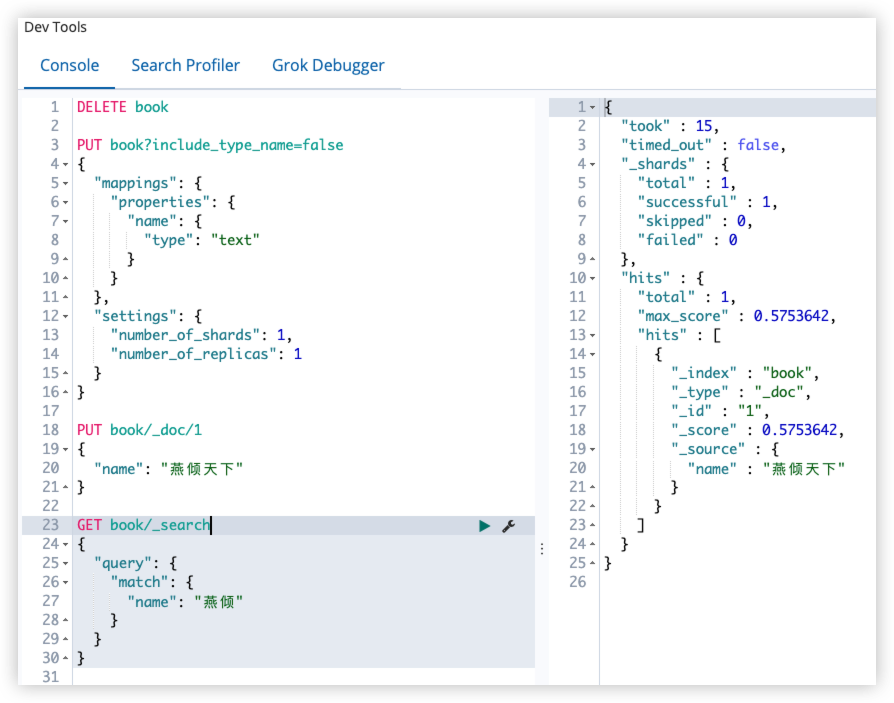
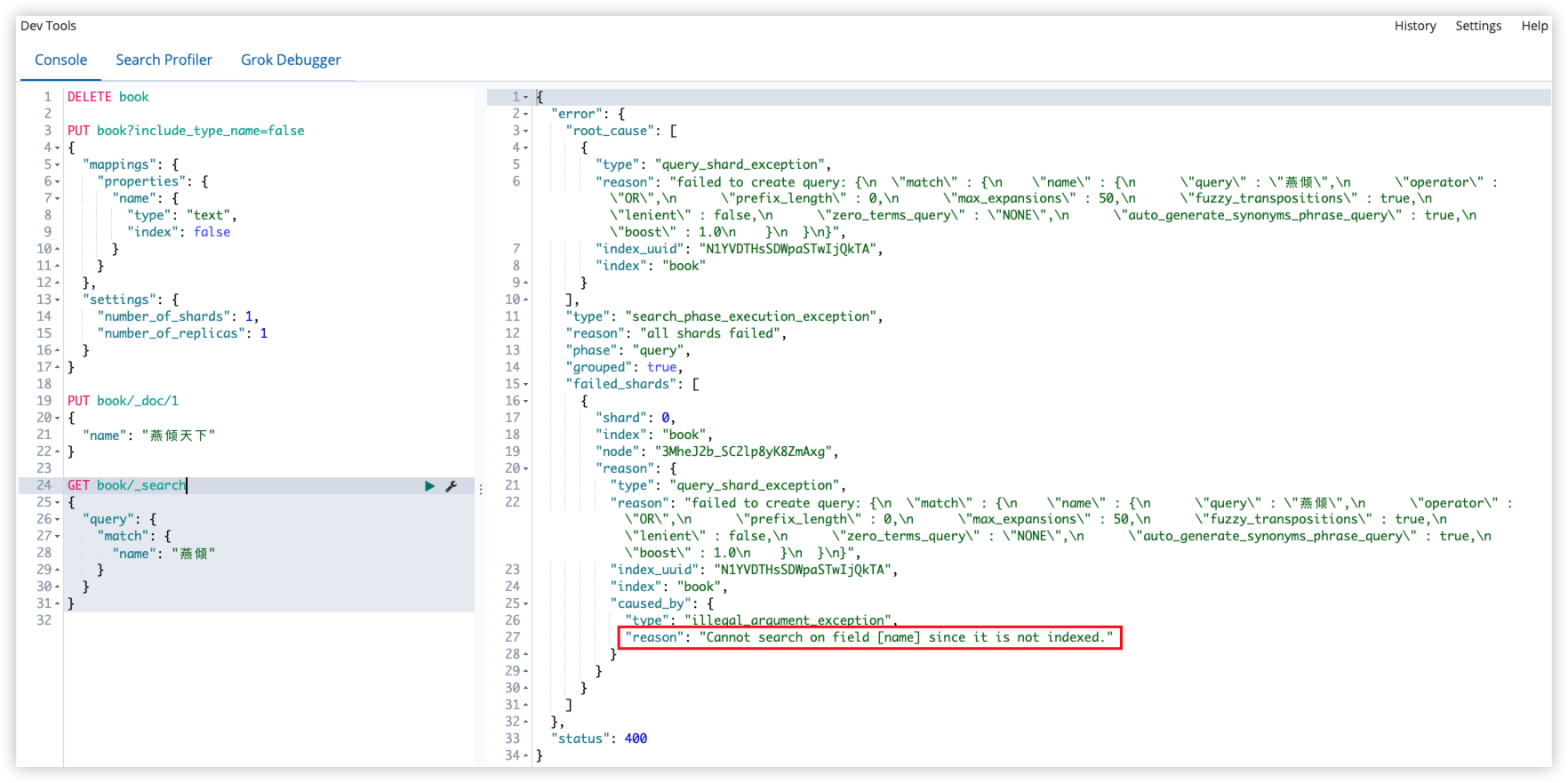
PUT book/_doc/1
{
"name": "燕倾天下"
}
GET book/_search
{
"query": {
"match": {
"name": "燕倾"
}
}
}
12.15 index_options
index_options 控制索引时哪些信息被存储到倒排索引中(用在 text 类型的字段中),有四种取值:
| index_options | 备注 |
|---|---|
| docs | 只存储文档编号(默认) |
| freqs | 在 docs 基础上,存储词项频率 |
| positions | 在 freqs 基础上,存储词项偏移位置 |
| offsets | 在 positions 基础上,存储词项开始和结束的字符位置 |
12.16 norms
norms 作用于字段评分,对于 text 类型的字段该属性默认是开启的;对于其他类型,如果不是特别需要,不要开启该属性,该属性会严重消耗磁盘空间。
除 text 类型之外的其他类型一般用 doc_values 进行排序、聚合等操作。
12.17 null_value
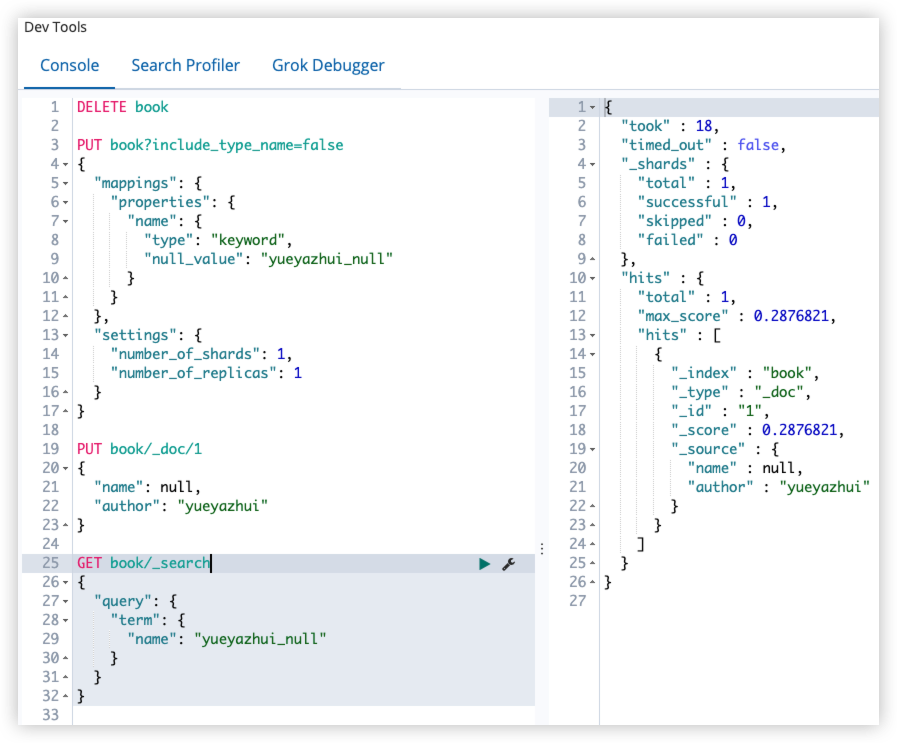
在 ES 中,值为 null 的字段不可以索引也不可以搜索,null_value 属性可以让值为 null 的字段可索引、可搜索;简单来说就是用一个值来代替 null。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"name": {
"type": "keyword",
"null_value": "yueyazhui_null"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
PUT book/_doc/1
{
"name": null,
"author": "yueyazhui"
}
GET book/_search
{
"query": {
"term": {
"name": "yueyazhui_null"
}
}
}
12.18 position_increment_gap
在 ES 中,解析 text 类型字段时,会将 term 的位置考虑进去,目的是为了支持近似查询和短语查询,当索引一个含有多个值的 text 类型字段时,会在各个值之间添加一个假想的空间,将值隔开,这样就可以有效避免一些无意义的短语匹配,间隙大小通过 position_increment_gap 属性来控制,默认是 100。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"name": {
"type": "text"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
PUT book/_doc/1
{
"name": ["天下归元","步非烟"]
}
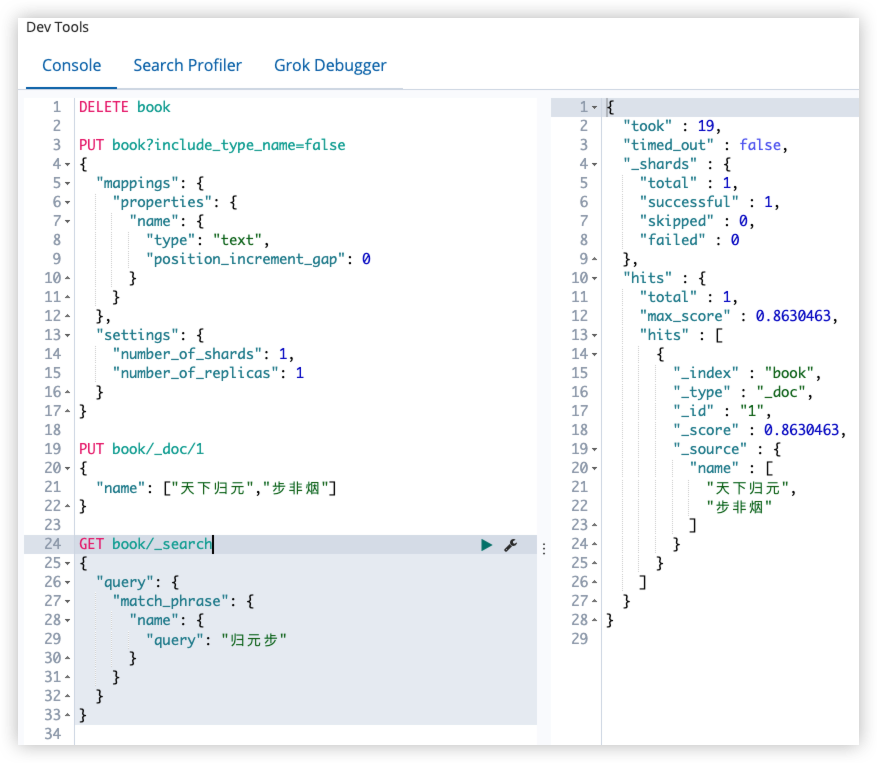
GET book/_search
{
"query": {
"match_phrase": {
"name": {
"query": "归元步"
}
}
}
}
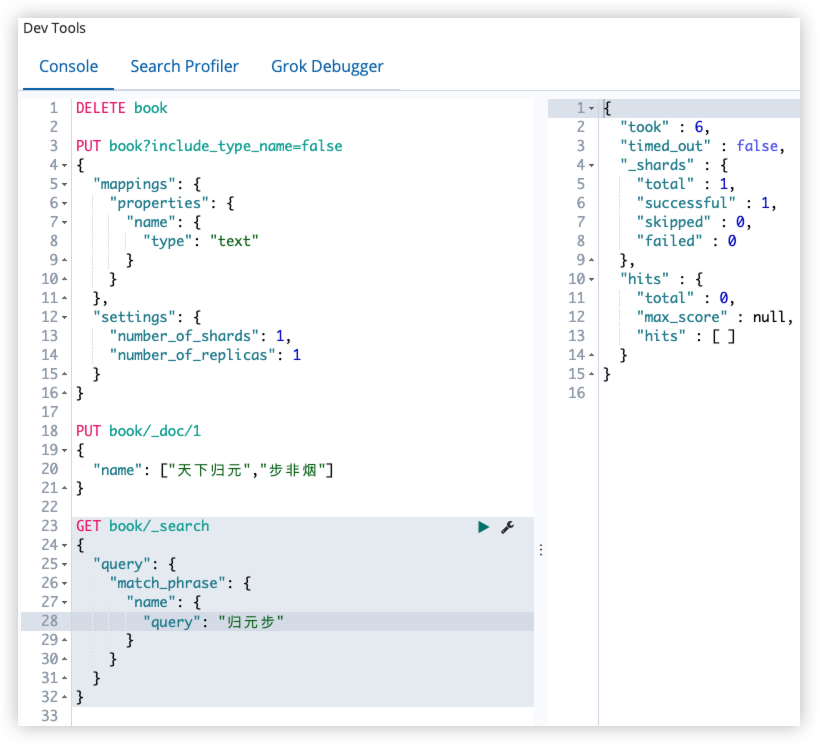
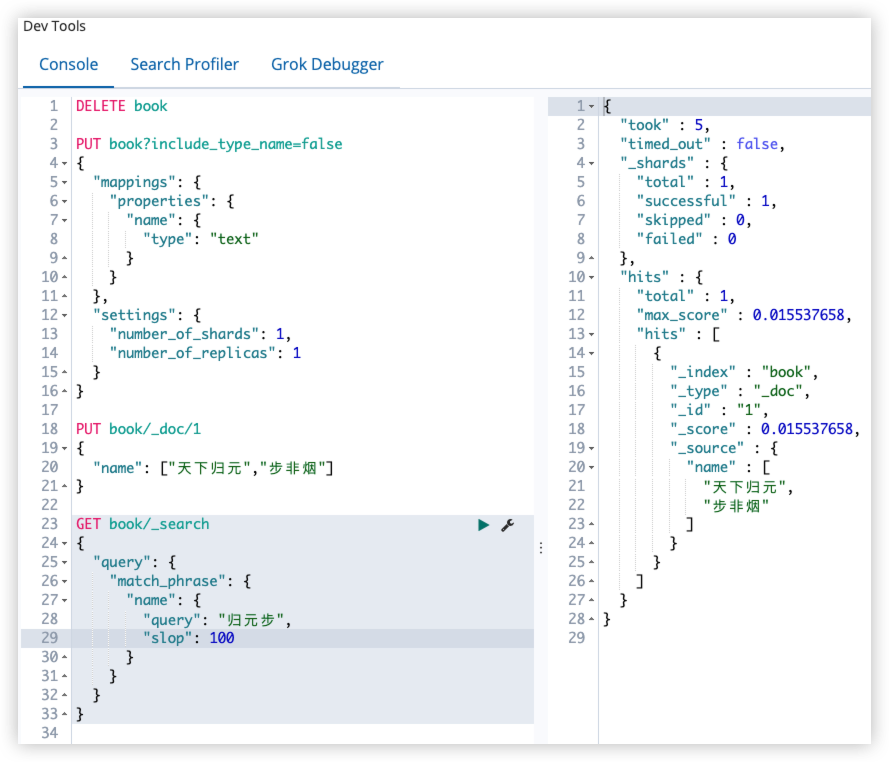
归元步搜索不到,因为天下归元和步非烟这两个短语之间有一个假想的空隙,默认 100。
1
2
3
4
5
6
7
8
9
10
11
GET book/_search
{
"query": {
"match_phrase": {
"name": {
"query": "归元步",
"slop": 100
}
}
}
}
- 通过 slop 指定空隙大小。
- 在定义索引时,指定空隙:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"name": {
"type": "text",
"position_increment_gap": 0
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
PUT book/_doc/1
{
"name": ["天下归元","步非烟"]
}
GET book/_search
{
"query": {
"match_phrase": {
"name": {
"query": "归元步"
}
}
}
}
12.19 properties
properties 属性可指定字段及字段的属性。
12.20 similarity
similarity 指定文档的评分模型,默认有三种:
| similarity | 备注 |
|---|---|
| BM25 | ES 和 Lucene 默认的评分模型 |
| classic | TF/IDF 评分 |
| boolean | boolean 模型评分 |
12.21 store
默认情况下,字段可以被索引,也可以被搜索,但不会被存储。(在_source中有一个字段的备份)
如果需要将字段存储下来,可以通过配置 store 属性来实现。
12.22 term_vectors
term_vectors 是通过分词器产生的信息,包括:
- 一组词根(trem)
- 每个 term 的位置
- term 的首字符/尾字符与原始字符串原点的偏移量
term_vectors 取值:
| 取值 | 备注 |
|---|---|
| no | 不存储信息(默认) |
| yes | term 被存储 |
| with_positions | 在 yes 的基础上增加位置信息 |
| with_offset | 在 yes 的基础上增加偏移信息 |
| with_positions_offsets | term、位置、偏移量都存储 |
12.23 fields
fields 属性可以让同一个字段有多种不同的索引方式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
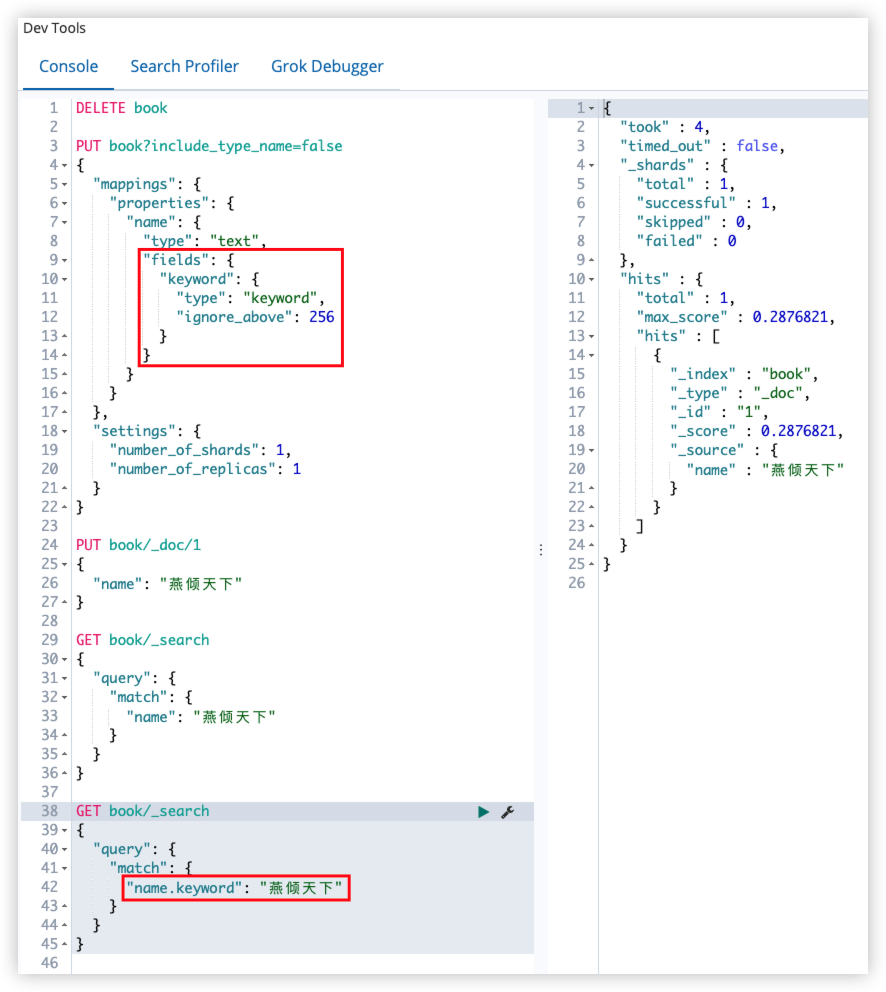
PUT book/_doc/1
{
"name": "燕倾天下"
}
GET book/_search
{
"query": {
"match": {
"name": "燕倾天下"
}
}
}
GET book/_search
{
"query": {
"match": {
"name.keyword": "燕倾天下"
}
}
}
13 ElasticSearch 映射模版
ES 中有动态映射,但有时候默认的动态映射规则并不能满足需求,这时候可以通过映射模版来解决。
例:(动态映射)
1
2
3
4
5
6
7
8
9
10
11
12
PUT book?include_type_name=false
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
PUT book/_doc/1
{
"page": 704
}
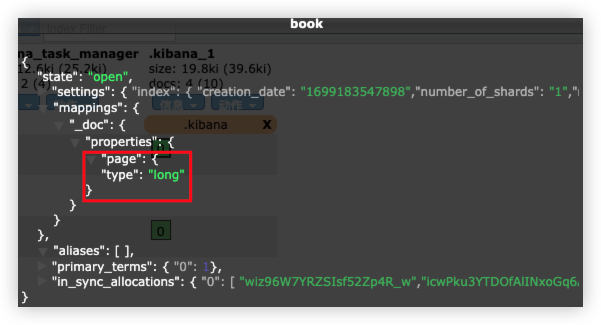
例:(映射模版)
- 将所有的 long 类型映射为 integer 类型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
PUT book?include_type_name=false
{
"mappings": {
"dynamic_templates": [
{
"long2integer": {
"match_mapping_type": "long",
"mapping": {
"type": "integer"
}
}
}
]
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
PUT book/_doc/1
{
"page": 704
}
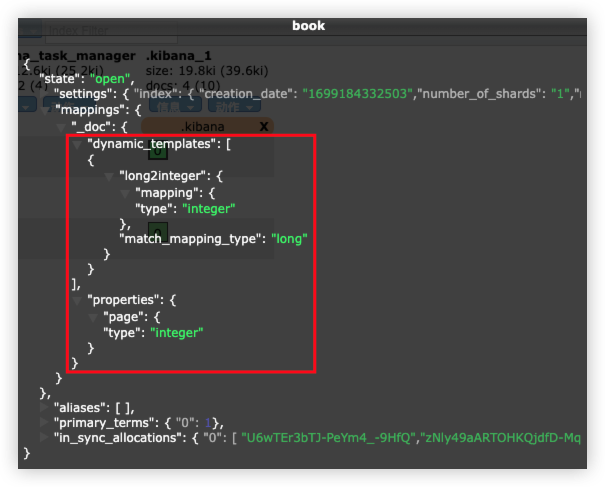
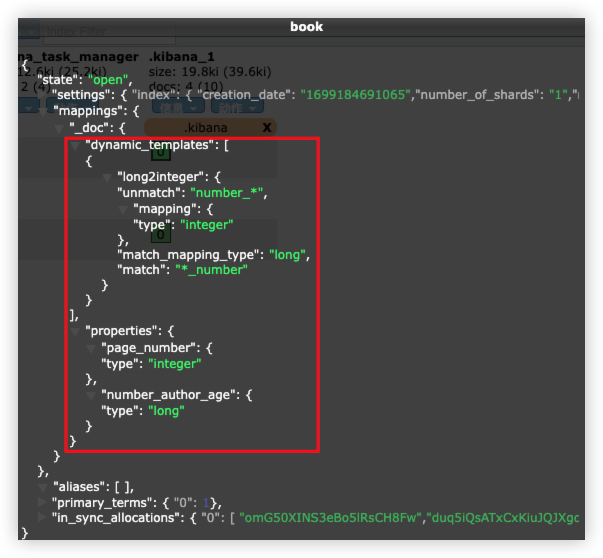
- 将匹配到的 long 类型映射为 integer 类型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
PUT book?include_type_name=false
{
"mappings": {
"dynamic_templates": [
{
"long2integer": {
"match_mapping_type": "long",
"match": "*_number",
"unmatch": "number_*",
"mapping": {
"type": "integer"
}
}
}
]
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
PUT book/_doc/1
{
"page_number": 704,
"number_author_age": 43
}
14 ElasticSearch 搜索入门
搜索是 ES 最为丰富有趣的功能,其中包含全文查询、词项查询、复合查询、嵌套查询、位置查询、特殊查询等多个方面。
14.1 搜索数据导入
下载数据 book.json,数据来源于豆瓣图书
字段没有删减,如果想去除部分字段,请在项目的 top.yueyazhui.module.douban.DoubanReadTests#generateBookJsonData 方法中进行处理
创建索引:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"cover": {
"type": "keyword"
},
"url": {
"type": "keyword"
},
"isBundle": {
"type": "boolean"
},
"coverLabel": {
"type": "keyword"
},
"author": {
"type": "nested",
"properties": {
"name": {
"type": "keyword"
},
"url": {
"type": "keyword"
}
}
},
"origAuthor": {
"type": "nested",
"properties": {
"name": {
"type": "keyword"
},
"url": {
"type": "keyword"
}
}
},
"translator": {
"type": "nested",
"properties": {
"name": {
"type": "keyword"
},
"url": {
"type": "keyword"
}
}
},
"abstract": {
"type": "text",
"analyzer": "ik_max_word"
},
"authorHighlight": {
"type": "object"
},
"editorHighlight": {
"type": "object"
},
"isOrigin": {
"type": "boolean"
},
"kinds": {
"type": "nested",
"properties": {
"shortName": {
"type": "text",
"analyzer": "ik_max_word"
},
"id": {
"type": "integer"
}
}
},
"wordCount": {
"type": "integer"
},
"wordCountUnit": {
"type": "keyword"
},
"isColumn": {
"type": "boolean"
},
"highlightTags": {
"type": "nested"
},
"copyrightInfo": {
"type": "object",
"properties": {
"newlyAdapted": {
"type": "boolean"
},
"newlyPublished": {
"type": "boolean"
},
"adaptedName": {
"type": "keyword"
},
"publishedName": {
"type": "keyword"
}
}
},
"isInLibrary": {
"type": "boolean"
},
"fixedPrice": {
"type": "scaled_float",
"scaling_factor": 100
},
"salesPrice": {
"type": "scaled_float",
"scaling_factor": 100
},
"isRebate": {
"type": "boolean"
},
"id": {
"type": "keyword"
},
"isPurchased": {
"type": "boolean"
},
"isInWishlist": {
"type": "boolean"
},
"isEssay": {
"type": "boolean"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
执行导入命令:
1
curl -XPOST "http://localhost:9200/book/_bulk?pretty" -H "content-type:application/json" --data-binary @book.json
14.2 搜索入门
搜索分为两个过程:
- 当向索引中保存文档时,默认情况下,ES 会保存两份内容,一份是
_source中的数据,另一份则是通过分词、排序等一系列操作生成的倒排索引文件,倒排索引中保存了词项和文档之间的对应关系。 - 搜索时,当 ES 接收到搜索请求后,会去倒排索引中查询,通过倒排索引中维护的倒排记录表找到关键词对应的文档集合,然后对文档进行评分、排序、高亮等处理,最后将文档返回。
14.2.1 简单搜索
查询所有文档(match_all):
1
2
3
4
5
6
GET book/_search
{
"query": {
"match_all": {}
}
}
查询结果如下:
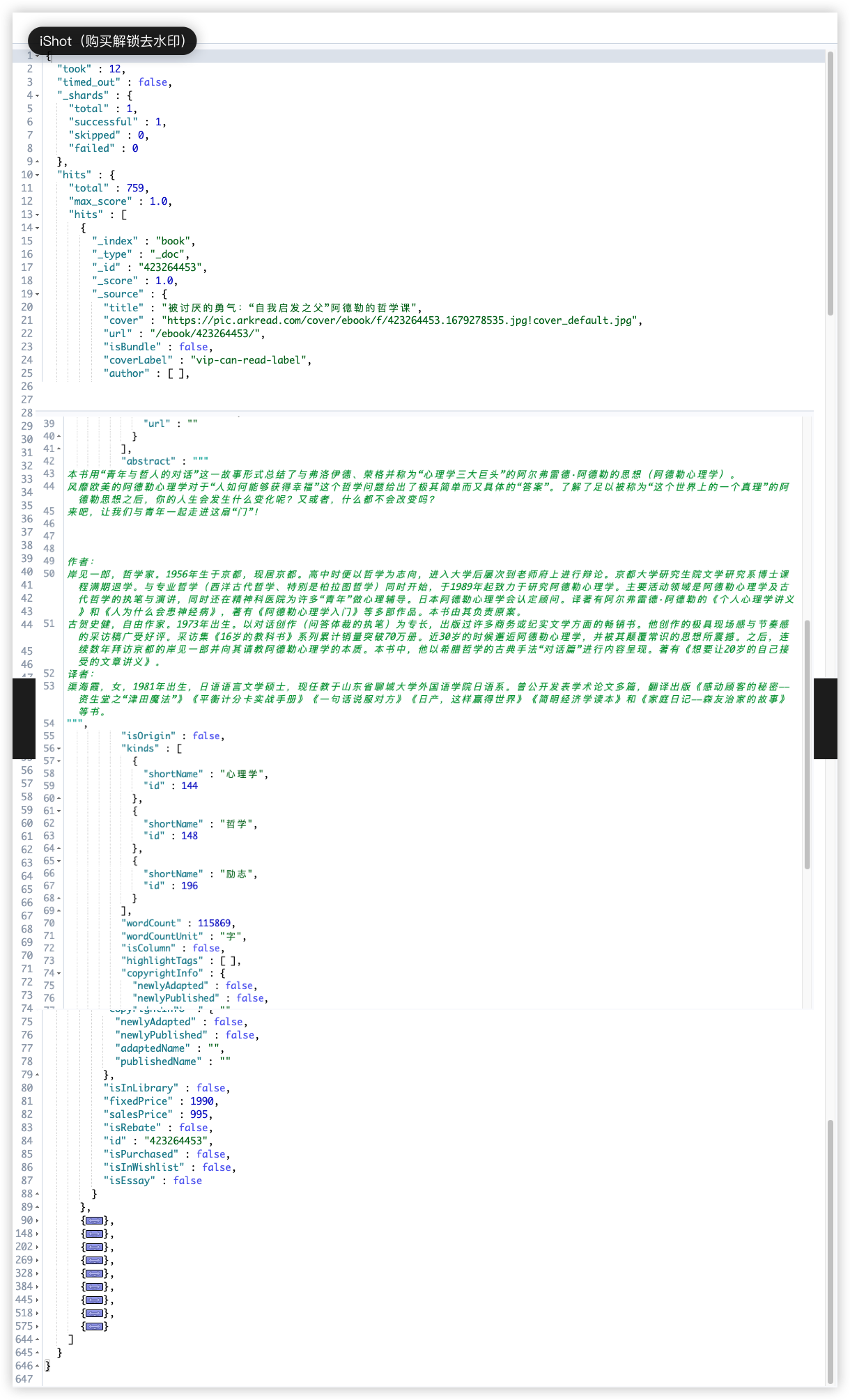
hits 中的就是查询结果,total 是符合查询条件的文档总数。
简单搜索可以简写为:
1
GET book/_search
简单搜索默认查询 10 条记录。
14.2.2 词项查询
词项查询(term),根据词项去查询,查询指定字段中包含给定词项的文档,term 查询不被解析,只有搜索的词和文档中的词精确匹配,才会返回文档。应用场景:人名、地名等。
查询 title 字段中包含 明朝 的文档。
1
2
3
4
5
6
7
8
GET book/_search
{
"query": {
"term": {
"title": "明朝"
}
}
}
14.2.3 分页
默认返回前 10 条数据,在 ES 中也可以像关系型数据库一样,给一个分页参数:
1
2
3
4
5
6
7
8
9
10
GET book/_search
{
"query": {
"term": {
"title": "明朝"
}
},
"size": 2,
"from": 0
}
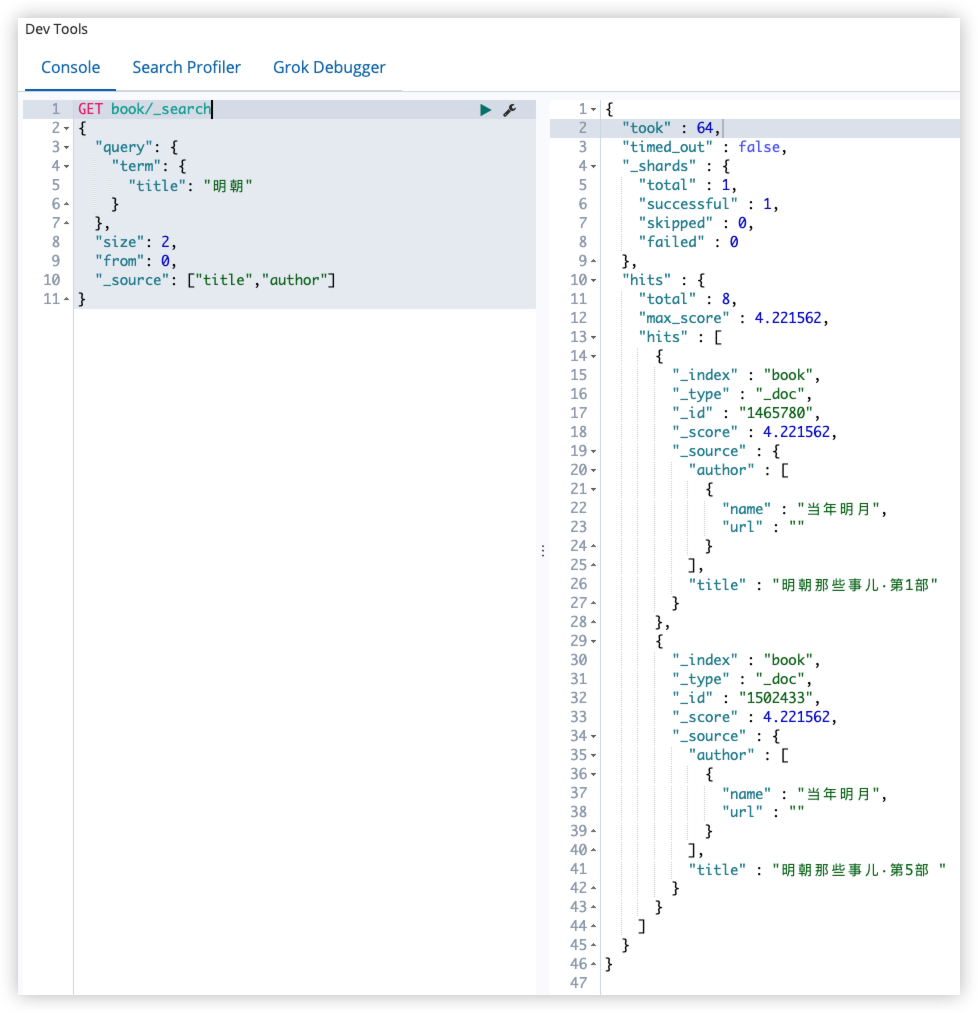
14.2.4 过滤返回字段
指定返回的字段:
1
2
3
4
5
6
7
8
9
10
11
GET book/_search
{
"query": {
"term": {
"title": "明朝"
}
},
"size": 2,
"from": 0,
"_source": ["title","author"]
}
此时,返回的字段就只剩下 title 和 author 了。
14.2.5 最小评分
有的文档得分特别低,说明这个文档和查询关键字的相关度很低。设置一个最低分,只有得分超过最低分的文档才会被返回。
1
2
3
4
5
6
7
8
9
10
GET book/_search
{
"query": {
"term": {
"title": "明朝"
}
},
"min_score": 4.22,
"_source": ["title","author"]
}
得分低于 4.22 的文档将被舍弃。
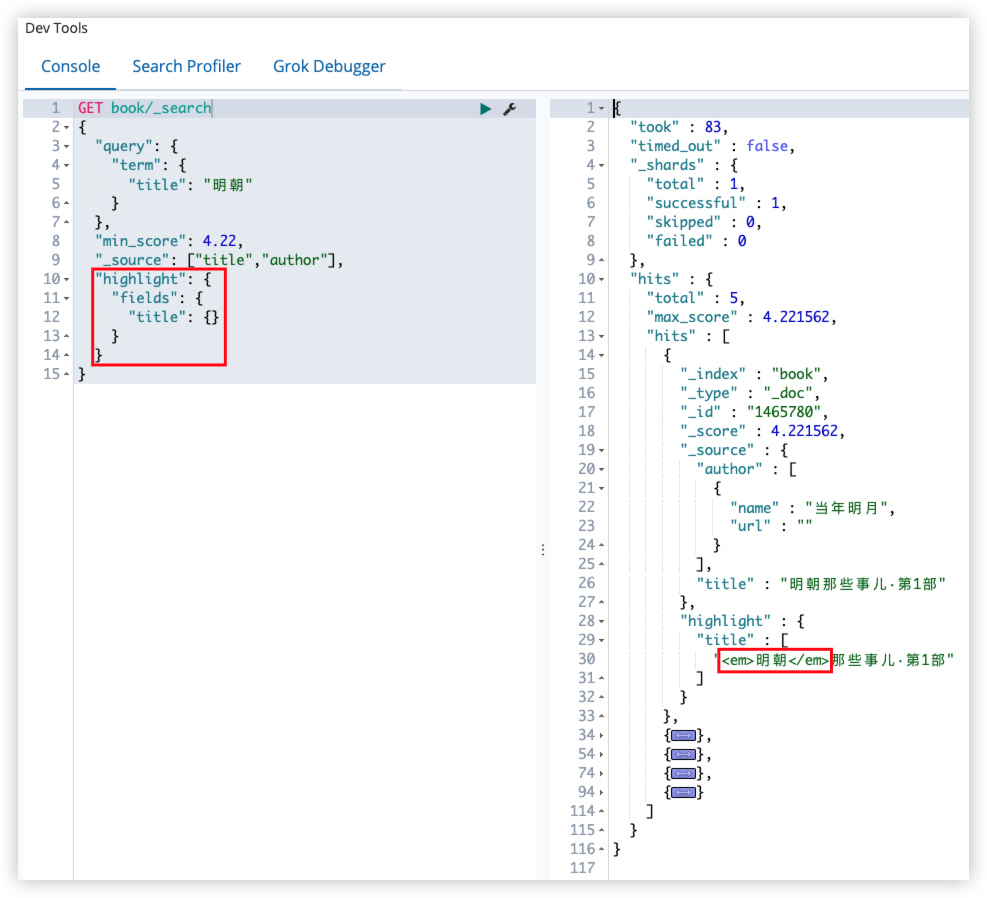
14.2.6 高亮
signpost_go_highlight
查询关键字高亮:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
GET book/_search
{
"query": {
"term": {
"title": "明朝"
}
},
"min_score": 4.22,
"_source": ["title","author"],
"highlight": {
"fields": {
"title": {}
}
}
}
15 ElasticSearch 全文搜索
15.1 match query
match query 会对查询语句进行分词,分词后,如果查询语句中的任何一个词项与之匹配,则文档就会被索引到。
1
2
3
4
5
6
7
8
GET book/_search
{
"query": {
"match": {
"title": "明朝那些"
}
}
}
1
2
3
4
5
GET book/_analyze
{
"text": "明朝那些",
"analyzer": "ik_max_word"
}
该查询首先会对明朝那些进行分词,分词之后,再去查询,只要文档的该字段中包含其中一个分词结果,就会返回该文档。换句话说,默认词项之间是 OR 的关系,如果想要修改,也可以改为 AND。
1
2
3
4
5
6
7
8
9
10
11
GET book/_search
{
"query": {
"match": {
"title": {
"query": "明朝那些",
"operator": "and"
}
}
}
}
此时就会要求文档中必须同时包含 明朝 和 那些 两个词。
15.2 match_phrase query
match_phrase query 也会对查询的关键字进行分词,但它分词后有两个特点:
- 分词后的词项顺序必须和文档中词项顺序一致
- 所有的词项都必须出现在文档中
示例如下:
1
2
3
4
5
6
7
8
9
10
11
GET book/_search
{
"query": {
"match_phrase": {
"title": {
"query": "明朝事儿",
"slop": 1
}
}
}
}
query 是查询的关键字,会被分词器进行分解,分解之后去倒排索引中进行匹配。
slop 是指关键字之间的最小距离,注意不是关键字之间间隔的字数。文档中的字段被分词器分解之后,分解出来的词项都包含一个 position 属性表示词项的位置,查询关键字分词之后,position 属性之间的间隔要小于 slop。
15.3 match_phrase_prefix query
类似于 match_phrase query,只不过这里多了一个通配符,match_phrase_prefix 支持词项的前缀匹配,但由于这种匹配方式效率较低,因此了解即可。
1
2
3
4
5
6
7
8
9
10
GET book/_search
{
"query": {
"match_phrase_prefix": {
"title": {
"query": "时"
}
}
}
}
这个查询过程,会自动进行词项匹配,会自动查找以时开始的词项,默认 50 个,可以自定义:
1
2
3
4
5
6
7
8
9
10
11
12
GET book/_search
{
"query": {
"match_phrase_prefix": {
"title": {
"query": "时",
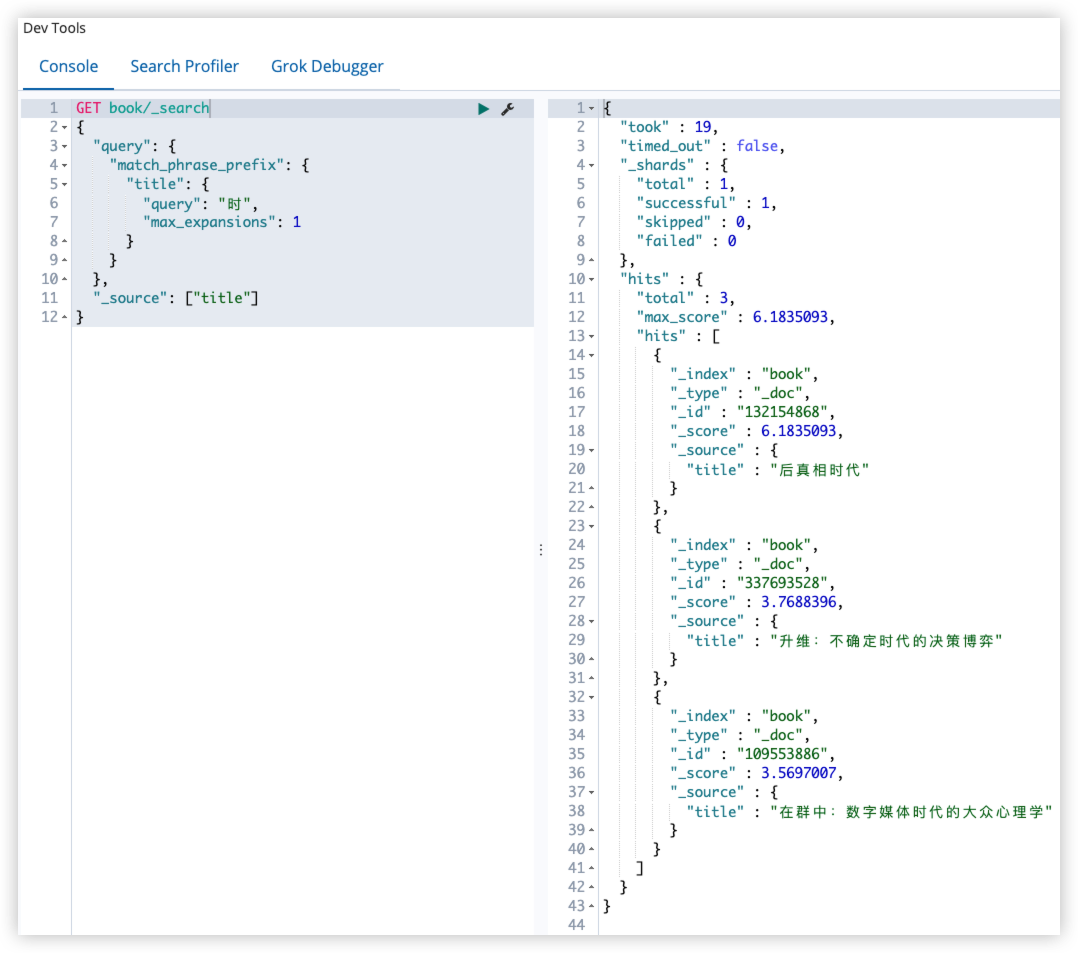
"max_expansions": 1
}
}
},
"_source": ["title"]
}
max_expansions 为 1 时,只会返回含时代词项的文档;
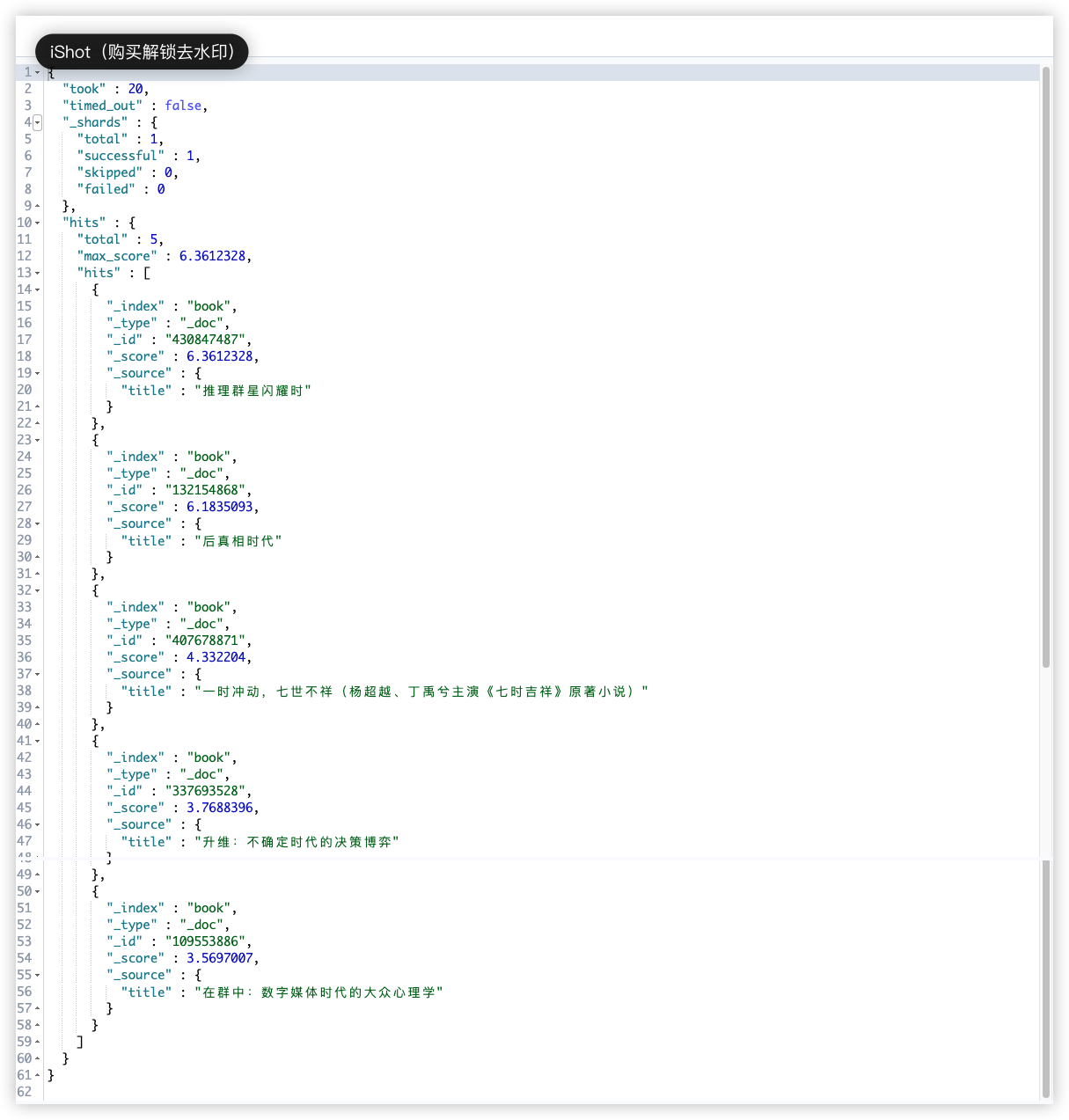
max_expansions 为 2 时,不仅会返回含时代词项的文档,还会返回时词项的文档;
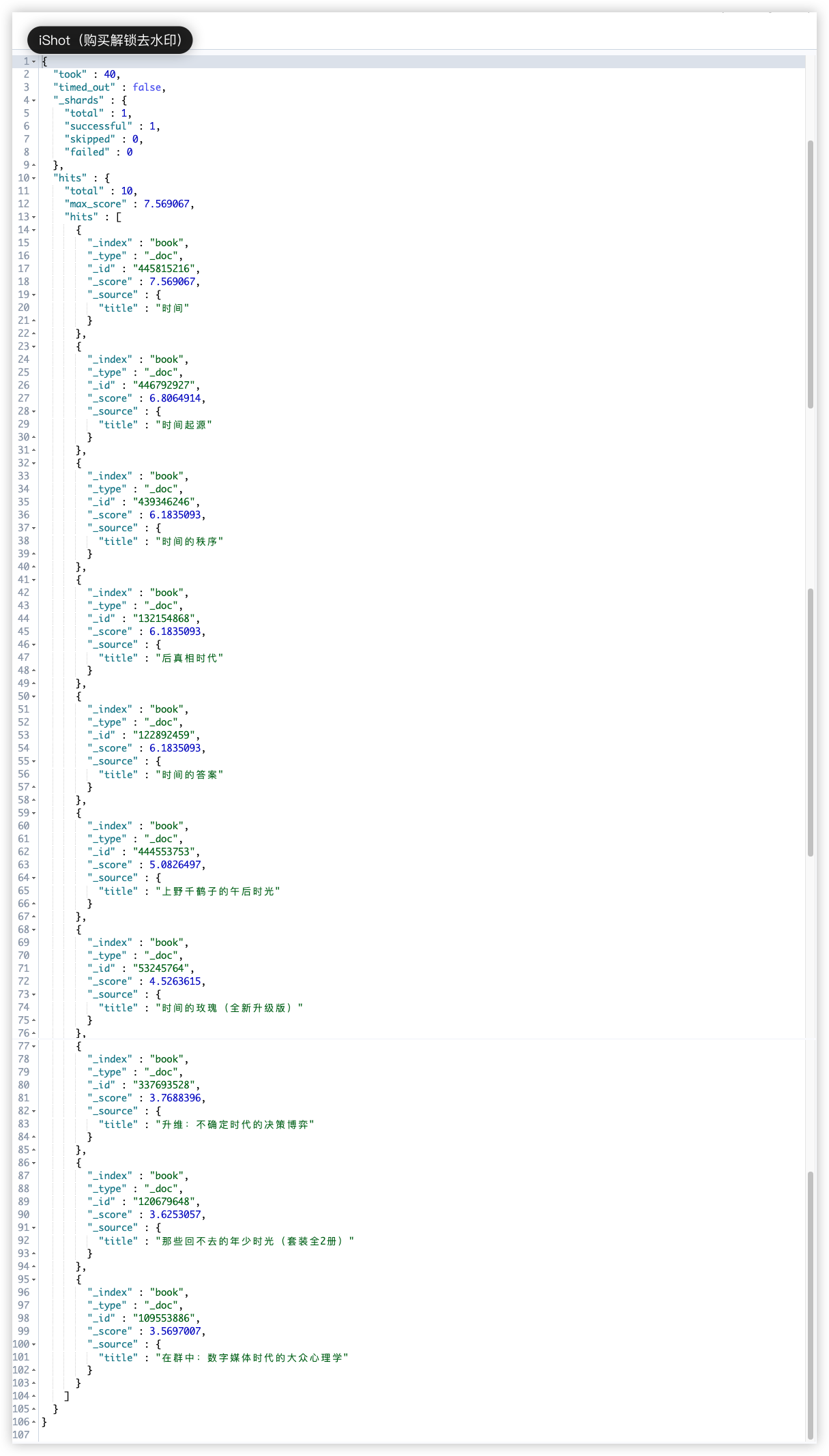
max_expansions 为 3 时,会返回含时代、时、时间词项的文档;
match_phrase_prefix 是针对分片级别的查询,假设 max_expansions 为 1,返回多个文档,但只含有一类词项,这是预期的结果。有的时候实际返回结果和预期结果并不一致,原因在于这个查询是分片级别的,不同的分片确实只返回了一类词项,但结果可能来自不同的分片,所以最终会看到多类词项。
15.4 multi_match query
match 查询的升级版,可以指定多个查询域:
1
2
3
4
5
6
7
8
9
GET book/_search
{
"query": {
"multi_match": {
"query": "明朝那些事儿",
"fields": ["title","abstract"]
}
}
}
这种查询方式还可以指定字段的权重:
1
2
3
4
5
6
7
8
9
GET book/_search
{
"query": {
"multi_match": {
"query": "明朝那些事儿",
"fields": ["title^2","abstract"]
}
}
}
这个表示关键字出现在 title 中的权重是出现在 info 中权重的 2 倍。
15.5 query_string query
query_string 是一种紧密结合 Lucene 的查询方式,在一个查询语句中可以用到 Lucene 的一些查询语法:
1
2
3
4
5
6
7
8
9
GET book/_search
{
"query": {
"query_string": {
"default_field": "title",
"query": "(明朝) AND (那些)"
}
}
}
15.6 simple_query_string
| 这个是 query_string 的升级,可以直接使用 +、 | 、- 代替 AND、OR、NOT 等。 |
1
2
3
4
5
6
7
8
9
GET book/_search
{
"query": {
"simple_query_string": {
"fields": ["title"],
"query": "(明朝) + (那些)"
}
}
}
查询结果和 query_string 一样。
16 ElasticSearch 词项查询
16.1 term query
词项查询不会去分析查询字符,直接拿查询字符去倒排索引中比对。
1
2
3
4
5
6
7
8
GET book/_search
{
"query": {
"term": {
"title": "明朝那些"
}
}
}
16.2 terms query
词项查询,但可以设置多个关键词。
1
2
3
4
5
6
7
8
GET book/_search
{
"query": {
"terms": {
"title": ["明朝","那些"]
}
}
}
16.3 range query
范围查询,可以按照日期范围、数字范围等查询。
范围查询中的参数主要有四个:
- gt 大于
- lt 小于
- gte 大于等于
- lte 小于等于
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
GET book/_search
{
"query": {
"range": {
"salesPrice": {
"gte": 100,
"lte": 500
}
}
},
"sort": [
{
"salesPrice": {
"order": "desc"
}
}
]
}
16.4 exists query
返回包含指定字段并该字段值不为空的文档。
1
2
3
4
5
6
7
8
GET book/_search
{
"query": {
"exists": {
"field": "title"
}
}
}
注意,空字符串也是有值的。null 是空值。
16.5 prefix query
前缀查询,效率略低,除非必要,一般不建议使用。
1
2
3
4
5
6
7
8
GET book/_search
{
"query": {
"prefix": {
"title": "明"
}
}
}
16.6 wildcard query
通配符查询,支持单字符和多字符通配符。
?表示一个任意字符。*表示零个或者多个字符。
查询书名中包含回不去的图书:(书名被分词器分析之后,其中有回不去词项的图书)
1
2
3
4
5
6
7
8
9
GET book/_search
{
"query": {
"wildcard": {
"title": "回不去"
}
},
"_source": ["title"]
}
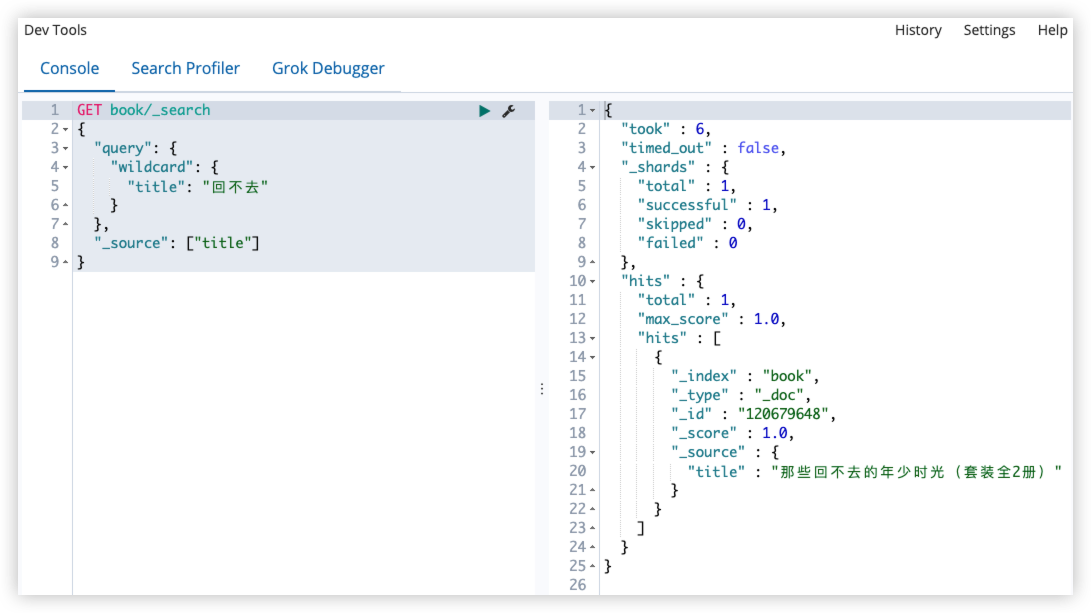
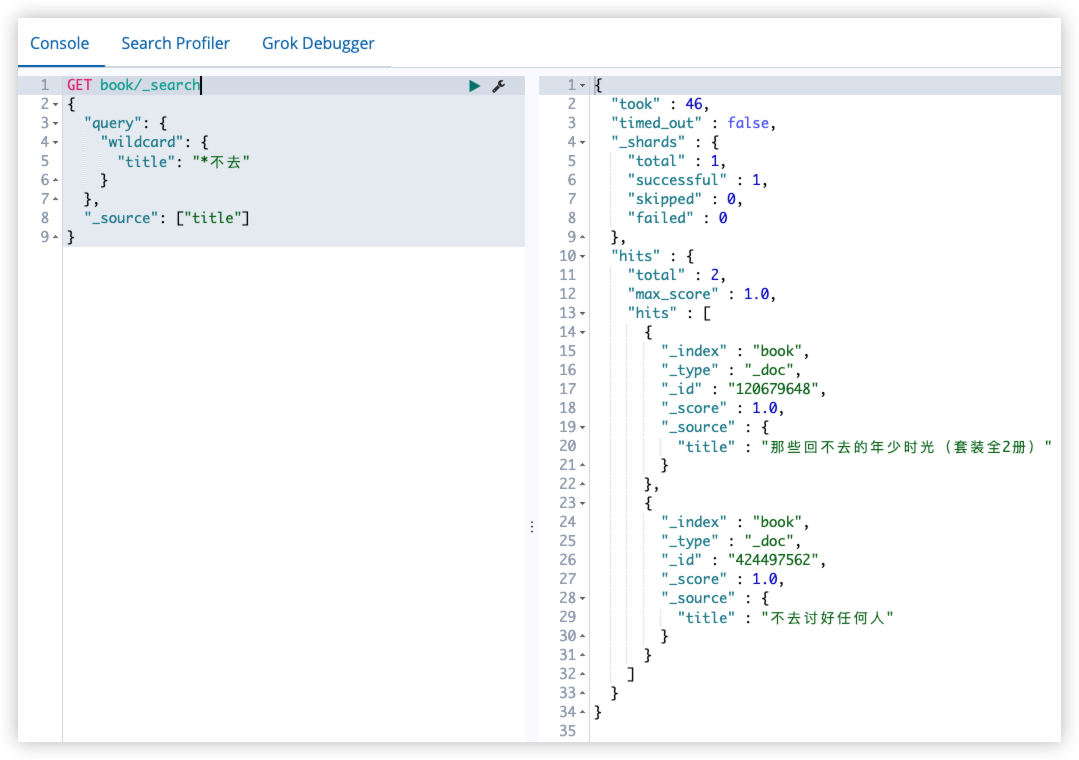
查询书名中包含*不去的图书:
1
2
3
4
5
6
7
8
9
GET book/_search
{
"query": {
"wildcard": {
"title": "*不去"
}
},
"_source": ["title"]
}
16.7 regexp query
正则表达式查询。
书名被分词器分析之后,其中有不去或者?不去词项的图书:
1
2
3
4
5
6
7
8
9
GET book/_search
{
"query": {
"regexp": {
"title": ".{0,1}不去"
}
},
"_source": ["title"]
}
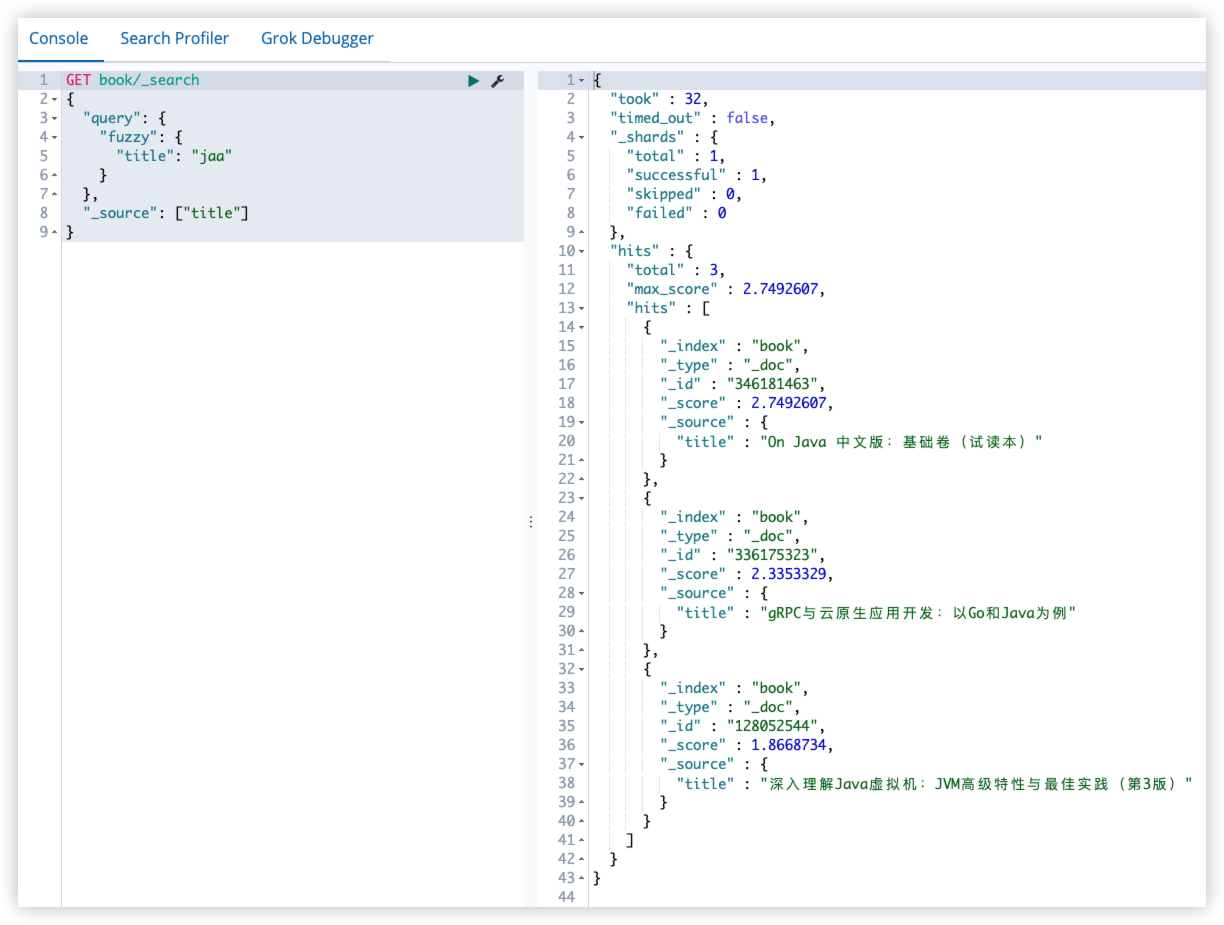
16.8 fuzzy query
在实际搜索中,可能会打错字,从而导致搜索不到,在 match query 中,可以通过 fuzziness 属性实现模糊查询。
模糊查询返回与搜索关键字相似的文档(以 LevenShtein 编辑距离为准)。
编辑距离是指将一个字符串变为另一个字符串所需要更改字符的次数,更改方式主要包括四种:
- 更改字符 (jaca –> java)
- 删除字符(javva –> java)
- 插入字符(jaa –> java)
- 转置字符 (jaav –> java)
为了找到相似的词,模糊查询会在指定的编辑距离内创建搜索关键词的所有可能变化或者扩展的集合,然后进行搜索匹配。
1
2
3
4
5
6
7
8
9
GET book/_search
{
"query": {
"fuzzy": {
"title": "jaa"
}
},
"_source": ["title"]
}
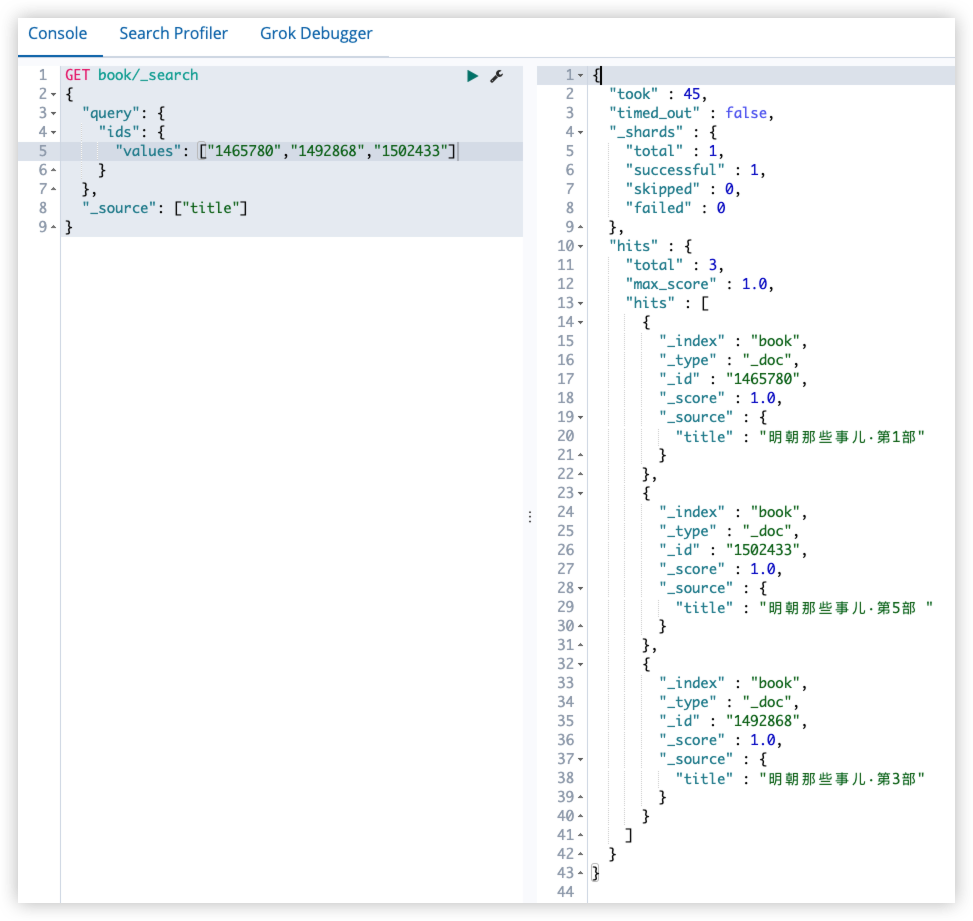
16.9 ids query
根据 ID 查询。
1
2
3
4
5
6
7
8
9
GET book/_search
{
"query": {
"ids": {
"values": ["1465780","1492868","1502433"]
}
},
"_source": ["title"]
}
17 Elastic Search 复合查询
17.1 constant_score query
如果不关心检索词项的频率(TF)对搜索结果排序的影响时,可以使用 constant_score 将查询语句或者过滤语句包裹起来。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
GET book/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"title": "明朝"
}
},
"boost": 1.2
}
},
"_source": ["title"]
}
17.2 bool query
bool query 可以将任意多个简单的查询组装在一起,有四个关键字可供选择,四个关键字所描述的条件可以有一个或者多个。
- must:文档必须匹配 must 选项下的查询条件。
- should:文档可以匹配 should 下的查询条件,也可以不匹配。
- must_not:文档必须不满足 must_not 选项下的查询条件。
- filter:类似于 must,但是 filter 不评分,只过滤数据。
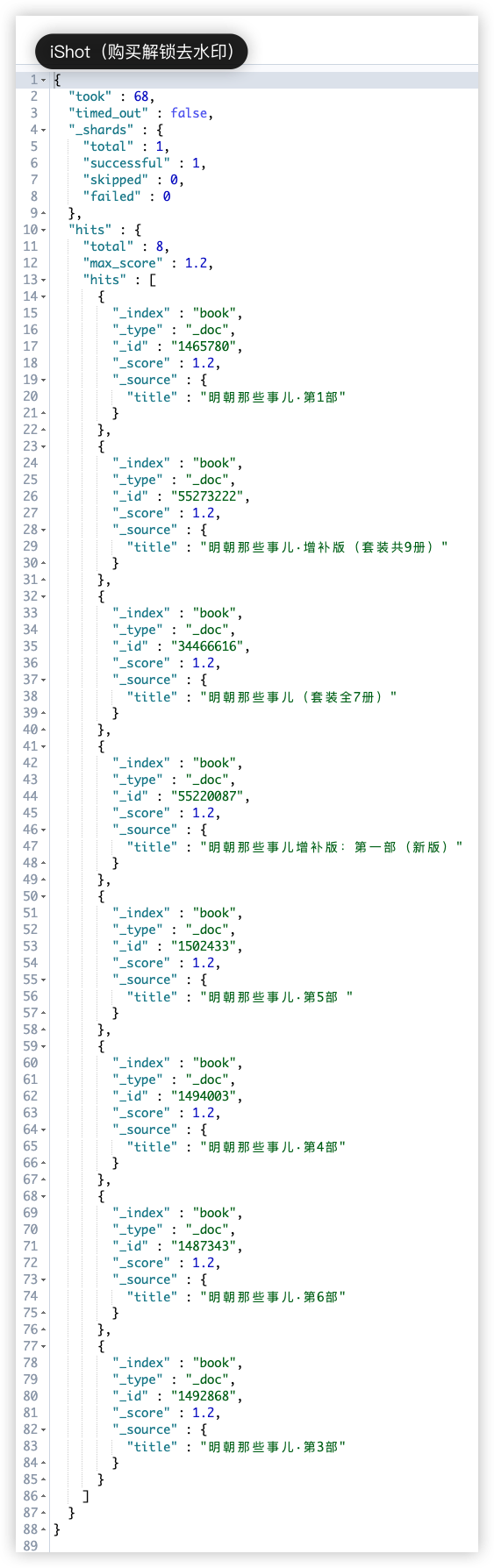
例如查询书名中必须包含明朝,同时价格不在 [0,20] 区间内,简介中可以包含 三百年 也可以不包含 三百年:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
GET book/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"title": {
"value": "明朝"
}
}
}
],
"must_not": [
{
"range": {
"salesPrice": {
"gte": 0,
"lte": 2000
}
}
}
],
"should": [
{
"match": {
"abstract": "三百年"
}
}
]
}
},
"_source": ["title","salesPrice","abstract"]
}
这里涉及到一个关键字,minmum_should_match 参数。
signpost_go_minmum_should_match
minmum_should_match 参数在 ES 官网上称作最小匹配度。在 multi_match query 或 bool query 的 should 中,都可以设置这个參数。
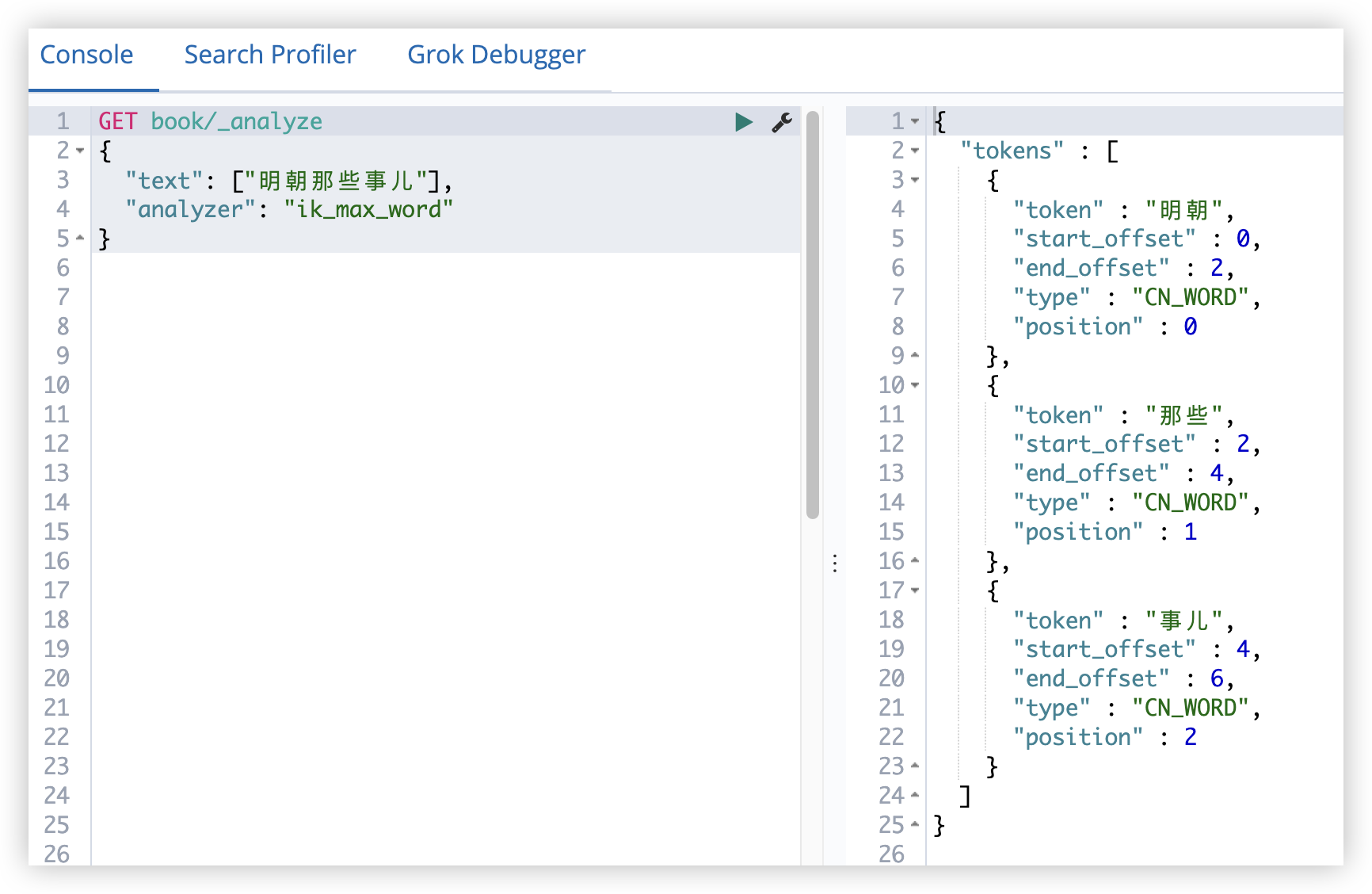
例如:查询书名中包含 明朝那些事儿 关键字的文档:
1
2
3
4
5
6
7
8
9
GET book/_search
{
"query": {
"match": {
"title": "明朝那些事儿"
}
},
"_source": ["title"]
}
在这个查询中,首先会对查询关键词进行分词:
分词后的 term 会构造成一个 should 的 bool query,每一个 term 都会变成一个 term query 的子句。换句话说,上面的查询和下面的 查询等价:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
GET book/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"title": {
"value": "明朝"
}
}
},
{
"term": {
"title": {
"value": "那些"
}
}
},
{
"term": {
"title": {
"value": "事儿"
}
}
}
]
}
},
"_source": ["title"]
}
在这两个查询语句中,都是文档只需要包含词项中的任意一项,文档就回被返回,在 match 查询中,可以通过 operator 參数设置文 档必须匹配所有词项。 如果想匹配一部分词项,就涉及到一个参数,就是 minmum_shou1d_match,即最小匹配度。即至少匹配多少个词。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
GET book/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"title": {
"value": "明朝"
}
}
},
{
"term": {
"title": {
"value": "那些"
}
}
},
{
"term": {
"title": {
"value": "事儿"
}
}
}
],
"minimum_should_match": "67%"
}
},
"_source": ["title"]
}
”67%“ 表示词项个数的67%,等同于 2。
如下两个查询等价:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
GET book/_search
{
"query": {
"match": {
"title": {
"query": "明朝那些事儿",
"minimum_should_match": 3
}
}
}
}
GET book/_search
{
"query": {
"match": {
"title": {
"query": "明朝那些事儿",
"operator": "and"
}
}
}
}
17.3 dis_max query
例如有两篇博客:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
PUT blog?include_type_name=false
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"content": {
"type": "text",
"analyzer": "ik_max_word"
}
}
},
"settings":
{
"number_of_shards": 1,
"number_of_replicas": 1
}
}
POST blog/_doc/1
{
"title": "如何通过 Java 代码调用 ElasticSearch",
"content": "极力推荐的解决方案"
}
POST blog/_doc/2
{
"title": "MongoDB",
"content": "MongoDB 是一个不错的 NoSQL 解决方案,如何通过 Java 代码调用 MongoDB"
}
搜索 Java解决方案 关键字,但不确定关键字是在 title 还是在 content,所以两者都搜索:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
GET blog/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": "Java解决方案"
}
},
{
"match": {
"content": "Java解决方案"
}
}
]
}
}
}
搜索结果如下:
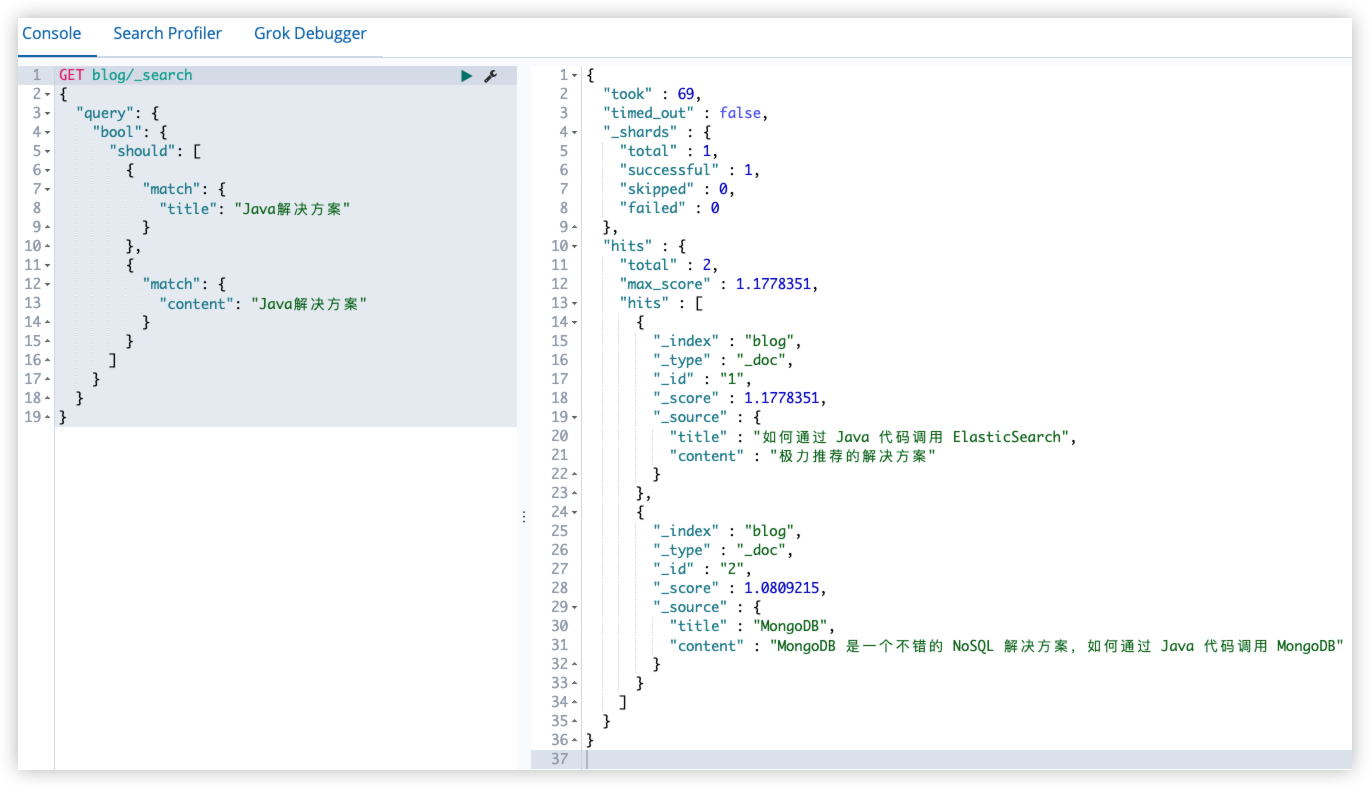
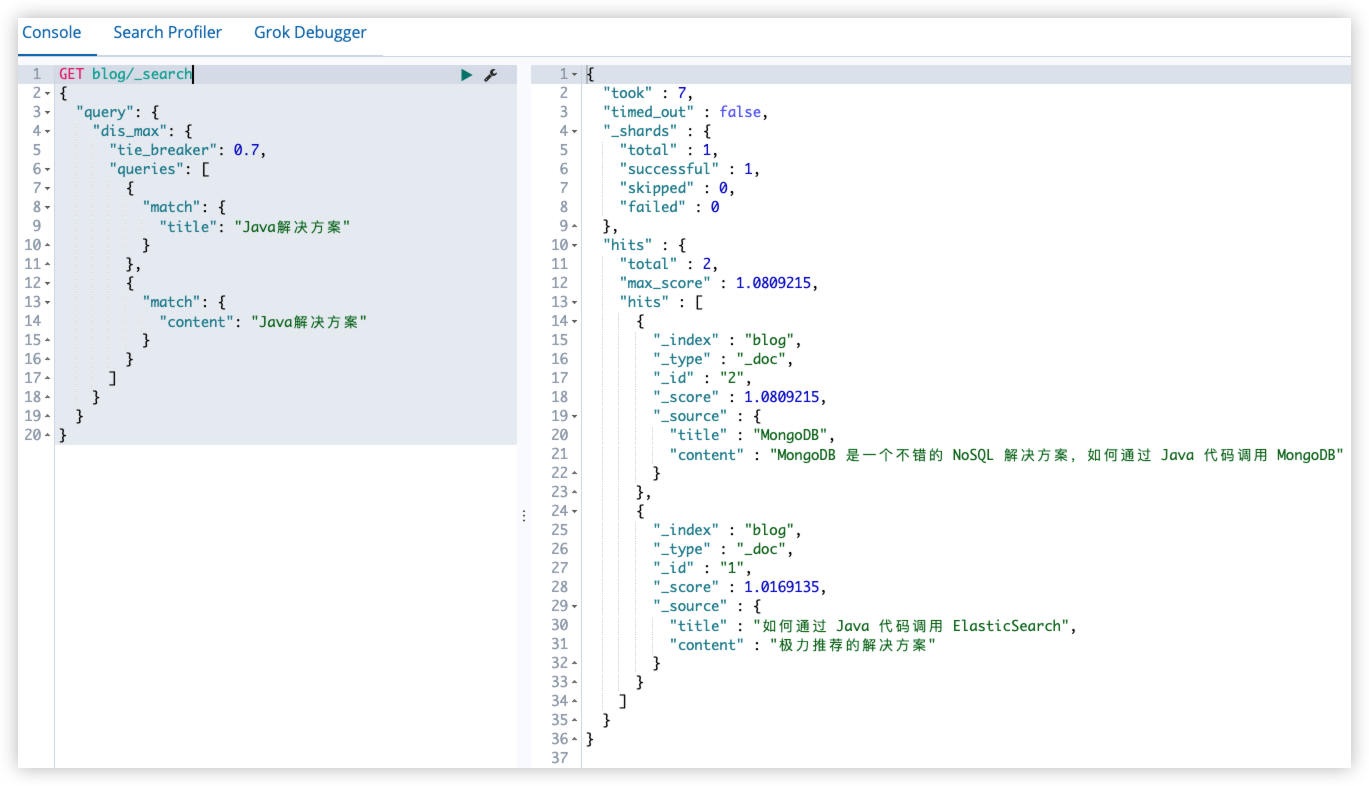
通过观察,感觉第二个和查询关键字相似度更高(Java 和 解决方案 都在 content 中),但实际查询结果井非这样。
原因:should query 中的评分策略
- 首先执行 should 中的两个查询
- 对两个查询结果的评分进行求和
- 对求和结果乘以匹配语句总数
- 再对结果除以所有语句总数
反映到具体的查询中:
前者
- title 中包含 Java,假设评分是 1.1
- content 中包含解决方案,假设评分是1.2
- 有得分的 query 数量是2
- 总的 query 数量是2
最终结果:(1.1+1.2)*2/2=2.3
后者
- title 中不包含查询关键字,没有得分
- content 中包含 解决方案 和 Java,假设评分是2
- 有得分的 query 数量是1
- 总的 query 数量是2
最终结果:2*1/2=1
在这种查询中,title 和 content 相当于是相互竞争的关系,所以需要找到一个最佳匹配字段。
为了解决这一问题,就需要用到 dis_max query (disjunction max query,分离最大化查询):匹配的文档依然返回,但是只将最佳匹配的评分作为查询的评分。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
GET blog/_search
{
"query": {
"dis_max": {
"queries": [
{
"match": {
"title": "Java解决方案"
}
},
{
"match": {
"content": "Java解决方案"
}
}
]
}
}
}

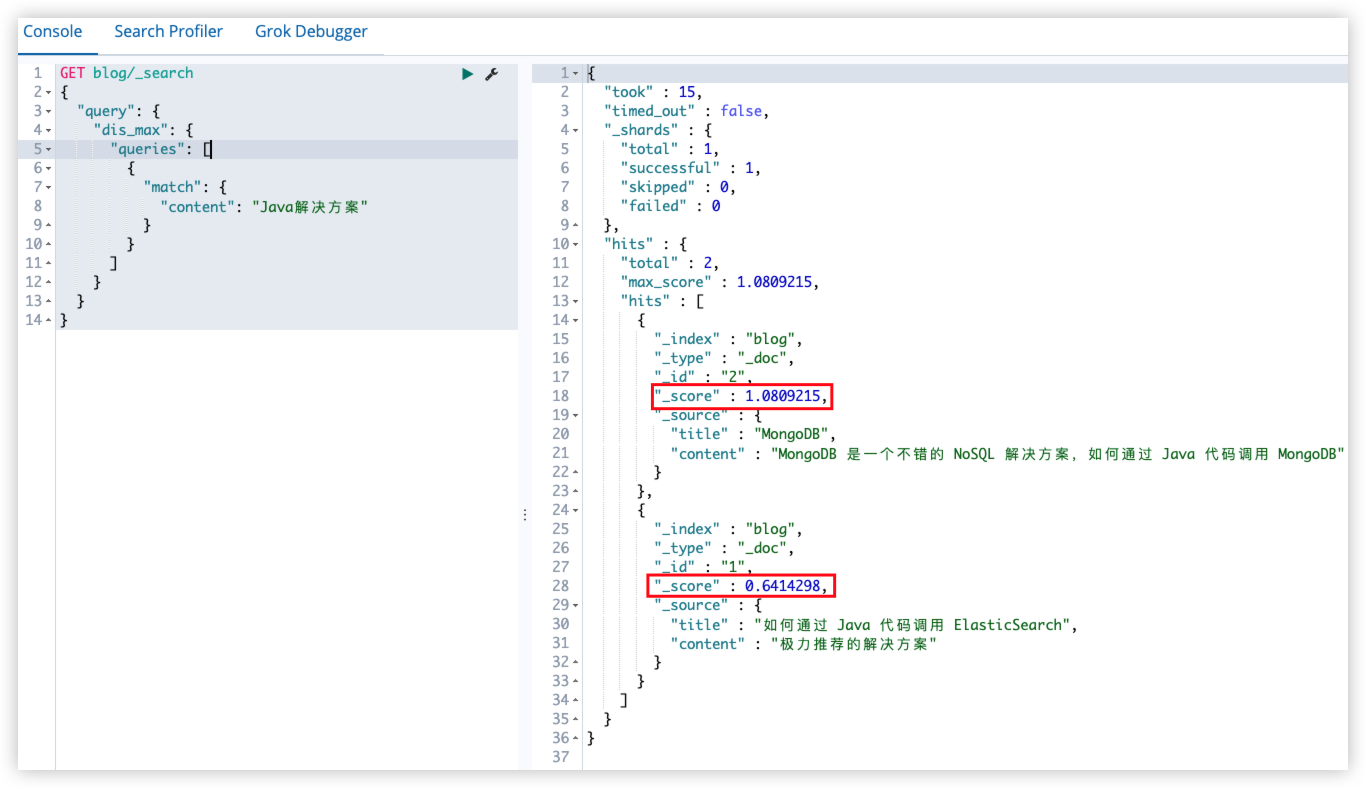
在 dis_max query 中,还有一个参数 tie_breaker(取值在[0,1]),在 dis_max query 中,是完全不考虑其他 query 的分数,只将最佳匹配字段的评分返回(如下面查询返回的评分和上面的相同)。但有的时候,不得不考虑一下其他 query 的分数,此时,可以通过tie_breaker 来优化 dis_max query,tie_breaker 会将其他 query 的分数,乘以 tie_breaker,然后和分数最高的 query 进行一个综合计算。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
GET blog/_search
{
"query": {
"dis_max": {
"tie_breaker": 0.7,
"queries": [
{
"match": {
"title": "Java解决方案"
}
},
{
"match": {
"content": "Java解决方案"
}
}
]
}
}
}
17.4 function_score query
场景:例如想要搜索一篇关于 Java 的博客,搜索的关键字是 Java,但是希望能够将投票数量较高的博客优先展示出来。默认的评分策略是没办法考虑到投票数量的,它只是考虑相关性,这时就可以通过 function_score query 来实现。
测试数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
PUT blog?include_type_name=false
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"vote": {
"type": "integer"
}
}
},
"settings":
{
"number_of_shards": 1,
"number_of_replicas": 1
}
}
POST blog/_doc/1
{
"title": "如何通过 Java 代码调用 ElasticSearch",
"vote": 100
}
POST blog/_doc/2
{
"title": "Java 线程池配置,Java Http 请求池配置",
"vote": 10
}
搜索标题中包含 Java 关键字的文档:
1
2
3
4
5
6
7
8
GET blog/_search
{
"query": {
"match": {
"title": "Java"
}
}
}
结果如下:
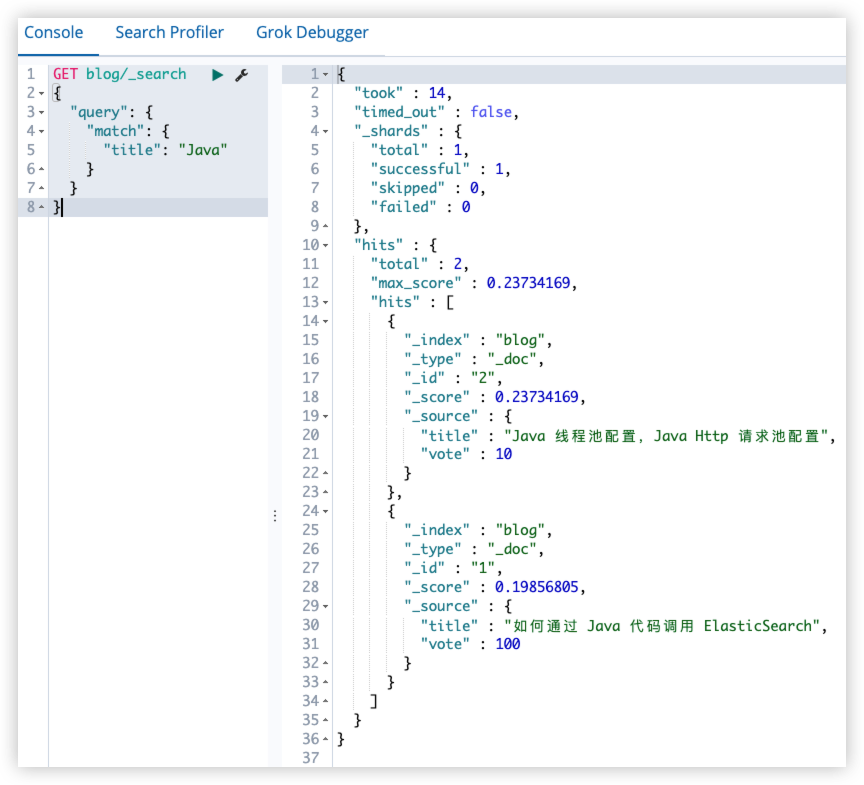
默认情况下,id 为 2 的记录得分较高,因为它的 title 中包含两个 Java。
如果在查询中,希望能够充分考虑 vote 字段,将 vote 较高的文档优先展示,就可以通过 function_score 来实现。
具体思路:在旧得分基础上,根据 vote 的数值进行综合运算,重新得出一个新的评分。
计算方式:
- weight
- random_score
- script_score
- field_value_factor
weight
weight 可以对评分设置权重;用法如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
GET blog/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "Java"
}
},
"functions": [
{
"weight": 10
}
]
}
}
}

可以看到,此时的评分,在之前的评分基础上乘以 10。
random score(了解即可,一般不用)
random_score 会根据 uid 字段进行 hash 运算,生成分数,使用 random_score 时可以配置一个种子,如果不配置,默认使用当前时间。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
GET blog/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "Java"
}
},
"functions": [
{
"random_score": {}
}
]
}
}
}

script score
自定义评分脚本。假设每个文档的最终得分是旧的分数加上 vote;查询方式如下;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
GET blog/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "Java"
}
},
"functions": [
{
"script_score": {
"script": {
"lang": "painless",
"source": "_score + doc['vote'].value"
}
}
}
]
}
}
}


最终得分是:(oldScore+vote)*oldScore。
如果不想乘以 oldScore,查询方式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
GET blog/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "Java"
}
},
"functions": [
{
"script_score": {
"script": {
"lang": "painless",
"source": "_score + doc['vote'].value"
}
}
}
],
"boost_mode": "replace"
}
}
}

通过 boost_mode 参数,可以设置最终的计算方式;该参数还有其他取值:
- muliply:分数相乘
- sum:分数相加
- avg:平均数
- max:最大分
- min:最小分
field_value factor
这个的功能类似于 script_score,但不用自己写脚本。
假设每个文档的最终得分是旧的分数乘以 vote;查询方式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
GET blog/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "Java"
}
},
"functions": [
{
"field_value_factor": {
"field": "vote"
}
}
]
}
}
}

默认的得分就是 oldScore*vote。
还可以利用 ES 内置的函数进行一些更复杂的运算:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
GET blog/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "Java"
}
},
"functions": [
{
"field_value_factor": {
"field": "vote",
"modifier": "sqrt"
}
}
],
"boost_mode": "replace"
}
}
}

此时,最终的得分:sqrt(vote)。
modifier 中可以设置内置函数,其他的内置函数还有:
| 内置函数 | 含义 |
|---|---|
| none | 默认的,不进行任何计算 |
| log | 字段值的对数 |
| log1p | 字段值加 1 然后取对数 |
| log2p | 字段值加 2 然后取对数 |
| In | 字段值的自然对数 |
| In1p | 字段值加 1 然后取自然对数 |
| In2p | 字段值加 2 然后取自然对数 |
| sqrt | 字段值的平方根 |
| square | 字段值的平方 |
| reciprocal | 倒数 |
参数 factor,影响因子。字段值先乘以影响因子,然后再进行计算。以 sqrt 为例,计算方式为 sqzt(factor*vote):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
GET blog/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "Java"
}
},
"functions": [
{
"field_value_factor": {
"field": "vote",
"modifier": "sqrt",
"factor": 10
}
}
],
"boost_mode": "replace"
}
}
}

参数 max_boost,控制计算结果的范围:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
GET blog/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "Java"
}
},
"functions": [
{
"field_value_factor": {
"field": "vote"
}
}
],
"boost_mode": "sum",
"max_boost": 20
}
}
}

max_boost 参效表示:在 functions 模块中,最终的计算结果上限。如果超过上限,就按照上线计算。
17.5 boosting query
boosting query 中包含三部分:
positive:得分不变
negative:降低得分
negative_boost:降低权重
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
GET blog/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"title": "明朝"
}
},
"negative": {
"match": {
"title": "增补"
}
},
"negative_boost": 0.5
}
},
"_source": ["title"]
}
18 ElasticSearch 嵌套查询
关系型数据库中有表的关联关系,在 ES 中,也有类似的需求,例如:订单表和商品表,在 ES 中,这样的一对多关系有两种方式:
- 嵌套文档(nested)
- 父子文档
18.1 嵌套文档和嵌套查询
例:电影和演员
建立索引
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
PUT movie?include_type_name=false
{
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word"
},
"actor": {
"type": "nested",
"properties": {
"name": {
"type": "keyword"
},
"gender": {
"type": "keyword"
}
}
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
添加数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
POST movie/_doc/1
{
"name": "莫斯科行动",
"actor": [
{
"name": "刘德华",
"gender": "男"
},
{
"name": "张涵予",
"gender": "男"
},
{
"name": "黄轩",
"gender": "男"
},
{
"name": "文咏珊",
"gender": "女"
}
]
}
查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
GET movie/_search
{
"query": {
"nested": {
"path": "actor",
"query": {
"bool": {
"must": [
{
"match": {
"actor.name": "文咏珊"
}
},
{
"match": {
"actor.gender": "女"
}
}
]
}
}
}
}
}
注意:actor 的类型必须是 nested,回顾上文 11.2.3。
查询索引信息:
1
GET _cat/indices?v
?v响应结果包括列标题。

文档数量是 5 条,这是因为 nested 类型文档在 ES 内部其实也是独立的 Lucene 文档,只是在查询的时候,ES 内部做了 join 处理,所以最终看起来就像一个独立文档一样。因此这种方案的性能并不是特别好。
18.2 父子文档
相比于嵌套文档,父子文档主要有如下优势:
- 更新父文档时,不会重新索引子文档
- 创建、修改或者删除子文档时,不会影响父文档或者其他子文档
- 子文档可以作为搜索结果独立返回
例:班级和学生
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
PUT class_student?include_type_name=false
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"c_s": {
"type": "join",
"relations": {
"class": "student"
}
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
c_s表示父子文档关系的名字,可以自定义。join 表示这是一个父子文档。relations 里边,class 这个位置是 parent,student 这个位置
是 child。
插入两个父文档
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
POST class_student/_doc/1
{
"name": "甲班",
"c_s": {
"name": "class"
}
}
POST class_student/_doc/2
{
"name": "乙班",
"c_s": {
"name": "class"
}
}
插入四个子文档:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
POST class_student/_doc/3?routing=1
{
"name": "张三",
"c_s": {
"name": "student",
"parent": 1
}
}
POST class_student/_doc/4?routing=1
{
"name": "李四",
"c_s": {
"name": "student",
"parent": 1
}
}
POST class_student/_doc/5?routing=2
{
"name": "王五",
"c_s": {
"name": "student",
"parent": 2
}
}
POST class_student/_doc/6?routing=2
{
"name": "赵六",
"c_s": {
"name": "student",
"parent": 2
}
}
首先可以看到,子文档都是独立的文档,name 属性表明这是一个子文档。
父子文档需要注意:
- 每个索引只能定义一个 join filed
- 子文档需要和父文档在同一个分片上,所以 routing 关键字的值为父文档的 id
- 可以向一个己经存在的 join fled 上新增关系
18.3 has_child query
通过子文档查询父文档,查询张三所属班级。
1
2
3
4
5
6
7
8
9
10
11
12
13
GET class_student/_search
{
"query": {
"has_child": {
"type": "student",
"query": {
"match": {
"name": "张三"
}
}
}
}
}
18.4 has_parent query
通过父文档查询子文档,查询甲班的学生。
1
2
3
4
5
6
7
8
9
10
11
12
13
GET class_student/_search
{
"query": {
"has_parent": {
"parent_type": "class",
"query": {
"match": {
"name": "甲班"
}
}
}
}
}
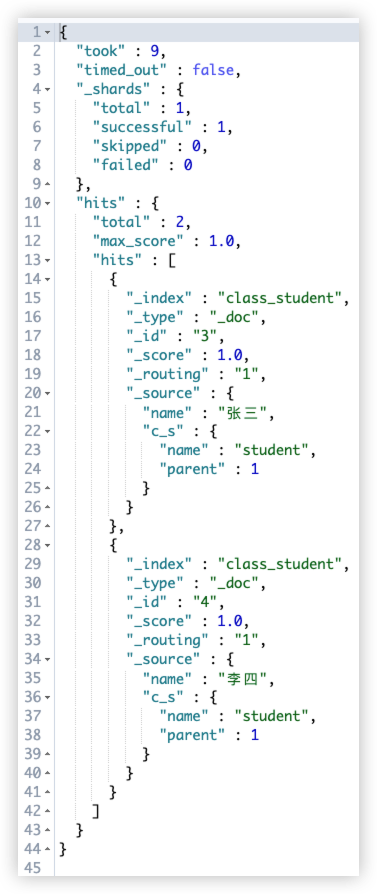
注意:这种查询没有评分。
使用 parent_id 查询子文档:
1
2
3
4
5
6
7
8
9
GET class_student/_search
{
"query": {
"parent_id": {
"type": "student",
"id": 1
}
}
}
通过 parent_id 查询,默认情況下使用相关性计算分数。
18.5 小结
整体上来说:
- 普通子对象实现一对多,会损失子文档的边界,子对象之间的属性关系丢失。
- nested 可以解决第1点的问题,但 nested 有两个缺点:更新父文档的时候要全部更新,不支持子文档属于多个父文档。
- 父子文档可以解决第1、2点的问题,但父子文档主要适用于写多读少的场景。
19 ElasticSearch 地理位置查询
19.1 数据准备
创建索引:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
PUT geo?include_type_name=false
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"location": {
"type": "geo_point"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
下载数据 geo.json,包含中国所有省会和直辖市的纬度坐标
执行导入命令:
1
curl -XPOST "http://localhost:9200/geo/_bulk?pretty" -H "content-type:application/json" --data-binary @geo.json
19.2 geo_distance query
给一个中心点,查询距离该中心点指定范围内的文档:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
GET geo/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"geo_distance": {
"distance": "200km",
"location": {
"lat": 37.870635,
"lon": 112.548879
}
}
}
]
}
}
}
查询以(37.870635,112.548879)为圆心,以 200KM 为半径,范围内的数据。
19.3 geo_bounding_box query
查询在某个矩形内的文档,通过两个点锁定一个矩形:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
GET geo/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"geo_bounding_box": {
"location": {
"top_right": {
"lat": 39.92010,
"lon": 116.40371
},
"bottom_left": {
"lat": 34.34727,
"lon": 108.94647
}
}
}
}
]
}
}
}

以北京作为矩形的右上角,以西安作为矩形的左下角,构造出来的矩形中,包含郑州、太原、石家庄三个省会城市。
19.4 geo_polygon query
查询在某个多边形内的文档:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
GET geo/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"geo_polygon": {
"location": {
"points": [
{
"lat": 40.84842,
"lon": 111.75551
},
{
"lat": 34.34727,
"lon": 108.94647
},
{
"lat": 38.04831,
"lon": 114.52153
}
]
}
}
}
]
}
}
}

以呼和浩特、西安、石家庄构成的多边形中,只有太原一座省会城市。
19.5 geo_shape query
两个图形之间的关系:相交、包含、不相交。
新建索引:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
PUT geo_shape?include_type_name=false
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"location": {
"type": "geo_shape"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
添加一条线:
1
2
3
4
5
6
7
8
9
10
11
POST geo_shape/_doc/1
{
"name": "太原-西安",
"location": {
"type": "linestring",
"coordinates": [
[112.548879,37.870635],
[108.94647,34.34727]
]
}
}
查询【线】银川-南京与【矩形】太原-西安的关系:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
GET geo_shape/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"geo_shape": {
"location": {
"shape": {
"type": "envelope",
"coordinates": [
[106.23850,38.49246],
[118.80242,32.06465]
]
},
"relation": "within"
}
}
}
]
}
}
}
relation 属性表示两个图形的关系:
- within 包含
- intersects 相交
- disjoint 不相交
20 ElasticSearch 特殊查询
20.1 more_like_this query
more_like_this query 可以实现基于内容的推荐,给定一篇文章,可以查询出和该文章相似的内容
1
2
3
4
5
6
7
8
9
10
11
12
13
GET book/_search
{
"query": {
"more_like_this": {
"fields": [
"abstract"
],
"like": "明朝那些事儿",
"min_term_freq": 1,
"max_query_terms": 12
}
}
}
- fields:要匹配的字段,可以有多个
- like: 要匹配的文本
- min_term_freq:词项的最低频率,默认是2。注意:这个是指词项在匹配文本中的频率,而不是文档中的频率
- max_query_terms:query 中包含的最大词项数
- min_doc_freq:最小文档频率,搜索的词,至少在多少个文档中出现,少于指定数目,该词会被忽略
- max_doc_freq:最大文档频率
- analyzer:分词器,默认使用字段的分词器
- stop_words:停用词列表
- minmum_should_match:匹配的最小词项数,回顾上文 17.2
20.2 script query
脚本查询,如:查询价格大于 20 的图书
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
GET book/_search
{
"query": {
"bool": {
"filter": {
"script": {
"script": {
"lang": "painless",
"source": "if (doc['salesPrice'].size() != 0) {doc['salesPrice'].value > 2000}"
}
}
}
}
},
"_source": ["title","salesPrice"]
}
20.3 percolate query
percolate query 译作滲透查询或者反向查询。
- 正常操作:根据查询语句找到对应的文档 query -> document
- percolate query:根据文档,返回与之匹配的查询语句,document -> query
应用场景:
- 价格监控
- 库存告警
- 股票警告
如:库存告警,假设指定字段的值大于阈值,报警
percolate mapping 定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
PUT stock?include_type_name=false
{
"mappings": {
"properties": {
"count": {
"type": "long"
},
"query": {
"type": "percolator"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
percolator 类型相当于 keyword、long 以及 integer 等,是不会被分析的。
插入文档:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
POST stock/_doc/1
{
"query": {
"bool": {
"must": {
"range": {
"count": {
"gt": 10
}
}
}
}
}
}
查询:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
GET stock/_search
{
"query": {
"percolate": {
"field": "query",
"documents": [
{
"count": 8
},
{
"count": 9
},
{
"count": 10
},
{
"count": 11
},
{
"count": 12
}
]
}
}
}
查询结果中会列出不满足条件的文档。
查询结果中的 _percolator_document_slot 字段表示文档的 position,从 0 开始计。
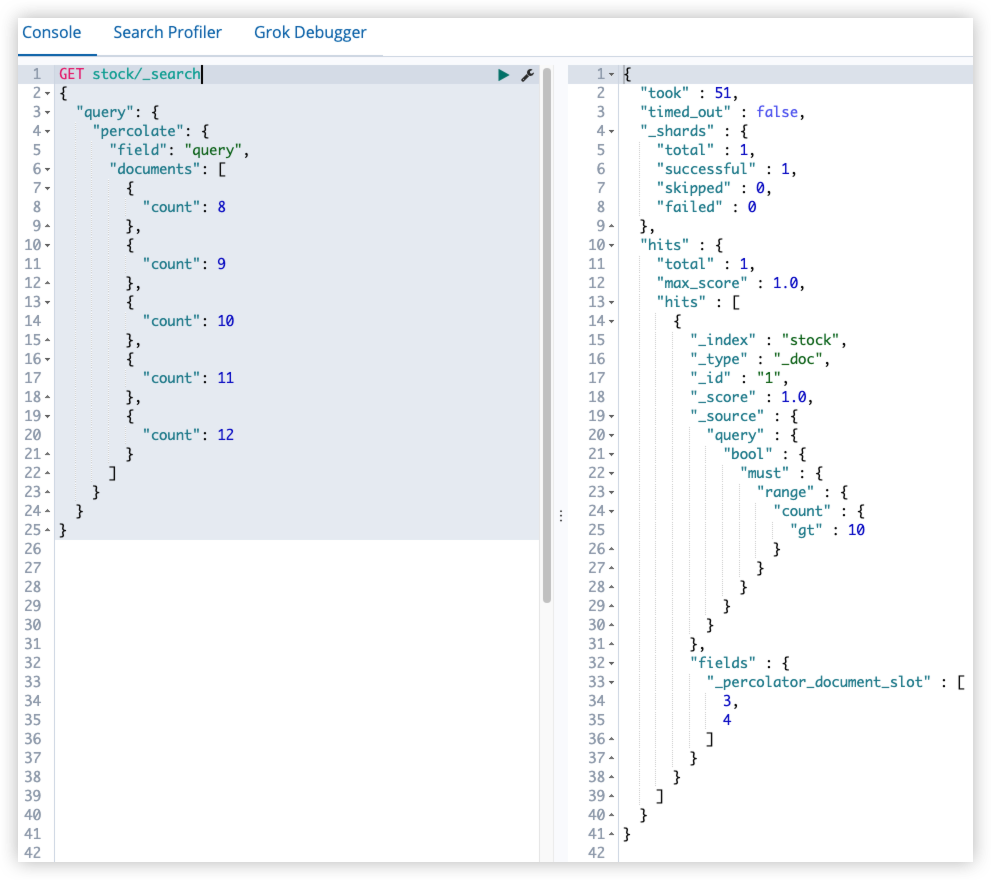
21 ElasticSearch 搜索高亮与排序
21.1 搜索高亮
普通高亮:回顾上文 14.2.6
自定义高亮标签:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
GET book/_search
{
"query": {
"term": {
"title": "明朝"
}
},
"min_score": 4.22,
"_source": ["title","author"],
"highlight": {
"fields": {
"title": {
"pre_tags": ["<strong>"],
"post_tags": ["</strong>"]
}
}
}
}
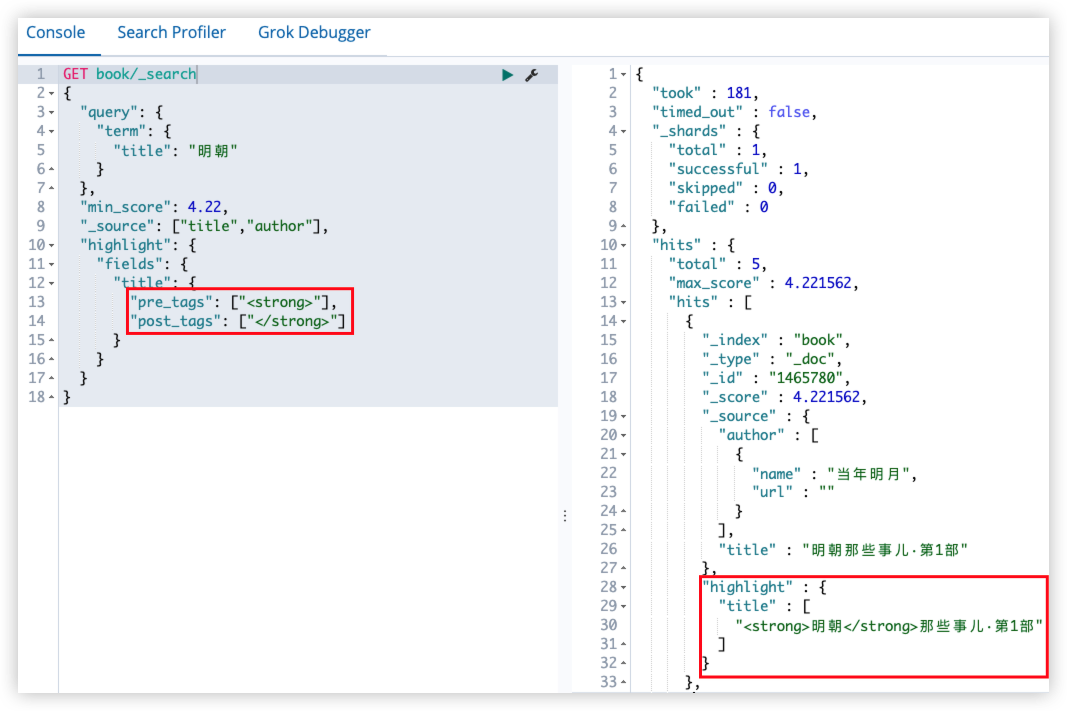
有的时候,虽然是在 title 字段中搜索,但希望在 info 字段中,相关的关键字也可以高亮:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
GET book/_search
{
"query": {
"term": {
"title": "明朝"
}
},
"min_score": 4.22,
"_source": ["title","author"],
"highlight": {
"require_field_match": "false",
"fields": {
"title": {
"pre_tags": ["<strong>"],
"post_tags": ["</strong>"]
},
"abstract": {
"pre_tags": ["<strong>"],
"post_tags": ["</strong>"]
}
}
}
}
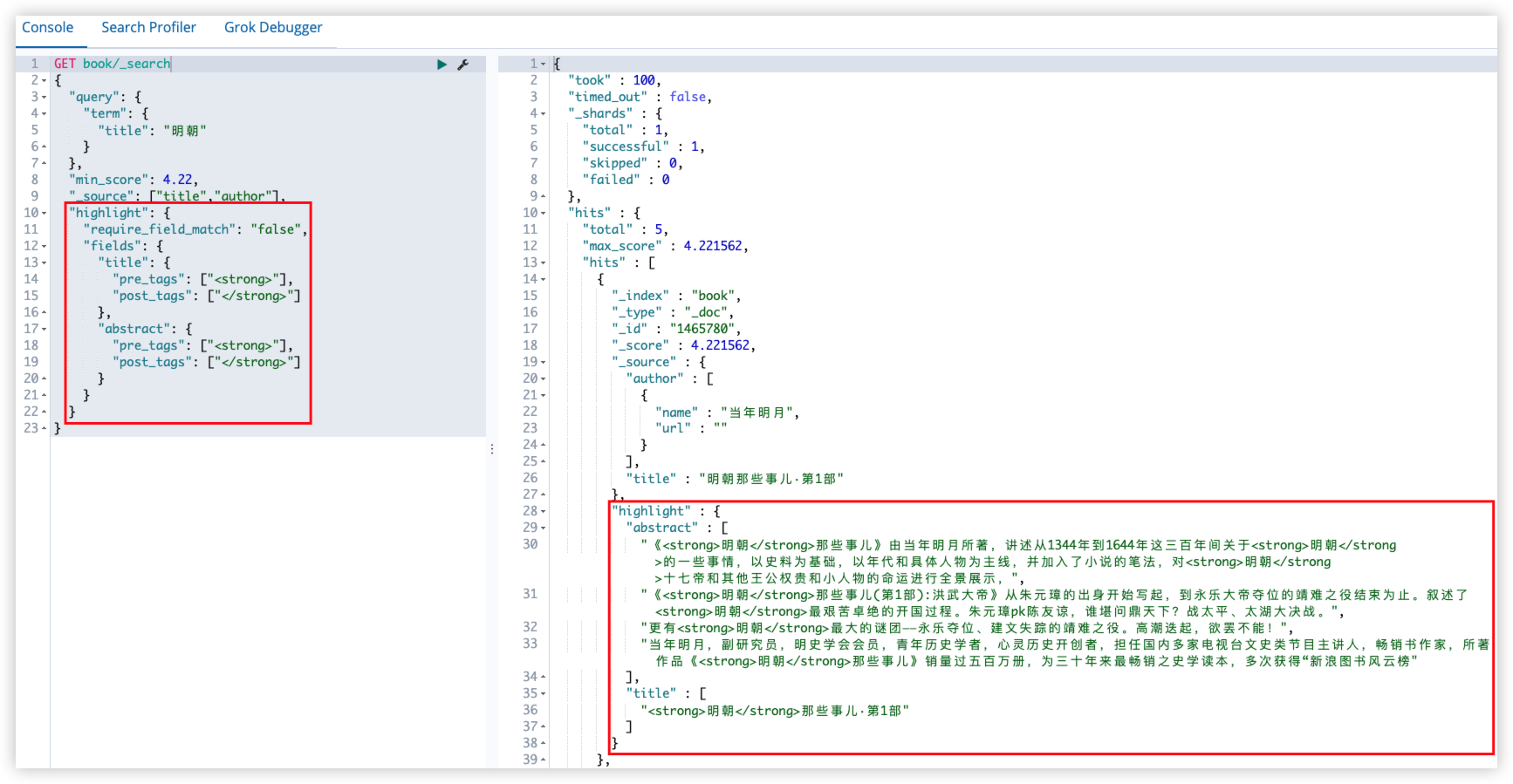
21.2 排序
排序,默认是按照查询文档的相关度来排序的,即 _score 字段:
1
2
3
4
5
6
7
8
GET book/_search
{
"query": {
"term": {
"title": "明朝"
}
}
}
等价于:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
GET book/_search
{
"query": {
"term": {
"title": "明朝"
}
},
"sort": [
{
"_score": {
"order": "desc"
}
}
]
}
match_all 查询只是返回所有的文档,不做评分,默认按照添加顺序返回,可以通过 _doc 字段对其进行排序:
1
2
3
4
5
6
7
8
9
10
11
12
13
GET book/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_doc": {
"order": "desc"
}
}
]
}
ES 同时也支持多字段排序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
GET book/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"salesPrice": {
"order": "asc"
}
},
{
"_doc": {
"order": "desc"
}
}
]
}
分片(打分是每个分片上单独进行的)、分词器(会使得倒排索引中词项发生改变)都会影响评分。
22 ElasticSearch 指标聚合
ES 中的聚合分析主要分为三个方面:
- 指标聚合
- 桶聚合(group by)
- 管道聚合
22.1 Max Aggregation
统计最大值。如:查询价格最大的书:
1
2
3
4
5
6
7
8
9
10
GET book/_search
{
"aggs": {
"max_price": {
"max": {
"field": "salesPrice"
}
}
}
}
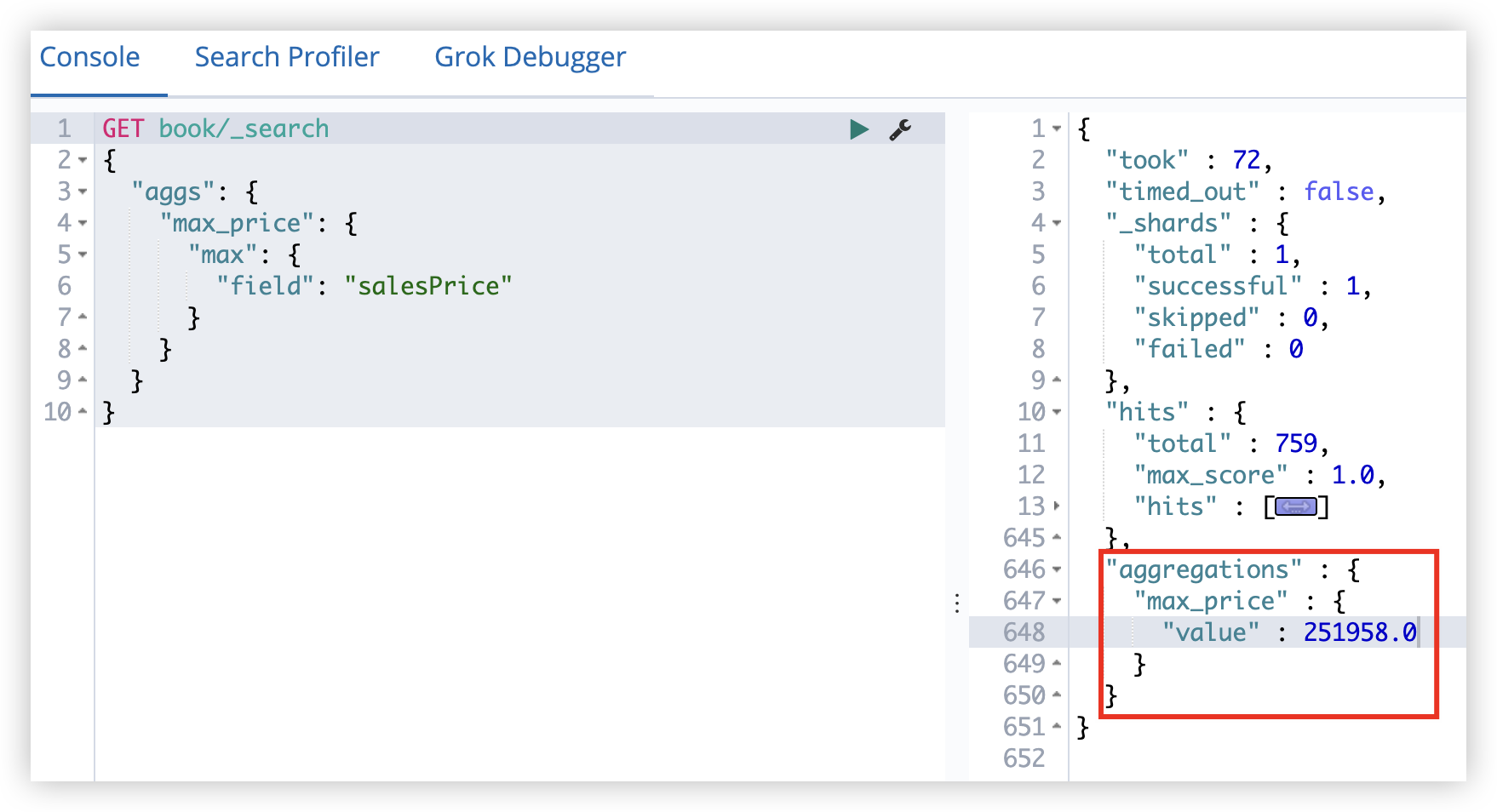
1
2
3
4
5
6
7
8
9
10
11
GET book/_search
{
"aggs": {
"max_price": {
"max": {
"field": "salesPrice",
"missing": 0
}
}
}
}
如果某个文档中缺少 salesPrice 字段,则设置该字段的值为 0。
通过脚本查询最大值:
1
2
3
4
5
6
7
8
9
10
11
12
GET book/_search
{
"aggs": {
"max_price": {
"max": {
"script": {
"source": "if(doc['salesPrice'].size()!=0){doc.salesPrice.value}else{0}"
}
}
}
}
}
使用脚本时,可以先通过doc['price'].size()!=0去判断文档是否有对应的属性。
22.2 Min Aggregation
统计最小值。用法和 Max Aggregation 一致:
1
2
3
4
5
6
7
8
9
10
11
GET book/_search
{
"aggs": {
"min_price": {
"min": {
"field": "salesPrice",
"missing": 0
}
}
}
}
脚本:
1
2
3
4
5
6
7
8
9
10
11
12
GET book/_search
{
"aggs": {
"min_price": {
"min": {
"script": {
"source": "if(doc['salesPrice'].size()!=0){doc.salesPrice.value}else{0}"
}
}
}
}
}
22.3 Avg Aggregation
统计平均值。用法和 Max Aggregation 一致:
1
2
3
4
5
6
7
8
9
10
11
GET book/_search
{
"aggs": {
"avg_price": {
"avg": {
"field": "salesPrice",
"missing": 0
}
}
}
}
脚本:
1
2
3
4
5
6
7
8
9
10
11
12
GET book/_search
{
"aggs": {
"avg_price": {
"avg": {
"script": {
"source": "if(doc['salesPrice'].size()!=0){doc.salesPrice.value}else{0}"
}
}
}
}
}
22.4 Sum Aggregation
求和。用法和 Max Aggregation 一致:
1
2
3
4
5
6
7
8
9
10
11
GET book/_search
{
"aggs": {
"sum_price": {
"sum": {
"field": "salesPrice",
"missing": 0
}
}
}
}
脚本:
1
2
3
4
5
6
7
8
9
10
11
12
GET book/_search
{
"aggs": {
"avg_price": {
"avg": {
"script": {
"source": "if(doc['salesPrice'].size()!=0){doc.salesPrice.value}else{0}"
}
}
}
}
}
22.5 Cardinality Aggregation
cardinality aggregation 用于基数统计。类似于 SQL 中的 distinct count(0):
text 类型是分析型类型,默认是不允许进行聚合操作的,如果想要对 text 类型进行聚合操作,需要设置 fielddata 属性为 true,这种方式 虽然可以使 text 类型进行聚合操作,但无法满足精准聚合,如果需要精准聚合,可以设置字段的子域(subfield)为 keyword。
- 设置 fielddata 属性为 true
重新定义 book 索引:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word",
"fielddata": true
},
"cover": {
"type": "keyword"
},
"url": {
"type": "keyword"
},
"isBundle": {
"type": "boolean"
},
"coverLabel": {
"type": "keyword"
},
"author": {
"type": "nested",
"properties": {
"name": {
"type": "keyword"
},
"url": {
"type": "keyword"
}
}
},
"origAuthor": {
"type": "nested",
"properties": {
"name": {
"type": "keyword"
},
"url": {
"type": "keyword"
}
}
},
"translator": {
"type": "nested",
"properties": {
"name": {
"type": "keyword"
},
"url": {
"type": "keyword"
}
}
},
"abstract": {
"type": "text",
"analyzer": "ik_max_word"
},
"authorHighlight": {
"type": "object"
},
"editorHighlight": {
"type": "object"
},
"isOrigin": {
"type": "boolean"
},
"kinds": {
"type": "nested",
"properties": {
"shortName": {
"type": "text",
"analyzer": "ik_max_word"
},
"id": {
"type": "integer"
}
}
},
"wordCount": {
"type": "integer"
},
"wordCountUnit": {
"type": "keyword"
},
"isColumn": {
"type": "boolean"
},
"highlightTags": {
"type": "nested"
},
"copyrightInfo": {
"type": "object",
"properties": {
"newlyAdapted": {
"type": "boolean"
},
"newlyPublished": {
"type": "boolean"
},
"adaptedName": {
"type": "keyword"
},
"publishedName": {
"type": "keyword"
}
}
},
"isInLibrary": {
"type": "boolean"
},
"fixedPrice": {
"type": "scaled_float",
"scaling_factor": 100
},
"salesPrice": {
"type": "scaled_float",
"scaling_factor": 100
},
"isRebate": {
"type": "boolean"
},
"id": {
"type": "keyword"
},
"isPurchased": {
"type": "boolean"
},
"isInWishlist": {
"type": "boolean"
},
"isEssay": {
"type": "boolean"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
执行导入命令:
1
curl -XPOST "http://localhost:9200/book/_bulk?pretty" -H "content-type:application/json" --data-binary @book.json
查询标题的总数量:
1
2
3
4
5
6
7
8
9
10
GET book/_search
{
"aggs": {
"title_count": {
"cardinality": {
"field": "title"
}
}
}
}
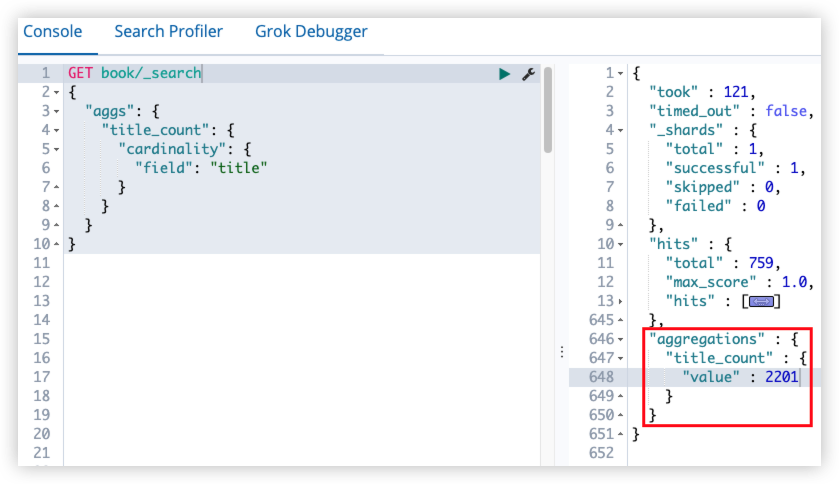
这种聚合方式是不准确的,它是按照分词之后的词项来聚合的。可以将 title 设置为 keyword 类型或者设置子域为 keyword。
- 将 title 设置为 keyword 类型
重新定义 book 索引:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"title": {
"type": "keyword"
},
"cover": {
"type": "keyword"
},
"url": {
"type": "keyword"
},
"isBundle": {
"type": "boolean"
},
"coverLabel": {
"type": "keyword"
},
"author": {
"type": "nested",
"properties": {
"name": {
"type": "keyword"
},
"url": {
"type": "keyword"
}
}
},
"origAuthor": {
"type": "nested",
"properties": {
"name": {
"type": "keyword"
},
"url": {
"type": "keyword"
}
}
},
"translator": {
"type": "nested",
"properties": {
"name": {
"type": "keyword"
},
"url": {
"type": "keyword"
}
}
},
"abstract": {
"type": "text",
"analyzer": "ik_max_word"
},
"authorHighlight": {
"type": "object"
},
"editorHighlight": {
"type": "object"
},
"isOrigin": {
"type": "boolean"
},
"kinds": {
"type": "nested",
"properties": {
"shortName": {
"type": "text",
"analyzer": "ik_max_word"
},
"id": {
"type": "integer"
}
}
},
"wordCount": {
"type": "integer"
},
"wordCountUnit": {
"type": "keyword"
},
"isColumn": {
"type": "boolean"
},
"highlightTags": {
"type": "nested"
},
"copyrightInfo": {
"type": "object",
"properties": {
"newlyAdapted": {
"type": "boolean"
},
"newlyPublished": {
"type": "boolean"
},
"adaptedName": {
"type": "keyword"
},
"publishedName": {
"type": "keyword"
}
}
},
"isInLibrary": {
"type": "boolean"
},
"fixedPrice": {
"type": "scaled_float",
"scaling_factor": 100
},
"salesPrice": {
"type": "scaled_float",
"scaling_factor": 100
},
"isRebate": {
"type": "boolean"
},
"id": {
"type": "keyword"
},
"isPurchased": {
"type": "boolean"
},
"isInWishlist": {
"type": "boolean"
},
"isEssay": {
"type": "boolean"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
执行导入命令:
1
curl -XPOST "http://localhost:9200/book/_bulk?pretty" -H "content-type:application/json" --data-binary @book.json
查询标题数量:
1
2
3
4
5
6
7
8
9
10
GET book/_search
{
"aggs": {
"title_count": {
"cardinality": {
"field": "title"
}
}
}
}
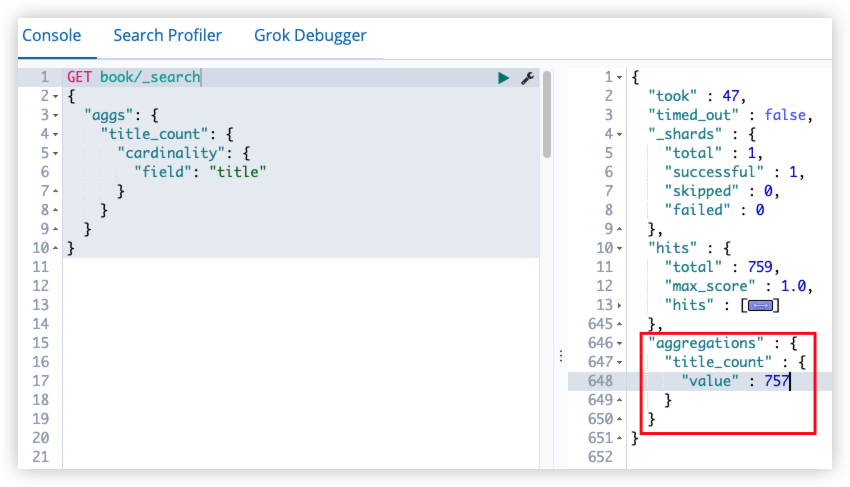
从结果可以看出共有 757 个不同的书名,图书总数 759 本;
- 设置子域为 keyword
重新定义 book 索引:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"cover": {
"type": "keyword"
},
"url": {
"type": "keyword"
},
"isBundle": {
"type": "boolean"
},
"coverLabel": {
"type": "keyword"
},
"author": {
"type": "nested",
"properties": {
"name": {
"type": "keyword"
},
"url": {
"type": "keyword"
}
}
},
"origAuthor": {
"type": "nested",
"properties": {
"name": {
"type": "keyword"
},
"url": {
"type": "keyword"
}
}
},
"translator": {
"type": "nested",
"properties": {
"name": {
"type": "keyword"
},
"url": {
"type": "keyword"
}
}
},
"abstract": {
"type": "text",
"analyzer": "ik_max_word"
},
"authorHighlight": {
"type": "object"
},
"editorHighlight": {
"type": "object"
},
"isOrigin": {
"type": "boolean"
},
"kinds": {
"type": "nested",
"properties": {
"shortName": {
"type": "text",
"analyzer": "ik_max_word"
},
"id": {
"type": "integer"
}
}
},
"wordCount": {
"type": "integer"
},
"wordCountUnit": {
"type": "keyword"
},
"isColumn": {
"type": "boolean"
},
"highlightTags": {
"type": "nested"
},
"copyrightInfo": {
"type": "object",
"properties": {
"newlyAdapted": {
"type": "boolean"
},
"newlyPublished": {
"type": "boolean"
},
"adaptedName": {
"type": "keyword"
},
"publishedName": {
"type": "keyword"
}
}
},
"isInLibrary": {
"type": "boolean"
},
"fixedPrice": {
"type": "scaled_float",
"scaling_factor": 100
},
"salesPrice": {
"type": "scaled_float",
"scaling_factor": 100
},
"isRebate": {
"type": "boolean"
},
"id": {
"type": "keyword"
},
"isPurchased": {
"type": "boolean"
},
"isInWishlist": {
"type": "boolean"
},
"isEssay": {
"type": "boolean"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
执行导入命令:
1
curl -XPOST "http://localhost:9200/book/_bulk?pretty" -H "content-type:application/json" --data-binary @book.json
查询标题数量:
1
2
3
4
5
6
7
8
9
10
GET book/_search
{
"aggs": {
"title_count": {
"cardinality": {
"field": "title.keyword"
}
}
}
}
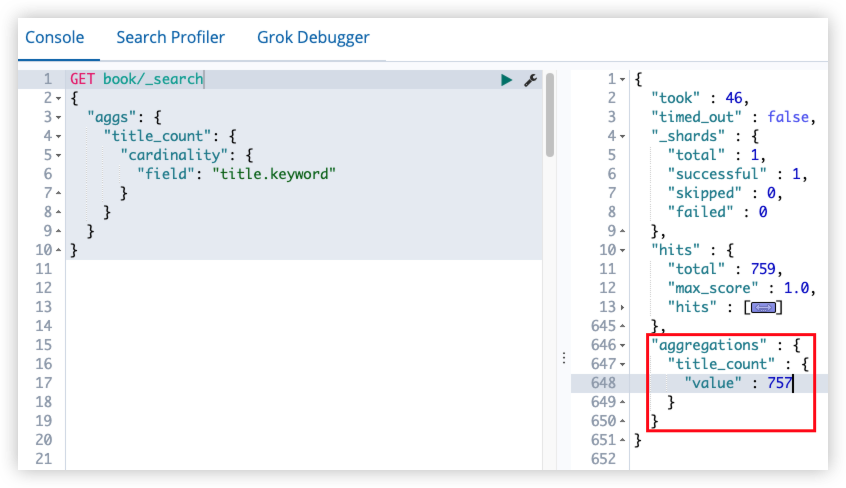
22.6 Stats Aggregation
基本统计。一次性返回 count、max、min、avg、sum:
1
2
3
4
5
6
7
8
9
10
GET book/_search
{
"aggs": {
"stats_query": {
"stats": {
"field": "salesPrice"
}
}
}
}
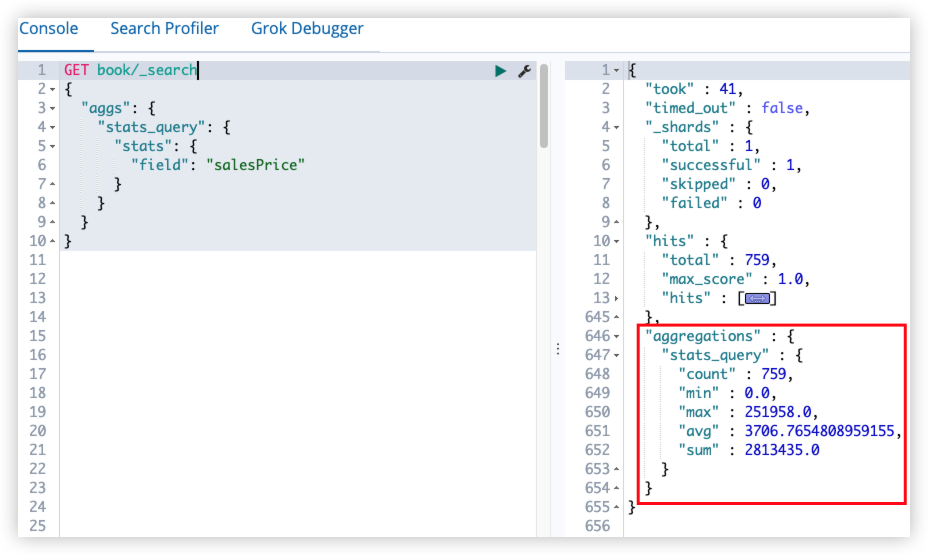
22.7 Extends Stats Aggregation
高级统计。比 stats 多一些属性:平方和、方差、标准差、平均值加减两个标准差的区间:
1
2
3
4
5
6
7
8
9
10
GET book/_search
{
"aggs": {
"extended_stats_query": {
"extended_stats": {
"field": "salesPrice"
}
}
}
}
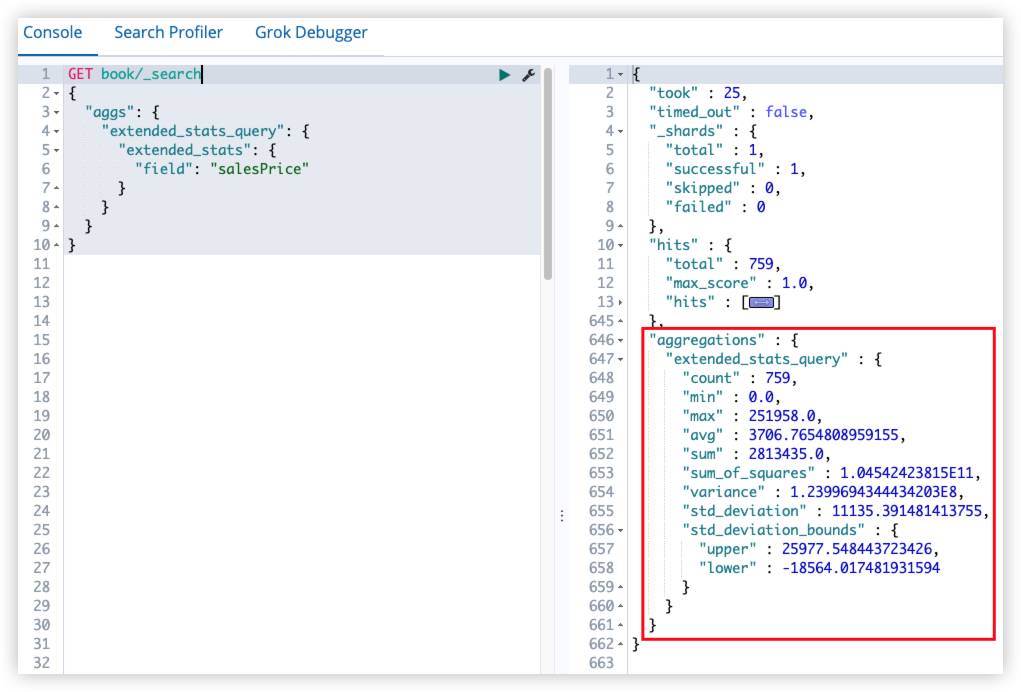
22.8 Percentiles Aggregation
百分位统计。
1
2
3
4
5
6
7
8
9
10
GET book/_search
{
"aggs": {
"percentiles_query": {
"percentiles": {
"field": "salesPrice"
}
}
}
}
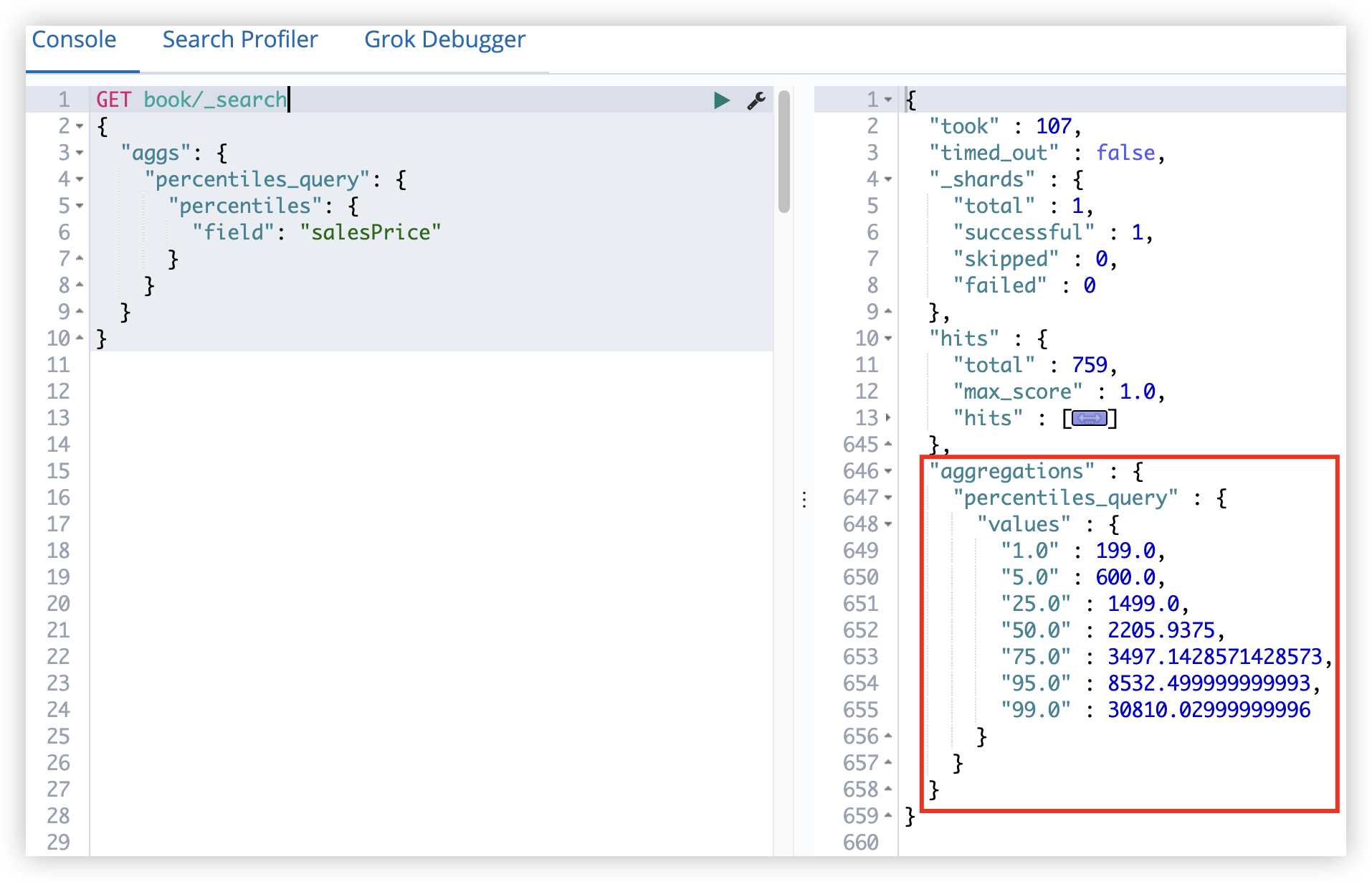
自定义百分比:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
GET book/_search
{
"aggs": {
"percentiles_query": {
"percentiles": {
"field": "salesPrice",
"percents": [
1,
5,
25,
50,
75,
95,
99
]
}
}
}
}
22.9 Value Count Aggregation
可以按照字段统计文档数量(包含指定字段的文档数量):
1
2
3
4
5
6
7
8
9
10
GET book/_search
{
"aggs": {
"value_count_query": {
"value_count": {
"field": "salesPrice"
}
}
}
}
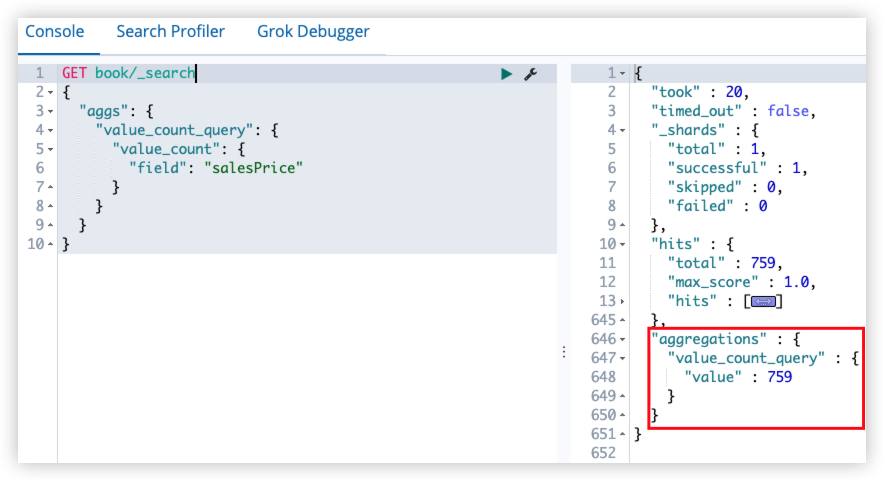
23 ElasticSearch 桶聚合(bucket)
重新定义 book 索引:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
PUT book?include_type_name=false
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"publisher": {
"type": "keyword"
},
"publishedDate": {
"type": "date"
},
"page": {
"type": "integer"
},
"price": {
"type": "scaled_float",
"scaling_factor": 100
},
"isbn": {
"type": "keyword"
},
"author": {
"type": "nested",
"properties": {
"name": {
"type": "keyword"
},
"nickname": {
"type": "keyword"
},
"gender": {
"type": "keyword"
},
"birth": {
"type": "date"
},
"birthplace": {
"type": "keyword"
},
"position": {
"type": "text",
"analyzer": "ik_max_word"
},
"avatar": {
"type": "keyword"
}
}
},
"cover": {
"type": "keyword"
},
"info": {
"type": "text",
"analyzer": "ik_max_word"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
插入数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
POST book/_doc/1
{
"name": "花之木兰·云天彼岸",
"publisher": "湖北少年儿童出版社",
"publishedDate": "2012-11",
"page": 250,
"price": 15.00,
"isbn": "9787535370761",
"author": [
{
"name": "辛晓娟",
"nickname": "步非烟",
"gender": "女",
"birth": "1981-07-11",
"birthplace": "四川成都",
"position": "中国人民大学国学院副教授",
"avatar": "https://img3.doubanio.com/view/personage/raw/public/ed958c3afddfcc2f56c97532ead77dda.jpg"
}
],
"cover": "https://img3.doubanio.com/view/subject/l/public/s24611917.jpg",
"bind": "平装",
"series": "花之木兰",
"info": "这是浪漫的魏晋时代,也是人、神、妖三方混战的时代。渴望做另一个自己的萝莉花木兰,为了守护村庄,选择了超越人类的战斗。在与妖魔对决的险恶之际,木兰不幸跌落山谷,更为不幸的是,却被一名热爱素质教育的怪叔叔顺便救了,在被挑起的好胜心和好奇心驱使下选择了怪叔叔布置的必修学科:圣人六艺,与选修学科:战斗决胜之道。而学成后的第一次试炼……却是被一个自以为是的小男生唐球一击秒杀!花木兰尝到了第一次失败:死。通过数理计算,花木兰破解了唐球的毒蛇秘技,并了解到幕后黑手是四处抢夺童男童女的燕国大司马慕容冲,一行人踏上了讨伐慕容冲的燕国之旅,木兰却又被燕国公主从心底深深爱上……"
}
POST book/_doc/2
{
"name": "玫瑰帝国·白蔷薇之祭",
"publisher": "吉林摄影出版社",
"publishedDate": "2014-12",
"page": 352,
"price": 26.80,
"isbn": "9787549821334",
"author": [
{
"name": "辛晓娟",
"nickname": "步非烟",
"gender": "女",
"birth": "1981-07-11",
"birthplace": "四川成都",
"position": "中国人民大学国学院副教授",
"avatar": "https://img3.doubanio.com/view/personage/raw/public/ed958c3afddfcc2f56c97532ead77dda.jpg"
}
],
"cover": "https://img1.doubanio.com/view/subject/s/public/s27927268.jpg",
"bind": "平装",
"series": "玫瑰帝国",
"info": "随着盛大的“公主”选秀热潮逐渐平息,另一件举世瞩目的盛事浮出水面——公爵换届选举即将举行!所有现任公爵以及候选公爵们,必须进行激烈的战争——D-war,以获得爵位。然而,这一年的D-war却有些不同寻常。作为两位大公的继承人,卓王孙与秋璇若想联姻,势必要有一人放弃继承权。然而,放弃所有退居幕后,却是谁都无法轻易说出口的。为此,两人约定,以今年的D-war为决胜战场,双方各支持一组选手参加比赛。谁的代理人赢取了公爵之位,谁便赢得了这场婚姻之战的胜利。卓王孙的“代理团队”实力强到可怕,本以为胜券在握,没想到,秋璇为他找来的对手,居然是自己的“情敌”石星御!卓王孙暗自咬牙:这下子,就算拼了命也是不能输了……"
}
POST book/_doc/3
{
"name": "人间六道之修罗道",
"publisher": "二十一世纪出版社",
"publishedDate": "2006-11",
"page": 223,
"price": 20.00,
"isbn": "9787539134949",
"author": [
{
"name": "辛晓娟",
"nickname": "步非烟",
"gender": "女",
"birth": "1981-07-11",
"birthplace": "四川成都",
"position": "中国人民大学国学院副教授",
"avatar": "https://img3.doubanio.com/view/personage/raw/public/ed958c3afddfcc2f56c97532ead77dda.jpg"
}
],
"cover": "https://img1.doubanio.com/view/subject/s/public/s2975150.jpg",
"bind": "平装",
"series": "人间六道",
"info": "在一个以杀戮为名的小镇上,以唐传奇中的人物南柯太守、裴航、王仙客、任氏、谢小娥、昆仑奴、荥阳公子、红娘、柳毅、红线、聂隐娘命名的十二刺客即主人费十年之功喂养的十“传奇”。在他们身体上不同的部位,刺着一枚扇形刺青,只有传奇本人的热血才能让刺青显形。十二枚刺青,描摹着十二种各各不同的惨烈死状。传奇的主人似乎以修改传奇的结局为乐,十二传奇屠戮对手的每一处现场,似乎都留有主人的踪迹。这个血的游戏中谁是棋子,谁又是下棋的人?谁是牵线木偶,谁又是挥动线索的那只手?最终只有一人能够生还,取得十一枚刺青的那位传奇将获得自由。十二枚刺青拼合,露出一个惊人的谜底!这时候,一个名叫步非烟的传奇悄悄浮出水面。谁是最后的幸存者?谁是幕后主谋?不到最后,谁也参不透结局……"
}
POST book/_doc/4
{
"name": "华音流韶之曼荼罗",
"publisher": "中国戏剧出版社",
"publishedDate": "2005-11",
"page": 274,
"price": 20.00,
"isbn": "9787104023197",
"author": [
{
"name": "辛晓娟",
"nickname": "步非烟",
"gender": "女",
"birth": "1981-07-11",
"birthplace": "四川成都",
"position": "中国人民大学国学院副教授",
"avatar": "https://img3.doubanio.com/view/personage/raw/public/ed958c3afddfcc2f56c97532ead77dda.jpg"
}
],
"cover": "https://img1.doubanio.com/view/subject/s/public/s1469210.jpg",
"bind": "平装",
"series": "华音流韶",
"info": "佛家云:生、老、病、死、怨憎会、爱别离、求不得、五蕴盛为人生八苦。凡尘之人,莫能超脱。一入曼荼罗阵,亲历八苦、身心受损,最终成为阵法的一部分…… 卓王孙,杨逸之,小晏,相思一行人在火狐的引诱下,一步步踏入这片上古林莽,就见那奇山秀水间,命运之轮已然开始转动,无綮国、喜舍国、魖魍国、蜉蝣国……众人宛如进入《魔戒》般的幻境之旅,被曼荼罗阵的巨口静静吞噬……"
}
POST book/_doc/5
{
"name": "玫瑰帝国·辉夜姬之瞳",
"publisher": "长江文艺出版社",
"publishedDate": "2016-08-15",
"price": 36.00,
"isbn": "9787104023197",
"author": [
{
"name": "辛晓娟",
"nickname": "步非烟",
"gender": "女",
"birth": "1981-07-11",
"birthplace": "四川成都",
"position": "中国人民大学国学院副教授",
"avatar": "https://img3.doubanio.com/view/personage/raw/public/ed958c3afddfcc2f56c97532ead77dda.jpg"
}
],
"cover": "https://img9.doubanio.com/view/subject/s/public/s28960864.jpg",
"bind": "平装",
"series": "玫瑰帝国",
"info": ""
}
POST book/_doc/6
{
"name": "玫瑰帝国·伊甸园之暮",
"publisher": "长江文艺出版社",
"publishedDate": "2016-08-15",
"page": 360,
"price": 36.00,
"isbn": "9787535489135",
"author": [
{
"name": "辛晓娟",
"nickname": "步非烟",
"gender": "女",
"birth": "1981-07-11",
"birthplace": "四川成都",
"position": "中国人民大学国学院副教授",
"avatar": "https://img3.doubanio.com/view/personage/raw/public/ed958c3afddfcc2f56c97532ead77dda.jpg"
}
],
"cover": "https://img9.doubanio.com/view/subject/s/public/s28960864.jpg",
"bind": "平装",
"series": "玫瑰帝国",
"info": ""
}
POST book/_doc/7
{
"name": "华音流韶之海之妖",
"publisher": "新世界出版社",
"publishedDate": "2005-09",
"page": 248,
"price": 20.00,
"isbn": "9787801877215",
"author": [
{
"name": "辛晓娟",
"nickname": "步非烟",
"gender": "女",
"birth": "1981-07-11",
"birthplace": "四川成都",
"position": "中国人民大学国学院副教授",
"avatar": "https://img3.doubanio.com/view/personage/raw/public/ed958c3afddfcc2f56c97532ead77dda.jpg"
}
],
"cover": "https://img9.doubanio.com/view/subject/s/public/s1433206.jpg",
"bind": "平装",
"series": "华音流韶",
"info": "神岛敛雾,却如深闺美人,隔帘照影。八十年来,造访者不过十一人,风物清峻如彼,又怎么会不含怨带嗔?但名列华音阁十八禁地之最,江湖上最神秘的十六洞天之一的青鸟岛,又有谁敢莽撞闯来?也不没有人闯,只不过莫支湖中红了又清,青鸟岛上却从没有不速之客的脚印。所以,直到如今,就是华音阁中的弟子也很少知道岛上究竟有什么。然而,这岛上的秘密似乎一眼就可以看透――奇花异卉虽多,但岛上却无可碍目者,放眼望去,几无余物。更显得岛心那间藏青石垒成得凉亭醒目之极。"
}
POST book/_doc/8
{
"name": "华音流韶之天剑伦",
"publisher": "新世界出版社",
"publishedDate": "2006-01",
"page": 255,
"price": 22.00,
"isbn": "9787801879547",
"author": [
{
"name": "辛晓娟",
"nickname": "步非烟",
"gender": "女",
"birth": "1981-07-11",
"birthplace": "四川成都",
"position": "中国人民大学国学院副教授",
"avatar": "https://img9.doubanio.com/view/subject/s/public/s1537994.jpg"
}
],
"cover": "https://img9.doubanio.com/view/subject/s/public/s28960864.jpg",
"bind": "平装",
"series": "华音流韶",
"info": "雪峰孤立,圣湖如画。卓王孙孤身闯入乐胜伦宫,而对传说中的魔王波旬。孔雀之阵错综迷离,八瓣之花更显妖异,灭世的神力只待最后觉醒。这一切,仅终结于那个清如莲花的女子,在天魔之舞里的一个抉择。这个抉择,于她千万年前在雪峰上苦苦修行时就已注定。其间所有的惊心动魄、寂寞繁华、生死一线,都不过是为了验证一个沉积已久的轮回。当相思跃马张弓,一箭射开第五圣泉时,岗仁波吉峰顶,杨逸之的心弦似乎动了那么一下。他知道,他所期待的,终于是要来的……"
}
POST book/_doc/9
{
"name": "彼岸天都",
"publisher": "万卷出版公司",
"publishedDate": "2008-11",
"page": 351,
"price": 23.90,
"isbn": "9787807593768",
"author": [
{
"name": "辛晓娟",
"nickname": "步非烟",
"gender": "女",
"birth": "1981-07-11",
"birthplace": "四川成都",
"position": "中国人民大学国学院副教授",
"avatar": "https://img9.doubanio.com/view/subject/s/public/s1537994.jpg"
}
],
"cover": "https://img2.doubanio.com/view/subject/s/public/s3370111.jpg",
"bind": "平装",
"series": "华音流韶",
"info": "等待彼岸的爱石破天惊…… 仰望,是你的姿态,前生后世,千年如是。仰望,却不是卑微,而是一点执著。为爱执著,所以仰望。守候,是你的方式,三界轮回,未改痴心。守候,却不是软弱,而是一生坚强。为爱坚强,所以守候。阿阁夭桃寂寞春,便辞阊阖入龙津。我空有一切,却什么也不能给你。四天令传说为诸神遗落人间的神器,有开天辟地的力量。图谋远大的吴越王从怪人日曜处得知这个传说,亲往苗疆。吴越王抓走苗疆首领的女儿吉娜,以换取上古神器四天令,却引来更多人的争夺。嵩山之巅,卓王孙与武林盟主杨逸之一战,天下震动。日曜借预言之力,推断出相思是一位异族女神转世,她要用相思的心血将四天令熔铸成湿婆之箭。吴越王得到日曜的帮助,一心搜集上古神器四天令,以获取一统天下的力量。被奉为武林砥柱的武当三老莫名陨命,陈尸少林寺门口。杨逸之为避免天下浩劫,独闯华音,与卓王孙定下三月之月查明真相。杨逸之追踪线索却被吴越王偷袭成重伤,失去仗以纵横天下的风月之力。与公主交换了身份相思从井底现身。神秘少年重劫自称看到神谕,相思是唯一能改变荒城命运的莲花天女,相思决然承担起这个使命。重劫劫持相思威胁杨逸之,最终杨逸之沦为梵天的傀儡……"
}
POST book/_doc/10
{
"name": "华音流韶·梵花坠影",
"publisher": "万卷出版公司",
"publishedDate": "2010-06",
"page": 439,
"price": 29.00,
"isbn": "9787501228294",
"author": [
{
"name": "辛晓娟",
"nickname": "步非烟",
"gender": "女",
"birth": "1981-07-11",
"birthplace": "四川成都",
"position": "中国人民大学国学院副教授",
"avatar": "https://img9.doubanio.com/view/subject/s/public/s1537994.jpg"
}
],
"cover": "https://img2.doubanio.com/view/subject/s/public/s4408641.jpg",
"bind": "平装",
"series": "华音流韶",
"info": "幽冥岛之上,步小鸾之死,令卓王孙萌生天下缟素之心,数月之后,倭军进犯朝鲜,战火肆虐,朝鲜几近沦陷。大明国师吴清风随御驾轻乘至御宿山——华音阁之境,以天下生灵涂炭之大难,请卓王孙出山,平定朝鲜之乱。卓王孙意外应允,并提出三个条件,将明军执于掌中,要求统领正道的武林盟主杨逸之也听命于他,吴清风也答应了他令全天下缟素的要求,至此,朝鲜,已成卓王孙的战场,或者,是他与杨逸之的战场。朝鲜战场上,日出之国关白平秀吉蓄势以待,手握强悍兵力的他,能身化三千,实力诡谲莫测。而几场战争中,卓杨二人联手,大败倭军。相思为探敌情,深入险境,并为探得平秀吉的真身而滞留。杨逸之欲带走相思,却再次失败,这个时候,卓王孙为达到天下缟素的目的,做出让人无法捉摸的举动,令己方损失惨重,而永乐的到来令卓杨二人的矛盾激化,灵山一役,卓杨正式决裂,朝鲜战场出现三足鼎立之势,平秀吉暗中使计,令卓王孙误解相思和杨逸之,三人之间裂痕加深,更在婚礼上引出一场风波,最终卓王孙迎娶永乐,相思出走。倾心于杨逸之的永乐公主自残于三军之前,使得卓王孙天下缟素的计划面临破灭,天下,又将如何迎来他们的结局?当最初的一场回眸落了一泓剑光,非愿之莲,相思千里,暮云深处,难觅众神。"
}
POST book/_doc/11
{
"name": "武林客栈·月阙卷",
"publisher": "世界知识出版社",
"publishedDate": "2006-11",
"page": 294,
"price": 22.00,
"isbn": "9787501230402",
"author": [
{
"name": "辛晓娟",
"nickname": "步非烟",
"gender": "女",
"birth": "1981-07-11",
"birthplace": "四川成都",
"position": "中国人民大学国学院副教授",
"avatar": "https://img9.doubanio.com/view/subject/s/public/s1537994.jpg"
}
],
"cover": "https://img3.doubanio.com/view/subject/s/public/s1987847.jpg",
"bind": "平装",
"series": "武林客栈",
"info": "《武林客栈》(月阙卷)讲述在“武林客栈”中奇诡悬疑成为了作品的主调。一开篇,剑神郭敖、医神李清愁、捕神铁恨几乎同是接到财神帖本身就是一个极大的悬疑所在。他们历尽千辛万苦来到武林客栈,经过一番生死拼斗后,又陷入魔教这个大悬疑中,最终一切悬疑都在少林寺解开。可以说全篇就是郭敖、李清愁、铁恨三人不断遭遇悬疑不断破解悬疑的过程。同时,各种奇技异术不断出现,让人有眼花缭乱之感,又吸引读者继续阅读下去。而本册中的附录——武林客栈外传《啸血飞鹰》这是首次与众人见面!"
}
POST book/_doc/12
{
"name": "华音流韶·雪嫁衣",
"publisher": "万卷出版公司",
"publishedDate": "2009-10",
"page": 345,
"price": 29.00,
"isbn": "9787547002872",
"author": [
{
"name": "辛晓娟",
"nickname": "步非烟",
"gender": "女",
"birth": "1981-07-11",
"birthplace": "四川成都",
"position": "中国人民大学国学院副教授",
"avatar": "https://img9.doubanio.com/view/subject/s/public/s1537994.jpg"
}
],
"cover": "https://img9.doubanio.com/view/subject/s/public/s4028735.jpg",
"bind": "平装",
"series": "华音流韶",
"info": "何为天下?天下,是最初诞生的文明。天下,即我。何为天下?振长策而御宇内,吞二周而亡诸侯,威震四海。天下,是始皇帝之残暴,之威严。犯强汉者,虽远必诛。天下,是汉武帝之骄傲,之武功。万国来宾,为天可汗。天下,是唐率宗之雍容,之文明。何为天下?站在御宿山上,周围三十六里,便是天下。武功文化,秦皇汉武,英雄豪杰,都毫无意义。只因这里有一个绝顶的名——华音阁。步非烟“华音流韶”系列之七。华音阁阁主卓王孙为了医治妹妹小鸾,决定前往海外寻医,途中遇见海岛幻境,更有杀手拦路。而秋璇为了救落入魔手的相思,以自己作为交换,共赴苍茫大海。千里之外的武林盟主杨逸之,亲率两千江湖人士抗倭保国。每个人有不同的目的,却仿佛被命运牵引,最终来到一个以幽冥为名的岛上,于是一场天下浩劫就此开始了……"
}
POST book/_doc/13
{
"name": "玫瑰帝国·潘多拉之盒",
"publisher": "湖南少年儿童出版社",
"publishedDate": "2012-04",
"page": 312,
"price": 24.80,
"isbn": "9787535878144",
"author": [
{
"name": "辛晓娟",
"nickname": "步非烟",
"gender": "女",
"birth": "1981-07-11",
"birthplace": "四川成都",
"position": "中国人民大学国学院副教授",
"avatar": "https://img3.doubanio.com/view/personage/raw/public/ed958c3afddfcc2f56c97532ead77dda.jpg"
}
],
"cover": "https://img2.doubanio.com/view/subject/s/public/s27224291.jpg",
"bind": "平装",
"series": "玫瑰帝国",
"info": "千万富翁杀手之谜解开后,华音大学看似风平浪静,却有更大的阴谋在酝酿……相思和室友去酒吧喝酒,喝完酒后却都有怪异表现:相思梦见自己穿越到古代,并面临满门抄斩;莱拉看见图书馆前的石狮竟张牙舞爪变成怪兽,意欲吃人;玄田田则力大无穷喝光了酒吧所有的酒,这一切真的只是巧合吗?秋旋和卓王孙打赌,牵连出少年教授杨逸之。相思被惊心的梦境困扰,误打误撞的引起了杨逸之对此事的兴趣,两人一去酒吧调查时,遇到了少女巨星candy,candy对杨逸之颇有好感。随即,杨逸之发现candy似乎被人追杀,对方凶残异常,不似正常人类。在侦破真相的过程中,他与相思发现了51区的一项惊人机密,而与此同时,另一重生死攸关的惊天阴谋正危险袭来……"
}
POST book/_doc/14
{
"name": "葬雪",
"publisher": "万卷出版公司",
"publishedDate": "2009-06",
"page": 280,
"price": 29.00,
"isbn": "9787807599074",
"author": [
{
"name": "辛晓娟",
"nickname": "步非烟",
"gender": "女",
"birth": "1981-07-11",
"birthplace": "四川成都",
"position": "中国人民大学国学院副教授",
"avatar": "https://img3.doubanio.com/view/personage/raw/public/ed958c3afddfcc2f56c97532ead77dda.jpg"
}
],
"cover": "https://img1.doubanio.com/view/subject/s/public/s3901739.jpg",
"bind": "平装",
"series": "天舞系列",
"info": "苏犹怜是一只卑微的雪妖,只能卫护自己的爱情。于是她来到了龙皇石星御的城堡,撒了个弥天大谎,说可以用五行阵来让九灵儿复活,其实是要趁这机会把龙皇杀死,这样她心爱的李玄也就不会成魔。但是一切都落入了大唐太子的阴谋。李玄对苏犹怜的误解使得自己在得到宝物之时选择了遗忘。苏犹怜完全忘记了李玄曾经做过什么。她要好好待他,让他重新爱上她。她会无微不至地关怀他,让他跟他的爱情一起成长。在五行阵运行苏犹怜跳了天葬之舞九灵儿显现却又在瞬间化成飞灰的刹那,石星御心灵最为脆弱之际,苏犹怜却并没有真正杀死龙皇,而龙皇却选择了为救她置自己生死不顾。苏犹怜活了下来,成为了九灵儿的影子。"
}
POST book/_doc/15
{
"name": "魅月",
"publisher": "万卷出版公司",
"publishedDate": "2009-06",
"page": 321,
"price": 29.00,
"isbn": "9787807599081",
"author": [
{
"name": "辛晓娟",
"nickname": "步非烟",
"gender": "女",
"birth": "1981-07-11",
"birthplace": "四川成都",
"position": "中国人民大学国学院副教授",
"avatar": "https://img3.doubanio.com/view/personage/raw/public/ed958c3afddfcc2f56c97532ead77dda.jpg"
}
],
"cover": "https://img1.doubanio.com/view/subject/s/public/s3901740.jpg",
"bind": "平装",
"series": "天舞系列",
"info": "你必将与你的爱情同归于尽,洞穿轮回的咒语,最后的爱情魂器。爱如庞贝,灭迹在辉煌盛唐。人类最灿烂的大唐盛世。有一座摩云书院,招收的第一位学徒,竟是一位浪迹江湖的小混混——李玄。李玄不学无术,只是误打误撞进入摩云书院,又莫名其妙地成为大师兄,享书院中诸多特权。李玄不求上进,并不将这些特权用于修炼道术上,而是四处探险游玩,顺便完成师妹苏犹怜对他的种种怪异至极、也危险至极的爱情考验。苏犹怜为了得到永久的爱情而不得已必须杀死李玄,她利用了天竺王子龙穆来制造幻境,却引来了梦魔。梦魔在书院里开始杀人,李玄的梦中只要有红色的妖月出现,就肯定会出事情。为了解开这个谜团也为了保护苏犹怜,李玄和梦魔进行了殊死之战。他发现,梦魔原来是龙穆的前世,他找到了龙穆并且在杀满7个人的时候会真正地复活。李玄为了打败梦魔而不断交换自己最珍贵的东西,在心灵之珠幻化出苏犹怜的影子时他放弃了交换选择了自杀,而这却是梦魔的死穴。苏犹怜也因此发现了李玄对她的挚爱,为了保卫这份爱,她毅然做出了刺杀龙皇的决定。"
}
POST book/_doc/16
{
"name": "紫诏天音",
"publisher": "21世纪出版社",
"publishedDate": "2007-01",
"page": 260,
"price": 22.00,
"isbn": "9787539135847",
"author": [
{
"name": "辛晓娟",
"nickname": "步非烟",
"gender": "女",
"birth": "1981-07-11",
"birthplace": "四川成都",
"position": "中国人民大学国学院副教授",
"avatar": "https://img3.doubanio.com/view/personage/raw/public/ed958c3afddfcc2f56c97532ead77dda.jpg"
}
],
"cover": "https://img9.doubanio.com/view/subject/s/public/s2975105.jpg",
"bind": "平装",
"series": "华音流韶",
"info": "这是一片风景瑰丽的山水世界,也是一个血雨腥风的热血江湖。四天令,意味着多年前所埋葬的一座巨大的宝藏。而只有将四天令集于一手,才能成为打开宝藏的钥匙。于是,原本平静的江湖渐起波澜。而吉娜,一个与这华丽诡奇的梦境格格不入、一个单纯的只想寻找到八年前那双与自己纠缠一生的眼睛的山林的孩子,带着她的梦想,进入风起云涌的江湖,邂逅惊才绝艳的侠客,探询三生三世的传说……但她实在是太纯净、单薄,她柔弱的双翼无法承载起这样瑰玮的梦想,这个宏大的江湖中,精灵一般的她,注定了只是配角。她注定了,要隔着遥远的时空,羡慕地仰望神祇一般出入风云的人物……"
}
POST book/_doc/17
{
"name": "武林客栈·星涟卷",
"publisher": "世界知识出版社",
"publishedDate": "2007-01",
"page": 287,
"price": 22.00,
"isbn": "9787501230792",
"author": [
{
"name": "辛晓娟",
"nickname": "步非烟",
"gender": "女",
"birth": "1981-07-11",
"birthplace": "四川成都",
"position": "中国人民大学国学院副教授",
"avatar": "https://img3.doubanio.com/view/personage/raw/public/ed958c3afddfcc2f56c97532ead77dda.jpg"
}
],
"cover": "https://img1.doubanio.com/view/subject/s/public/s2975149.jpg",
"bind": "平装",
"series": "武林客栈",
"info": "《武林客栈》(星涟卷文化底蕴扑面,文字功底娴熟,以神韵走工尺,玩小兽若大虫,有举轻若重之概,兼好整以暇之雅。凌波人不见,江上一云轻。若持此为业,鸿程岂可量哉!"
}
POST book/_doc/18
{
"name": "风月连城",
"publisher": "21世纪出版社",
"publishedDate": "2007-06",
"page": 278,
"price": 22.00,
"isbn": "9787539137575",
"author": [
{
"name": "辛晓娟",
"nickname": "步非烟",
"gender": "女",
"birth": "1981-07-11",
"birthplace": "四川成都",
"position": "中国人民大学国学院副教授",
"avatar": "https://img3.doubanio.com/view/personage/raw/public/ed958c3afddfcc2f56c97532ead77dda.jpg"
}
],
"cover": "https://img9.doubanio.com/view/subject/s/public/s2975146.jpg",
"bind": "平装",
"series": "华音流韶",
"info": "为与卓王孙“天下”一诺,风流骏赏的武林盟主杨逸之来到漠上,用一袭白衣,万朵桃花,弹奏出一曲千古风流的《郁轮袍》。可惜世事变幻,天涯隔知音。为救他生命中的公主,杨逸之于千军万马中浴血杀进杀出,更身陷地底之城,被作为非天向梵天所供奉的祭品。谶语迭出,江湖风波恶,漠上风尘,万里独人归。而当尘埃化成的一切蓦然在历史中沉碎时,那白色的妖魔发出了凄楚的怒啸。那是流传千年万年的悲哀,更如一件件隐秘出现的天人五衰一般,降临在杨逸之和相思身上。天人将命尽,重入六道轮回。谁是这个谶语的起咒人?谁又是谶语的应验者?谁是宿命的操盘手?谁又是宿命的演绎道具?精彩绝伦、悬念迭起,传奇女子步非烟妙笔演绎……"
}
23.1 Terms Aggregation
分组聚合。如:统计各个出版社出版的图书总数量
1
2
3
4
5
6
7
8
9
10
11
GET book/_search
{
"aggs": {
"terms_query": {
"terms": {
"field": "publisher",
"size": 10
}
}
}
}

在 terms 分桶的基础上还可以对每个桶进行指标聚合。
统计不同出版社所出版图书的平均价格:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
GET book/_search
{
"aggs": {
"terms_query": {
"terms": {
"field": "publisher",
"size": 10
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}

23.2 Filter Aggregation
过滤聚合。可以将符合过滤条件的文档分到一个桶中,然后再进行指标聚合。
如:查询书名中包含 “华” 图书的平均价格
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
GET book/_search
{
"aggs": {
"filter_query": {
"filter": {
"term": {
"name": "华"
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
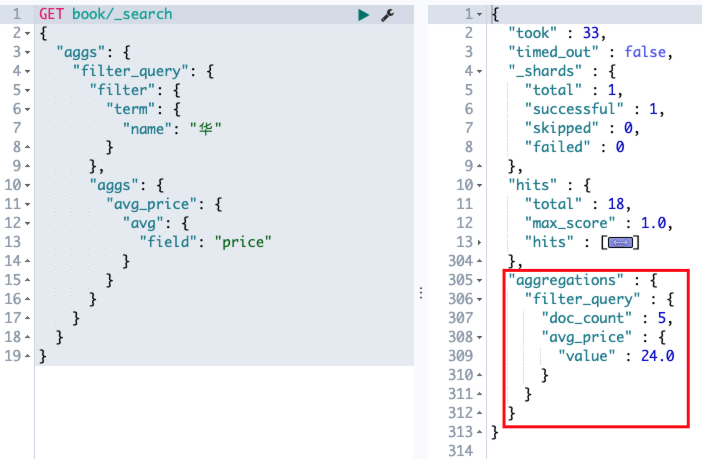
23.3 Filters Aggregation
多过滤器聚合。
如:查询书名中包含 “华” 或者 “玫瑰” 图书的平均价格
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
GET book/_search
{
"aggs": {
"filters_query": {
"filters": {
"filters": [
{
"term": {
"name": "华"
}
},
{
"term": {
"name": "帝"
}
}
]
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
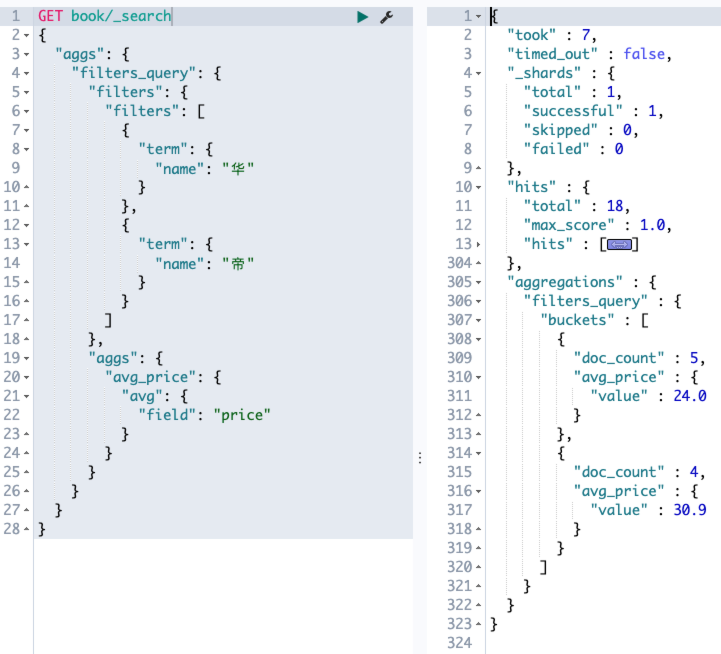
23.4 Range Aggregation
范围聚合。如:统计价格在 0-10、10-20、20-30、30-40、40-50、50 以上的图书数量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
GET book/_search
{
"aggs": {
"range_query": {
"range": {
"field": "price",
"ranges": [
{
"to": 10
},
{
"from": 10,
"to": 20
},
{
"from": 20,
"to": 30
},
{
"from": 30,
"to": 40
},
{
"from": 40,
"to": 50
},
{
"from": 50
}
]
}
}
}
}

23.5 Date Range Aggregation
Range Aggregation 可以用来统计日期,但推荐使用 Date Range Aggregation,时间范围聚合的优势在于可以使用日期表达式。
如:10 年内出版图书
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
GET book/_search
{
"aggs": {
"date_range_query": {
"date_range": {
"field": "publishedDate",
"ranges": [
{
"from": "now-10y/y",
"to": "now"
}
]
}
}
}
}
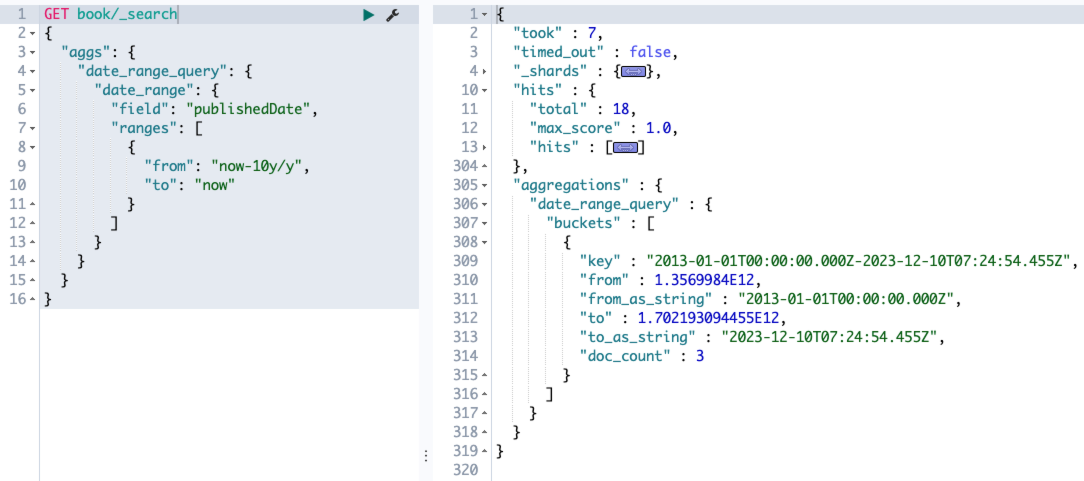
- y 表示 年
- M 表示 月
- d 表示 天
23.6 Date Histogram Aggregation
时间直方图聚合。
ES6:
1
2
3
4
5
6
7
8
9
10
11
GET book/_search
{
"aggs": {
"date_histogram_query": {
"date_histogram": {
"field": "publishedDate",
"interval": "year"
}
}
}
}
ES7:
1
2
3
4
5
6
7
8
9
10
11
GET book/_search
{
"aggs": {
"date_histogram_query": {
"date_histogram": {
"field": "publishedDate",
"calendar_interval": "year"
}
}
}
}
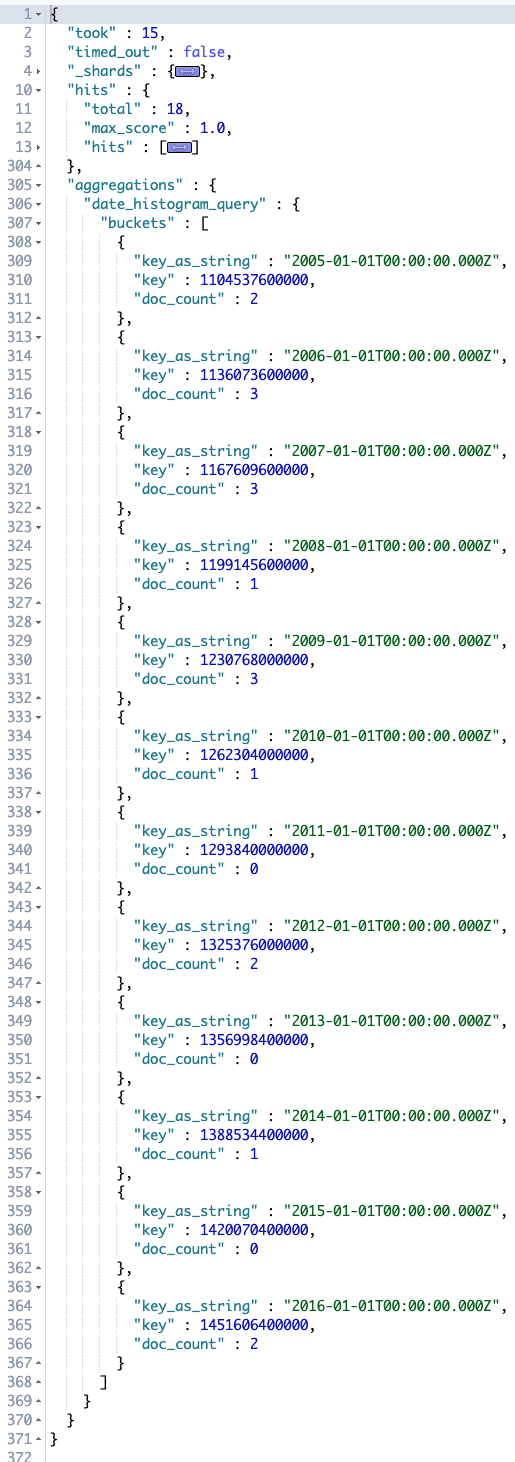
- year 年
- month 月
- day 天
23.7 Missing Aggregation
空值聚合。如:统计所有没有 page 字段的文档:
1
2
3
4
5
6
7
8
9
10
GET book/_search
{
"aggs": {
"missing_query": {
"missing": {
"field": "page"
}
}
}
}
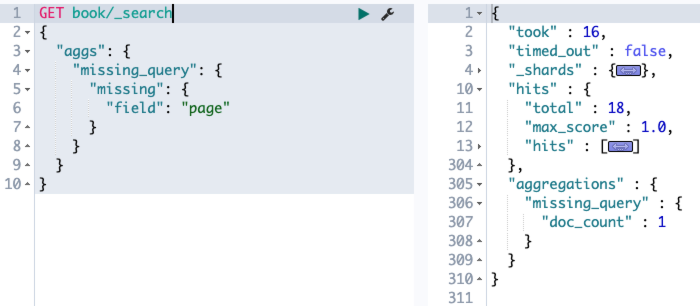
23.8 Children Aggregation
根据父子文档关系进行分桶。
1
2
3
4
5
6
7
8
9
10
GET class_student/_search
{
"aggs": {
"NAME": {
"children": {
"type": "student"
}
}
}
}
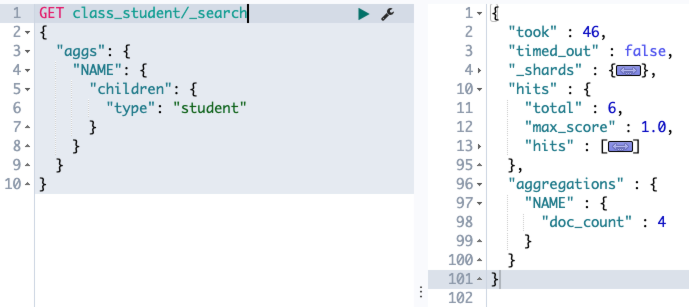
23.9 Geo Distance Aggregation
对地理位置数据做统计。如:查询太原(112.55640,37.87699)方圆 300KM、300KM到600KM、超过600KM 的城市数量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
GET geo/_search
{
"aggs": {
"NAME": {
"geo_distance": {
"field": "location",
"unit": "km",
"origin": {
"lat": 37.87699,
"lon": 112.55640
},
"ranges": [
{
"to": 300
},
{
"from": 300,
"to": 600
},
{
"from": 600
}
]
}
}
}
}
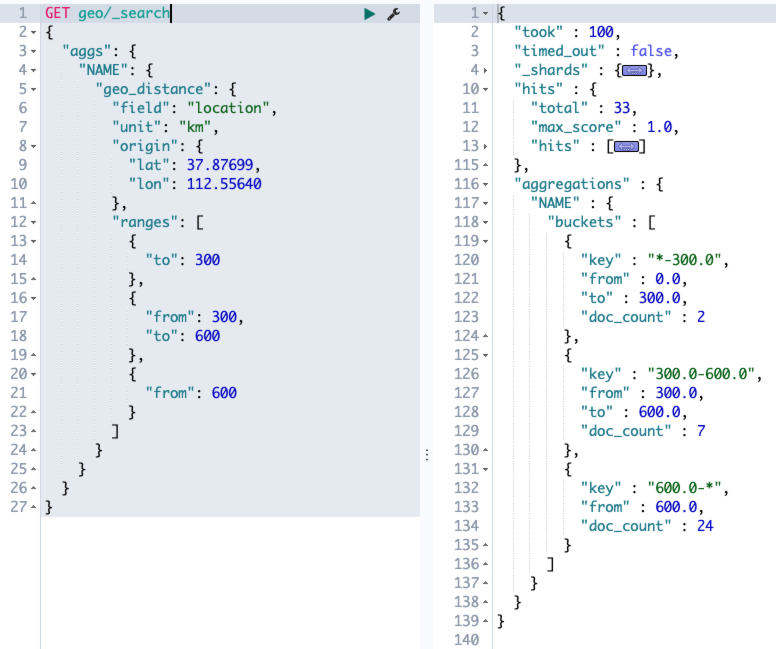
23.10 IP Range Aggregation
IP 地址范围查询。
新建索引:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
PUT ip?include_type_name=false
{
"mappings": {
"properties": {
"ip": {
"type": "ip"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
添加数据:
1
2
3
4
5
6
7
8
9
10
11
12
POST ip/_doc/1
{
"ip": "127.0.0.1"
}
POST ip/_doc/2
{
"ip": "127.0.0.2"
}
POST ip/_doc/3
{
"ip": "127.0.0.3"
}
查询:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
GET ip/_search
{
"aggs": {
"ip_range_query": {
"ip_range": {
"field": "ip",
"ranges": [
{
"from": "127.0.0.1",
"to": "127.0.0.5"
}
]
}
}
}
}
24 ElasticSearch 管道聚合
管道聚合相当于在之前聚合的基础上,再次聚合。
24.1 Avg Bucket Aggregation
计算聚合平均值。如:先统计各个出版社图书的平均价格,然后在平均值的基础上再统计平均值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
GET book/_search
{
"aggs": {
"terms_publisher": {
"terms": {
"field": "publisher",
"size": 10
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
},
"avg_price": {
"avg_bucket": {
"buckets_path": "terms_publisher>avg_price"
}
}
}
}

24.2 Max Bucket Aggregation
计算聚合最大值。如:先统计各个出版社图书的平均价格,然后在平均值的基础上再统计最大值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
GET book/_search
{
"aggs": {
"terms_publisher": {
"terms": {
"field": "publisher",
"size": 10
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
},
"max_price": {
"max_bucket": {
"buckets_path": "terms_publisher>avg_price"
}
}
}
}

24.3 Min Bucket Aggregation
计算聚合最小值。如:先统计各个出版社图书的平均价格,然后在平均值的基础上再统计最小值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
GET book/_search
{
"aggs": {
"terms_publisher": {
"terms": {
"field": "publisher",
"size": 10
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
},
"min_price": {
"min_bucket": {
"buckets_path": "terms_publisher>avg_price"
}
}
}
}

24.4 Sum Bucket Aggregation
聚合的基础上求和。如:先统计各个出版社图书的平均价格,然后在平均值的基础上求和
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
GET book/_search
{
"aggs": {
"terms_publisher": {
"terms": {
"field": "publisher",
"size": 10
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
},
"sum_price": {
"sum_bucket": {
"buckets_path": "terms_publisher>avg_price"
}
}
}
}

24.5 Stats Bucket Aggregation
聚合的基础上统计各种数据。如:先统计各个出版社图书的平均价格,然后在平均值的基础上统计各种数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
GET book/_search
{
"aggs": {
"terms_publisher": {
"terms": {
"field": "publisher",
"size": 10
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
},
"stats_price": {
"stats_bucket": {
"buckets_path": "terms_publisher>avg_price"
}
}
}
}

24.6 Extended Stats Bucket Aggregation
聚合的基础上统计各种数据。如:先统计各个出版社图书的平均价格,然后在平均值的基础上统计各种数据
比 stats 多一些属性:平方和、方差、标准差、平均值加减两个标准差的区间
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
GET book/_search
{
"aggs": {
"terms_publisher": {
"terms": {
"field": "publisher",
"size": 10
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
},
"extended_stats_price": {
"extended_stats_bucket": {
"buckets_path": "terms_publisher>avg_price"
}
}
}
}

24.7 Percentiles Bucket Aggregation
聚合的基础上统计各种数据。如:先统计各个出版社图书的平均价格,然后在平均值的基础上统计百分位
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
GET book/_search
{
"aggs": {
"terms_publisher": {
"terms": {
"field": "publisher",
"size": 10
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
},
"percentiles_price": {
"percentiles_bucket": {
"buckets_path": "terms_publisher>avg_price",
"percents": [
1,
5,
25,
50,
75,
95,
99
]
}
}
}
}

25 ElasticSearch Java API
Java 操作 ES 的方案:
1、直接使用 HTTP 请求
直接使用 HTTP 请求,去操作 ES。HTTP 请求工具,可以使用 Java 自带的 HttpUrlConnection,也可以使用一些 HTTP 请求库,例如 HttpClient、OkHttp、 Spring 中的 RestTemplate 等。这种方式有一个弊端,就是需要自己组装请求參数,自己去解析响应的 JSON。
2、Low Level REST Client
ES 官方的低级客户端。这种方式允许通过 HTTP 与 ES 集群进行通信,但请求的 JSON 参数和响应的 JSON 参数交给用户去处理。这种方式兼容所有的 ES 版本,但数据处理比较麻烦。
2、High Level REST Client
ES 官方的高级客户端。这种方式允许通过 HTTP 与 ES 集群进行通信,它是基于 Low Level REST Client 的,但内部提供了很多 API,开发者不需要自己去组装参数,也不需要自己去解析响应的 JSON。这种方式使用起来更加直接。但需要注意,这种方式所使用的依赖库版本要和 ES 对应。
4、TransportClient
TransportClient 在 ES7 中已经被弃用,在 ES8 中将被完全删除。前面的三种是 RESTful HTTP 请求,请求的是 9200 端口;而 TransportClient 是 TCP 请求,请求的是 9300 端口。
25.1 普通 HTTP 请求
- Java HttpURLConnection
1
2
3
4
5
6
7
8
9
10
11
12
13
@Test
@SneakyThrows
void test01() {
URL url = new URL("http://localhost:9200/book/_search?pretty=true");
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
if (HttpStatus.OK.value() == connection.getResponseCode()) {
BufferedReader br = new BufferedReader(new InputStreamReader(connection.getInputStream()));
String str;
while ((str = br.readLine()) != null) {
System.out.println(str);
}
}
}
- Spring RestTemplate + Apache HttpClient(请求池)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
@Test
void test02() {
String uri = "http://localhost:9200/book/_search?pretty=true";
ResponseEntity<Object> response = restTemplate.getForEntity(uri, Object.class);
if (HttpStatus.OK.equals(response.getStatusCode())) {
System.out.println(response.getBody());
}
MultiValueMap<String, String> headers = new LinkedMultiValueMap<>();
headers.add("Content-Type", MediaType.APPLICATION_FORM_URLENCODED_VALUE);
HttpEntity<MultiValueMap<String, String>> request = new HttpEntity<>(headers);
response = restTemplate.postForEntity(uri, request, Object.class);
if (HttpStatus.OK.equals(response.getStatusCode())) {
System.out.println(response.getBody());
}
}
25.2 Java Low Level REST Client
添加依赖:
1
2
3
4
5
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>6.8.23</version>
</dependency>
样例:
1
2
3
4
5
6
7
8
9
10
GET book/_search?pretty=true
{
"query": {
"term": {
"name": {
"value": "华"
}
}
}
}
常量:
1
2
3
4
5
private final static String SCHEMA_HTTP_PROTOCOL = "http";
private final static String HOST_NAME = "localhost";
private final static int MASTER_PORT = 9200;
private final static int SALVE_ONE_PORT = 9201;
private final static int SALVE_TWO_PORT = 9202;
同步请求:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
/**
* 同步请求
*/
@SneakyThrows
private static void test01() {
// 1.创建 RestClientBuilder
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(HOST_NAME, MASTER_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_ONE_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_TWO_PORT, SCHEMA_HTTP_PROTOCOL)
);
// 2.设置请求头
restClientBuilder.setDefaultHeaders(new Header[]{
new BasicHeader("Content-Type", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept-Charset", CharsetUtil.UTF_8)
});
// 3.构建一个 RestClient 对象
RestClient restClient = restClientBuilder.build();
// 4.构建请求
Request request = new Request(HttpMethod.GET.name(), "/book/_search");
// 5.添加请求参数
request.addParameter("pretty", "true");
// 6.添加请求体
request.setEntity(new NStringEntity("{\"query\":{\"term\":{\"name\":{\"value\":\"华\"}}}}", ContentType.APPLICATION_JSON));
// 7.发起请求(同步请求)
Response response = restClient.performRequest(request);
// 8.解析 response,获取响应结果
BufferedReader br = new BufferedReader(new InputStreamReader(response.getEntity().getContent()));
String str;
while ((str = br.readLine()) != null) {
System.out.println(str);
}
// 9.关闭 RestClient
restClient.close();
}
异步请求:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
/**
* 异步请求
*/
@SneakyThrows
private static void test02() {
// 1.创建 RestClientBuilder
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(HOST_NAME, MASTER_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_ONE_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_TWO_PORT, SCHEMA_HTTP_PROTOCOL)
);
// 2.设置请求头
restClientBuilder.setDefaultHeaders(new Header[]{
new BasicHeader("Content-Type", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept-Charset", CharsetUtil.UTF_8)
});
// 3.构建一个 RestClient 对象
RestClient restClient = restClientBuilder.build();
// 4.构建请求
Request request = new Request(HttpMethod.GET.name(), "/book/_search");
// 5.添加请求参数
request.addParameter("pretty", "true");
// 6.添加请求体
request.setEntity(new NStringEntity("{\"query\":{\"term\":{\"name\":{\"value\":\"华\"}}}}", ContentType.APPLICATION_JSON));
// 7.发起请求(异步请求)
restClient.performRequestAsync(request, new ResponseListener() {
@Override
public void onSuccess(Response response) {
// 8.解析 response,获取响应结果
try {
BufferedReader br = new BufferedReader(new InputStreamReader(response.getEntity().getContent()));
String str;
while ((str = br.readLine()) != null) {
System.out.println(str);
}
// 9.关闭 RestClient
restClient.close();
} catch (IOException e) {
log.error(e.getMessage());
}
}
@Override
public void onFailure(Exception e) {
log.error(e.getMessage());
}
});
}
执行:
1
2
3
4
5
6
7
8
@Test
void test() {
test01();
}
public static void main(String[] args) {
test02();
}
25.3 Java High Level REST Client
添加依赖:(版本必须一致)
1
2
3
4
5
6
7
8
9
10
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>6.8.23</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>6.8.23</version>
</dependency>
25.3.1 索引管理
25.3.1.1 创建索引
样例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
PUT novel?include_type_name=false
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"publisher": {
"type": "keyword"
},
"publishedDate": {
"type": "date"
},
"page": {
"type": "integer"
},
"price": {
"type": "scaled_float",
"scaling_factor": 100
},
"isbn": {
"type": "keyword"
},
"author": {
"type": "nested",
"properties": {
"name": {
"type": "keyword"
},
"nickname": {
"type": "keyword"
},
"gender": {
"type": "keyword"
},
"birth": {
"type": "date"
},
"birthplace": {
"type": "keyword"
},
"position": {
"type": "text",
"analyzer": "ik_max_word"
},
"avatar": {
"type": "keyword"
}
}
},
"cover": {
"type": "keyword"
},
"info": {
"type": "text",
"analyzer": "ik_max_word"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"aliases": {
"novel_alias": {}
}
}
常量:
1
2
3
4
5
6
7
8
9
10
private final static String SCHEMA_HTTP_PROTOCOL = "http";
private final static String HOST_NAME = "localhost";
private final static int MASTER_PORT = 9200;
private final static int SALVE_ONE_PORT = 9201;
private final static int SALVE_TWO_PORT = 9202;
private final static String INDEX_NAME = "novel";
private final static String INDEX_NAME_ALIAS = "novel_alias";
private final static long TIMEOUT = 3;
private final static long MASTER_TIMEOUT = 5;
字段类型通过 JSON 字符串构建(同步请求):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
/**
* 字段类型通过 JSON 字符串构建(同步请求)
*/
@SneakyThrows
private static void test01() {
// 创建 RestClientBuilder
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(HOST_NAME, MASTER_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_ONE_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_TWO_PORT, SCHEMA_HTTP_PROTOCOL)
);
// 设置请求头
restClientBuilder.setDefaultHeaders(new Header[]{
new BasicHeader("Content-Type", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept-Charset", CharsetUtil.UTF_8)
});
// 构建一个 RestHighLevelClient 对象
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
// 查询索引请求
GetIndexRequest getIndexRequest = new GetIndexRequest(INDEX_NAME);
// 连接所有节点的请求超时时间
getIndexRequest.setTimeout(TimeValue.timeValueSeconds(TIMEOUT));
// 连接 Master 节点的请求超时时间
getIndexRequest.setMasterTimeout(TimeValue.timeValueSeconds(MASTER_TIMEOUT));
// 是否存在索引
if (restHighLevelClient.indices().exists(getIndexRequest, RequestOptions.DEFAULT)) {
// 删除索引请求
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest(INDEX_NAME);
// 删除索引
restHighLevelClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);
}
// 创建索引请求
CreateIndexRequest createIndexRequest = new CreateIndexRequest(INDEX_NAME);
// 配置 settings(分片、副本)
createIndexRequest.settings(Settings.builder().put("index.number_of_shards", 1).put("index.number_of_replicas", 1));
// 配置 mappings properties(字段类型),字段类型可以通过 JSON 字符串(推荐)、Map(不建议使用,非常麻烦)以及 XContentBuilder(不建议使用,非常麻烦)三种方式来构建
createIndexRequest.mapping("{\"properties\":{\"title\":{\"type\":\"text\",\"analyzer\":\"ik_max_word\",\"fields\":{\"keyword\":{\"type\":\"keyword\"}}},\"publisher\":{\"type\":\"keyword\"},\"publishedDate\":{\"type\":\"date\"},\"page\":{\"type\":\"integer\"},\"price\":{\"type\":\"scaled_float\",\"scaling_factor\":100},\"isbn\":{\"type\":\"keyword\"},\"author\":{\"type\":\"nested\",\"properties\":{\"name\":{\"type\":\"keyword\"},\"nickname\":{\"type\":\"keyword\"},\"gender\":{\"type\":\"keyword\"},\"birth\":{\"type\":\"date\"},\"birthplace\":{\"type\":\"keyword\"},\"position\":{\"type\":\"text\",\"analyzer\":\"ik_max_word\"},\"avatar\":{\"type\":\"keyword\"}}},\"cover\":{\"type\":\"keyword\"},\"info\":{\"type\":\"text\",\"analyzer\":\"ik_max_word\"}}}", XContentType.JSON);
// 设置别名
createIndexRequest.alias(new Alias(INDEX_NAME_ALIAS));
// 同步创建索引
restHighLevelClient.indices().create(createIndexRequest, RequestOptions.DEFAULT);
// 关闭 RestHighLevelClient
restHighLevelClient.close();
}
全部通过 JSON 字符串构建(异步请求):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
/**
* 全部通过 JSON 字符串构建(异步请求)
*/
@SneakyThrows
private static void test02() {
// 创建 RestClientBuilder
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(HOST_NAME, MASTER_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_ONE_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_TWO_PORT, SCHEMA_HTTP_PROTOCOL)
);
// 设置请求头
restClientBuilder.setDefaultHeaders(new Header[]{
new BasicHeader("Content-Type", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept-Charset", CharsetUtil.UTF_8)
});
// 构建一个 RestHighLevelClient 对象
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
// 查询索引请求
GetIndexRequest getIndexRequest = new GetIndexRequest(INDEX_NAME);
// 连接所有节点的请求超时时间
getIndexRequest.setTimeout(TimeValue.timeValueSeconds(5));
// 连接 Master 节点的请求超时时间
getIndexRequest.setMasterTimeout(TimeValue.timeValueSeconds(3));
// 是否存在索引
if (restHighLevelClient.indices().exists(getIndexRequest, RequestOptions.DEFAULT)) {
// 删除索引请求
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest(INDEX_NAME);
// 删除索引
restHighLevelClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);
}
// 创建索引请求
CreateIndexRequest createIndexRequest = new CreateIndexRequest(INDEX_NAME);
// 配置 settings、mappings、aliases,通过 JSON 字符串构建
createIndexRequest.source("{\"mappings\":{\"properties\":{\"title\":{\"type\":\"text\",\"analyzer\":\"ik_max_word\",\"fields\":{\"keyword\":{\"type\":\"keyword\"}}},\"publisher\":{\"type\":\"keyword\"},\"publishedDate\":{\"type\":\"date\"},\"page\":{\"type\":\"integer\"},\"price\":{\"type\":\"scaled_float\",\"scaling_factor\":100},\"isbn\":{\"type\":\"keyword\"},\"author\":{\"type\":\"nested\",\"properties\":{\"name\":{\"type\":\"keyword\"},\"nickname\":{\"type\":\"keyword\"},\"gender\":{\"type\":\"keyword\"},\"birth\":{\"type\":\"date\"},\"birthplace\":{\"type\":\"keyword\"},\"position\":{\"type\":\"text\",\"analyzer\":\"ik_max_word\"},\"avatar\":{\"type\":\"keyword\"}}},\"cover\":{\"type\":\"keyword\"},\"info\":{\"type\":\"text\",\"analyzer\":\"ik_max_word\"}}},\"settings\":{\"number_of_shards\":1,\"number_of_replicas\":1},\"aliases\":{\"novel_alias\":{}}}", XContentType.JSON);
// 异步创建索引
restHighLevelClient.indices().createAsync(createIndexRequest, RequestOptions.DEFAULT, new ActionListener<CreateIndexResponse>() {
@Override
public void onResponse(CreateIndexResponse createIndexResponse) {
// 关闭 RestHighLevelClient
try {
restHighLevelClient.close();
} catch (IOException e) {
log.info(e.getMessage());
}
}
@Override
public void onFailure(Exception e) {
}
});
}
25.3.1.2 关闭/打开索引
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
/**
* 关闭/打开索引
*/
@SneakyThrows
private static void test03() {
// 创建 RestClientBuilder
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(HOST_NAME, MASTER_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_ONE_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_TWO_PORT, SCHEMA_HTTP_PROTOCOL)
);
// 设置请求头
restClientBuilder.setDefaultHeaders(new Header[]{
new BasicHeader("Content-Type", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept-Charset", CharsetUtil.UTF_8)
});
// 构建一个 RestHighLevelClient 对象
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
// 关闭/打开索引请求
if (restHighLevelClient.indices().close(new CloseIndexRequest(INDEX_NAME), RequestOptions.DEFAULT).isAcknowledged()) {
log.info("索引已关闭");
if (restHighLevelClient.indices().open(new OpenIndexRequest(INDEX_NAME), RequestOptions.DEFAULT).isAcknowledged()) {
log.info("索引已打开");
}
}
// 关闭 RestHighLevelClient
restHighLevelClient.close();
}
25.3.1.3 编辑索引
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
/**
* 编辑索引
*/
@SneakyThrows
private static void test04() {
// 创建 RestClientBuilder
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(HOST_NAME, MASTER_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_ONE_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_TWO_PORT, SCHEMA_HTTP_PROTOCOL)
);
// 设置请求头
restClientBuilder.setDefaultHeaders(new Header[]{
new BasicHeader("Content-Type", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept-Charset", CharsetUtil.UTF_8)
});
// 构建一个 RestHighLevelClient 对象
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
// 创建编辑索引请求
UpdateSettingsRequest updateSettingsRequest = new UpdateSettingsRequest(INDEX_NAME);
// 修改 Settings 属性,关闭索引的写权限
updateSettingsRequest.settings(Settings.builder().put("index.blocks.write", true).build());
// 编辑索引请求
restHighLevelClient.indices().putSettings(updateSettingsRequest, RequestOptions.DEFAULT);
// 关闭 RestHighLevelClient
restHighLevelClient.close();
}
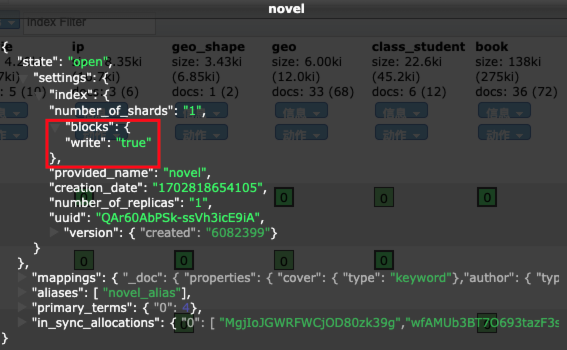
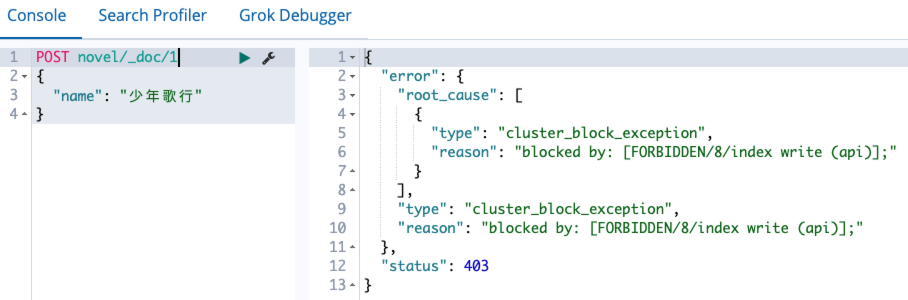
25.3.1.4 克隆索引
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
PUT novel_clone
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
POST _reindex
{
"source": {
"index": "novel"
},
"dest": {
"index": "novel_clone"
}
}
RestHighLevelClient 6 没有提供克隆索引的 API。
RestHighLevelClient 7:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
/**
* 克隆索引
*/
@SneakyThrows
private static void test05() {
// 创建 RestClientBuilder
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(HOST_NAME, MASTER_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_ONE_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_TWO_PORT, SCHEMA_HTTP_PROTOCOL)
);
// 设置请求头
restClientBuilder.setDefaultHeaders(new Header[]{
new BasicHeader("Content-Type", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept-Charset", CharsetUtil.UTF_8)
});
// 构建一个 RestHighLevelClient 对象
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
// 克隆索引请求
restHighLevelClient.indices().clone(new ResizeRequest(INDEX_NAME_CLONE, INDEX_NAME), RequestOptions.DEFAULT);
// 关闭 RestHighLevelClient
restHighLevelClient.close();
}
25.3.1.5 查看索引
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
/**
* 查看索引
*/
@SneakyThrows
private static void test05() {
// 创建 RestClientBuilder
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(HOST_NAME, MASTER_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_ONE_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_TWO_PORT, SCHEMA_HTTP_PROTOCOL)
);
// 设置请求头
restClientBuilder.setDefaultHeaders(new Header[]{
new BasicHeader("Content-Type", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept-Charset", CharsetUtil.UTF_8)
});
// 构建一个 RestHighLevelClient 对象
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
// 创建查看索引请求
GetSettingsRequest getSettingsRequest = new GetSettingsRequest().indices(INDEX_NAME);
// 设置需要获取的具体参数,不设置则返回所有参数
// getSettingsRequest.names("index.number_of_shards");
// 查看索引请求
GetSettingsResponse getSettingsResponse = restHighLevelClient.indices().getSettings(getSettingsRequest, RequestOptions.DEFAULT);
// 打印所有参数
System.out.println(getSettingsResponse.getIndexToSettings());
// 打印某个参数
System.out.println(getSettingsResponse.getSetting(INDEX_NAME, "index.number_of_shards"));
// 关闭 RestHighLevelClient
restHighLevelClient.close();
}
25.3.1.6 Refresh & Flush
ES 底层依赖 Lucene,而 Lucene 中有 reopen 和 commit 两种操作;Lucene 中还有一个特殊的概念叫做 segment。
ES 中,基本的存储单元是 shard,对应到 Lucene 上,就是一个索引,Lucene 中的索引是由 segment 组成,每个 segment 相当于 ES 中的倒排索引。每个 ES 文档创建时,都会写入到一个新的 segment 中,删除文档时,只是把属于它的 segment 处标记为删除,并没有从磁盘中删除。
Lucene 中:
reopen 可以让数据被搜索到,但不保证数据被持久化到磁盘中。
commit 可以让数据持久化到磁盘中。
ES 中:
默认每秒 refresh 一次(ES 中文档被索引之后,首先添加到内存缓冲区,refresh 操作将内存缓冲区中的数据拷贝到新创建的 segment 中,这里的操作是在内存中进行的)。
flush 将内存中的数据持久化到磁盘中。一般来说,flush 的时间间隔比较久,默认 30 分钟。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
/**
* Refresh & Flush
*/
@SneakyThrows
private static void test06() {
// 创建 RestClientBuilder
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(HOST_NAME, MASTER_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_ONE_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_TWO_PORT, SCHEMA_HTTP_PROTOCOL)
);
// 设置请求头
restClientBuilder.setDefaultHeaders(new Header[]{
new BasicHeader("Content-Type", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept-Charset", CharsetUtil.UTF_8)
});
// 构建一个 RestHighLevelClient 对象
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
RefreshRequest refreshRequest = new RefreshRequest(INDEX_NAME, INDEX_NAME_ALIAS);
restHighLevelClient.indices().refresh(refreshRequest, RequestOptions.DEFAULT);
FlushRequest flushRequest = new FlushRequest(INDEX_NAME, INDEX_NAME_ALIAS);
restHighLevelClient.indices().flush(flushRequest, RequestOptions.DEFAULT);
// 关闭 RestHighLevelClient
restHighLevelClient.close();
}
25.3.2 索引别名
索引的别名类似于 MySQL 中的视图。
25.3.2.1 添加别名
添加普通的别名:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
/**
* 添加普通的别名
*/
@SneakyThrows
private static void test07() {
// 创建 RestClientBuilder
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(HOST_NAME, MASTER_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_ONE_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_TWO_PORT, SCHEMA_HTTP_PROTOCOL)
);
// 设置请求头
restClientBuilder.setDefaultHeaders(new Header[]{
new BasicHeader("Content-Type", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept-Charset", CharsetUtil.UTF_8)
});
// 构建一个 RestHighLevelClient 对象
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
IndicesAliasesRequest indicesAliasesRequest = new IndicesAliasesRequest();
IndicesAliasesRequest.AliasActions aliasAction = new IndicesAliasesRequest.AliasActions(IndicesAliasesRequest.AliasActions.Type.ADD);
aliasAction.index(INDEX_NAME).alias(INDEX_NAME_ALIAS);
indicesAliasesRequest.addAliasAction(aliasAction);
restHighLevelClient.indices().updateAliases(indicesAliasesRequest, RequestOptions.DEFAULT);
// 关闭 RestHighLevelClient
restHighLevelClient.close();
}
添加带 filter 的别名:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
/**
* 添加带 filter 的别名
*/
@SneakyThrows
private static void test08() {
// 创建 RestClientBuilder
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(HOST_NAME, MASTER_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_ONE_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_TWO_PORT, SCHEMA_HTTP_PROTOCOL)
);
// 设置请求头
restClientBuilder.setDefaultHeaders(new Header[]{
new BasicHeader("Content-Type", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept-Charset", CharsetUtil.UTF_8)
});
// 构建一个 RestHighLevelClient 对象
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
IndicesAliasesRequest indicesAliasesRequest = new IndicesAliasesRequest();
IndicesAliasesRequest.AliasActions aliasAction = new IndicesAliasesRequest.AliasActions(IndicesAliasesRequest.AliasActions.Type.ADD);
aliasAction.index(INDEX_NAME).alias(INDEX_NAME_ALIAS_FILTER).filter("{\"term\":{\"name\":{\"value\":\"少年\"}}}");
indicesAliasesRequest.addAliasAction(aliasAction);
restHighLevelClient.indices().updateAliases(indicesAliasesRequest, RequestOptions.DEFAULT);
// 关闭 RestHighLevelClient
restHighLevelClient.close();
}

25.3.2.2 删除别名
ES6 & ES7:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
/**
* 删除别名
*/
@SneakyThrows
private static void test09() {
// 创建 RestClientBuilder
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(HOST_NAME, MASTER_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_ONE_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_TWO_PORT, SCHEMA_HTTP_PROTOCOL)
);
// 设置请求头
restClientBuilder.setDefaultHeaders(new Header[]{
new BasicHeader("Content-Type", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept-Charset", CharsetUtil.UTF_8)
});
// 构建一个 RestHighLevelClient 对象
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
IndicesAliasesRequest indicesAliasesRequest = new IndicesAliasesRequest();
IndicesAliasesRequest.AliasActions aliasAction = new IndicesAliasesRequest.AliasActions(IndicesAliasesRequest.AliasActions.Type.REMOVE);
aliasAction.index(INDEX_NAME).alias(INDEX_NAME_ALIAS_FILTER);
indicesAliasesRequest.addAliasAction(aliasAction);
restHighLevelClient.indices().updateAliases(indicesAliasesRequest, RequestOptions.DEFAULT);
// 关闭 RestHighLevelClient
restHighLevelClient.close();
}
ES7:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
/**
* 删除别名
*/
@SneakyThrows
private static void test09() {
// 创建 RestClientBuilder
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(HOST_NAME, MASTER_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_ONE_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_TWO_PORT, SCHEMA_HTTP_PROTOCOL)
);
// 设置请求头
restClientBuilder.setDefaultHeaders(new Header[]{
new BasicHeader("Content-Type", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept-Charset", CharsetUtil.UTF_8)
});
// 构建一个 RestHighLevelClient 对象
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
DeleteAliasRequest deleteAliasRequest = new DeleteAliasRequest(INDEX_NAME, INDEX_NAME_ALIAS_FILTER);
restHighLevelClient.deleteAlias(deleteAliasRequest, RequestOptions.DEFAULT);
// 关闭 RestHighLevelClient
restHighLevelClient.close();
}
25.3.2.3 判断别名是否存在
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
/**
* 判断别名是否存在
*/
@SneakyThrows
private static void test10() {
// 创建 RestClientBuilder
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(HOST_NAME, MASTER_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_ONE_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_TWO_PORT, SCHEMA_HTTP_PROTOCOL)
);
// 设置请求头
restClientBuilder.setDefaultHeaders(new Header[]{
new BasicHeader("Content-Type", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept-Charset", CharsetUtil.UTF_8)
});
// 构建一个 RestHighLevelClient 对象
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
GetAliasesRequest getAliasesRequest = new GetAliasesRequest(INDEX_NAME_ALIAS);
// 指定查看某一个索引的别名,不指定,则会查看所有的别名
getAliasesRequest.indices(INDEX_NAME);
log.info("别名是否存在:{}", restHighLevelClient.indices().existsAlias(getAliasesRequest, RequestOptions.DEFAULT));
// 关闭 RestHighLevelClient
restHighLevelClient.close();
}
25.3.2.4 获取别名
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
/**
* 获取别名
*/
@SneakyThrows
private static void test11() {
// 创建 RestClientBuilder
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(HOST_NAME, MASTER_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_ONE_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_TWO_PORT, SCHEMA_HTTP_PROTOCOL)
);
// 设置请求头
restClientBuilder.setDefaultHeaders(new Header[]{
new BasicHeader("Content-Type", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept-Charset", CharsetUtil.UTF_8)
});
// 构建一个 RestHighLevelClient 对象
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
GetAliasesRequest getAliasesRequest = new GetAliasesRequest(INDEX_NAME_ALIAS);
// 指定查看某一个索引的别名,不指定,则会查看所有的别名
getAliasesRequest.indices(INDEX_NAME);
GetAliasesResponse getAliasesResponse = restHighLevelClient.indices().getAlias(getAliasesRequest, RequestOptions.DEFAULT);
Map<String, Set<AliasMetaData>> aliases = getAliasesResponse.getAliases();
log.info("别名:{}", aliases.toString().replaceAll("\\s", StrUtil.EMPTY));
// 关闭 RestHighLevelClient
restHighLevelClient.close();
}
25.3.3 文档管理
25.3.3.1 添加文档
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
/**
* 添加文档
*/
@SneakyThrows
private static void test12() {
// 创建 RestClientBuilder
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(HOST_NAME, MASTER_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_ONE_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_TWO_PORT, SCHEMA_HTTP_PROTOCOL)
);
// 设置请求头
restClientBuilder.setDefaultHeaders(new Header[]{
new BasicHeader("Content-Type", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept-Charset", CharsetUtil.UTF_8)
});
// 构建一个 RestHighLevelClient 对象
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
// 构建一个参数是索引名称的 IndexRequest 请求
IndexRequest indexRequest = new IndexRequest(INDEX_NAME);
// 配置类型;在 ES6 中,必须配置类型;在 ES7 中,可以不用配置类型
indexRequest.type("_doc");
// 配置文档 ID,如果配置 ID,相当于 PUT novel/_doc/{id};如果不配置 ID,相当于 POST novel/_doc
indexRequest.id("1");
// 构建文档
indexRequest.source("{\"name\":\"少年歌行\",\"author\":\"周木楠\"}", XContentType.JSON);
// 同步请求
IndexResponse indexResponse = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
log.info("文档 ID:{}", indexResponse.getId());
log.info("索引名称:{}", indexResponse.getIndex());
if (indexResponse.getResult() == DocWriteResponse.Result.CREATED) {
log.info("文档添加成功");
}
if (indexResponse.getResult() == DocWriteResponse.Result.UPDATED) {
log.info("文档更新成功");
}
ReplicationResponse.ShardInfo shardInfo = indexResponse.getShardInfo();
if (shardInfo.getTotal() != shardInfo.getSuccessful()) {
log.info("存在有问题的分片");
}
if (shardInfo.getFailed() > 0) {
for (ReplicationResponse.ShardInfo.Failure failure : shardInfo.getFailures()) {
log.info("分片失败原因:{}", failure.reason());
}
}
// 关闭 RestHighLevelClient
restHighLevelClient.close();
}
构建文档的三种方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// 构建文档
indexRequest.source("{\"name\":\"少年歌行\",\"author\":\"周木楠\"}", XContentType.JSON);
Map<String, Object> map = new HashMap<>();
map.put("name", "少年歌行");
map.put("author", "周木楠");
indexRequest.source(map);
XContentBuilder jsonBuilder = XContentFactory.jsonBuilder();
jsonBuilder.startObject();
jsonBuilder.field("name", "少年歌行");
jsonBuilder.field("author", "周木楠");
jsonBuilder.endObject();
indexRequest.source(jsonBuilder);
直接指定操作:
例如:如果 ID 已经存在,默认是编辑操作,如果指定为新增操作,此请求就会报错;
此操作可用于遍历新增 ID 不存在的文档,并不能修改已有 ID 的文档;
1
indexRequest.opType(DocWriteRequest.OpType.CREATE);
25.3.3.2 获取文档
根据 ID 获取文档:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
/**
* 获取文档
*/
@SneakyThrows
private static void test13() {
// 创建 RestClientBuilder
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(HOST_NAME, MASTER_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_ONE_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_TWO_PORT, SCHEMA_HTTP_PROTOCOL)
);
// 设置请求头
restClientBuilder.setDefaultHeaders(new Header[]{
new BasicHeader("Content-Type", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept-Charset", CharsetUtil.UTF_8)
});
// 构建一个 RestHighLevelClient 对象
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
GetRequest getRequest = new GetRequest(INDEX_NAME, "_doc", "1");
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
if (getResponse.isExists()) {
log.info("文档 ID:{}", getResponse.getId());
log.info("索引名称:{}", getResponse.getIndex());
log.info("文档版本:{}", getResponse.getVersion());
log.info("索引名称:{}", getResponse.getSourceAsString());
}
// 关闭 RestHighLevelClient
restHighLevelClient.close();
}
5.3.3.3 判断文档是否存在
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
/**
* 判断文档是否存在
*/
@SneakyThrows
private static void test14() {
// 创建 RestClientBuilder
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(HOST_NAME, MASTER_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_ONE_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_TWO_PORT, SCHEMA_HTTP_PROTOCOL)
);
// 设置请求头
restClientBuilder.setDefaultHeaders(new Header[]{
new BasicHeader("Content-Type", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept-Charset", CharsetUtil.UTF_8)
});
// 构建一个 RestHighLevelClient 对象
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
GetRequest getRequest = new GetRequest(INDEX_NAME, "_doc", "1");
getRequest.fetchSourceContext(new FetchSourceContext(false));
log.info("文档是否存在:{}", restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT));
// 关闭 RestHighLevelClient
restHighLevelClient.close();
}
5.3.3.4 删除文档
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
/**
* 删除文档
*/
@SneakyThrows
private static void test15() {
// 创建 RestClientBuilder
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(HOST_NAME, MASTER_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_ONE_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_TWO_PORT, SCHEMA_HTTP_PROTOCOL)
);
// 设置请求头
restClientBuilder.setDefaultHeaders(new Header[]{
new BasicHeader("Content-Type", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept-Charset", CharsetUtil.UTF_8)
});
// 构建一个 RestHighLevelClient 对象
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
DeleteRequest deleteRequest = new DeleteRequest(INDEX_NAME, "_doc", "1");
DeleteResponse deleteResponse = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
log.info("文档 ID:{}", deleteResponse.getId());
log.info("索引名称:{}", deleteResponse.getIndex());
log.info("文档版本:{}", deleteResponse.getVersion());
ReplicationResponse.ShardInfo shardInfo = deleteResponse.getShardInfo();
if (shardInfo.getTotal() != shardInfo.getSuccessful()) {
log.info("存在有问题的分片");
}
if (shardInfo.getFailed() > 0) {
for (ReplicationResponse.ShardInfo.Failure failure : shardInfo.getFailures()) {
log.info("分片失败原因:{}", failure.reason());
}
}
// 关闭 RestHighLevelClient
restHighLevelClient.close();
}
5.3.3.5 更新文档
通过脚本更新:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
/**
* 更新文档-通过脚本更新
*/
@SneakyThrows
private static void test16() {
// 创建 RestClientBuilder
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(HOST_NAME, MASTER_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_ONE_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_TWO_PORT, SCHEMA_HTTP_PROTOCOL)
);
// 设置请求头
restClientBuilder.setDefaultHeaders(new Header[]{
new BasicHeader("Content-Type", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept-Charset", CharsetUtil.UTF_8)
});
// 构建一个 RestHighLevelClient 对象
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
UpdateRequest updateRequest = new UpdateRequest(INDEX_NAME, "_doc", "1");
// 通过脚本更新
Map<String, Object> params = Collections.singletonMap("name", "自从遇见你");
Script script = new Script(ScriptType.INLINE, "painless", "ctx._source.name=params.name", params);
updateRequest.script(script);
UpdateResponse updateResponse = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
log.info("文档 ID:{}", updateResponse.getId());
log.info("索引名称:{}", updateResponse.getIndex());
log.info("文档版本:{}", updateResponse.getVersion());
if (updateResponse.getResult() == DocWriteResponse.Result.UPDATED) {
log.info("文档更新成功");
}
// 关闭 RestHighLevelClient
restHighLevelClient.close();
}
通过 JSON 更新:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
/**
* 更新文档-通过 JSON 更新
*/
@SneakyThrows
private static void test17() {
// 创建 RestClientBuilder
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(HOST_NAME, MASTER_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_ONE_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_TWO_PORT, SCHEMA_HTTP_PROTOCOL)
);
// 设置请求头
restClientBuilder.setDefaultHeaders(new Header[]{
new BasicHeader("Content-Type", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept-Charset", CharsetUtil.UTF_8)
});
// 构建一个 RestHighLevelClient 对象
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
UpdateRequest updateRequest = new UpdateRequest(INDEX_NAME, "_doc", "1");
// 通过 JSON 更新
updateRequest.doc("{\"name\":\"少年歌行\"}", XContentType.JSON);
UpdateResponse updateResponse = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
log.info("文档 ID:{}", updateResponse.getId());
log.info("索引名称:{}", updateResponse.getIndex());
log.info("文档版本:{}", updateResponse.getVersion());
if (updateResponse.getResult() == DocWriteResponse.Result.UPDATED) {
log.info("文档更新成功");
}
// 关闭 RestHighLevelClient
restHighLevelClient.close();
}
通过 Map 更新:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
/**
* 更新文档-通过 Map 更新
*/
@SneakyThrows
private static void test18() {
// 创建 RestClientBuilder
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(HOST_NAME, MASTER_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_ONE_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_TWO_PORT, SCHEMA_HTTP_PROTOCOL)
);
// 设置请求头
restClientBuilder.setDefaultHeaders(new Header[]{
new BasicHeader("Content-Type", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept-Charset", CharsetUtil.UTF_8)
});
// 构建一个 RestHighLevelClient 对象
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
UpdateRequest updateRequest = new UpdateRequest(INDEX_NAME, "_doc", "1");
// 通过 Map 更新
Map<String, Object> map = Collections.singletonMap("name", "自从遇见你");
updateRequest.doc(map);
UpdateResponse updateResponse = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
log.info("文档 ID:{}", updateResponse.getId());
log.info("索引名称:{}", updateResponse.getIndex());
log.info("文档版本:{}", updateResponse.getVersion());
if (updateResponse.getResult() == DocWriteResponse.Result.UPDATED) {
log.info("文档更新成功");
}
// 关闭 RestHighLevelClient
restHighLevelClient.close();
}
通过 XContentBuilder 更新:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
/**
* 更新文档-通过 XContentBuilder 更新
*/
@SneakyThrows
private static void test19() {
// 创建 RestClientBuilder
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(HOST_NAME, MASTER_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_ONE_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_TWO_PORT, SCHEMA_HTTP_PROTOCOL)
);
// 设置请求头
restClientBuilder.setDefaultHeaders(new Header[]{
new BasicHeader("Content-Type", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept-Charset", CharsetUtil.UTF_8)
});
// 构建一个 RestHighLevelClient 对象
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
UpdateRequest updateRequest = new UpdateRequest(INDEX_NAME, "_doc", "1");
// 通过 Map 更新
XContentBuilder jsonBuilder = XContentFactory.jsonBuilder();
jsonBuilder.startObject();
jsonBuilder.field("name", "少年歌行");
jsonBuilder.endObject();
updateRequest.doc(jsonBuilder);
UpdateResponse updateResponse = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
log.info("文档 ID:{}", updateResponse.getId());
log.info("索引名称:{}", updateResponse.getIndex());
log.info("文档版本:{}", updateResponse.getVersion());
if (updateResponse.getResult() == DocWriteResponse.Result.UPDATED) {
log.info("文档更新成功");
}
// 关闭 RestHighLevelClient
restHighLevelClient.close();
}
文档不存在时添加文档:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
/**
* 更新文档-文档不存在时添加文档
*/
@SneakyThrows
private static void test20() {
// 创建 RestClientBuilder
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost(HOST_NAME, MASTER_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_ONE_PORT, SCHEMA_HTTP_PROTOCOL),
new HttpHost(HOST_NAME, SALVE_TWO_PORT, SCHEMA_HTTP_PROTOCOL)
);
// 设置请求头
restClientBuilder.setDefaultHeaders(new Header[]{
new BasicHeader("Content-Type", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept", MediaType.APPLICATION_JSON_VALUE),
new BasicHeader("Accept-Charset", CharsetUtil.UTF_8)
});
// 构建一个 RestHighLevelClient 对象
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
UpdateRequest updateRequest = new UpdateRequest(INDEX_NAME, "_doc", "2");
updateRequest.doc("{\"name\":\"燕倾天下\",\"author\":\"天下归元\"}", XContentType.JSON);
updateRequest.upsert("{\"name\":\"燕倾天下\",\"author\":\"天下归元\"}", XContentType.JSON);
UpdateResponse updateResponse = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
log.info("文档 ID:{}", updateResponse.getId());
log.info("索引名称:{}", updateResponse.getIndex());
log.info("文档版本:{}", updateResponse.getVersion());
if (updateResponse.getResult() == DocWriteResponse.Result.UPDATED) {
log.info("文档更新成功");
} else if (updateResponse.getResult() == DocWriteResponse.Result.CREATED) {
log.info("文档添加成功");
}
// 关闭 RestHighLevelClient
restHighLevelClient.close();
}
-
聚合:在搜索数据的基础上进行的数据分析操作。它可以对搜索结果进行分组、排序、过滤和计算,从而得出具有统计意义的结果。 ↩